 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-Policy Meta-Reinforcement Learning Based on Feature Embedding Spaces
Paper and Code
Jan 06, 2021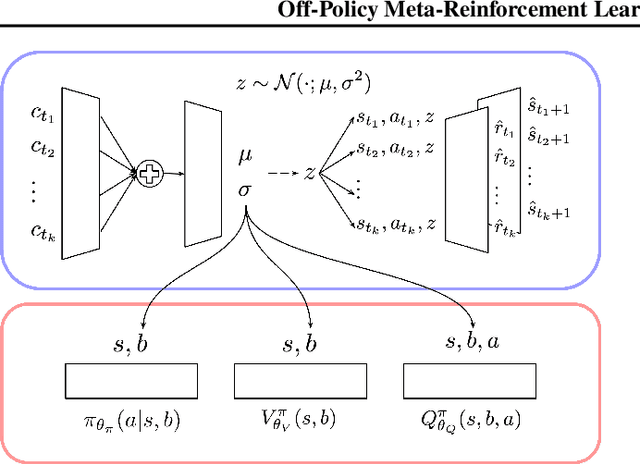
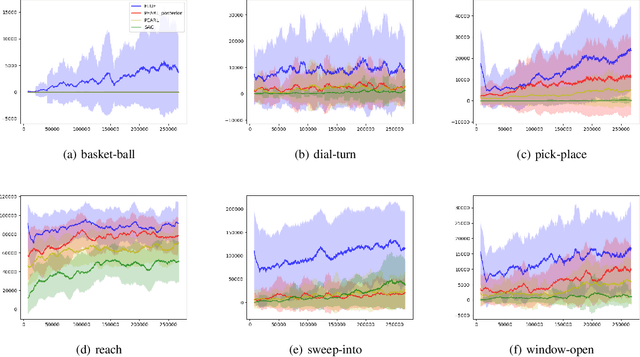
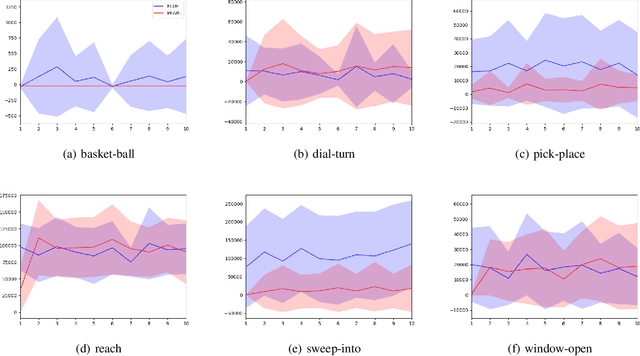
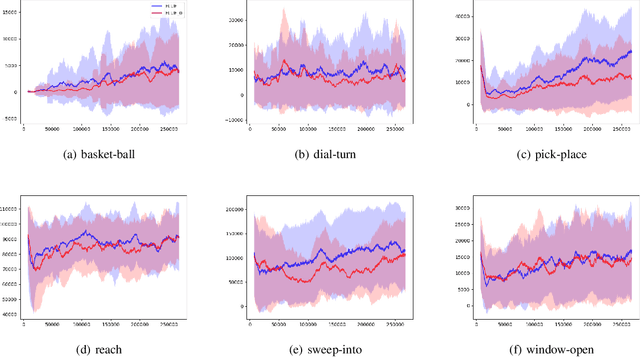
Meta-reinforcement learning (RL) addresses the problem of sample inefficiency in deep RL by using experience obtained in past tasks for a new task to be solved. However, most meta-RL methods require partially or fully on-policy data, i.e., they cannot reuse the data collected by past policies, which hinders the improvement of sample efficiency. To alleviate this problem, we propose a novel off-policy meta-RL method, embedding learning and evaluation of uncertainty (ELUE). An ELUE agent is characterized by the learning of a feature embedding space shared among tasks. It learns a belief model over the embedding space and a belief-conditional policy and Q-function. Then, for a new task, it collects data by the pretrained policy, and updates its belief based on the belief model. Thanks to the belief update, the performance can be improved with a small amount of data. In addition, it updates the parameters of the neural networks to adjust the pretrained relationships when there are enough data. We demonstrate that ELUE outperforms state-of-the-art meta RL methods through experiments on meta-RL benchmarks.