 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Robust Options by Conditional Value at Risk Optimization
Paper and Code
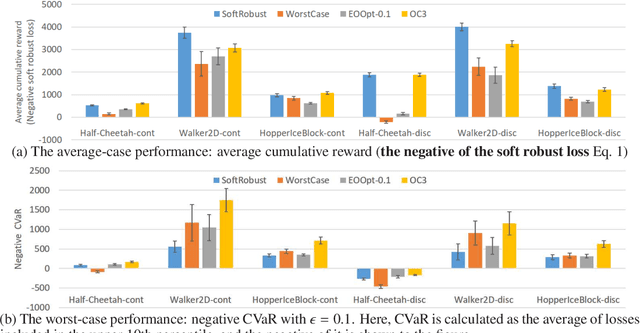
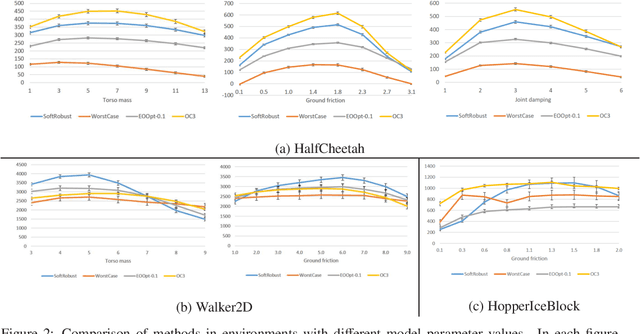
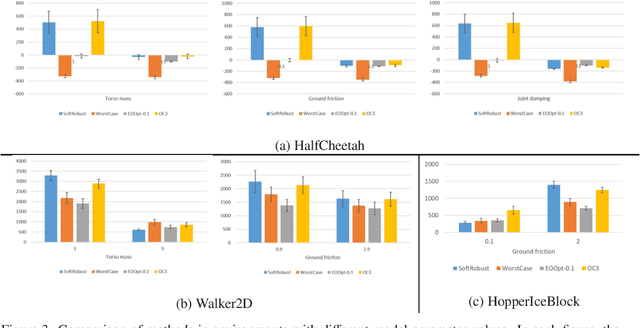
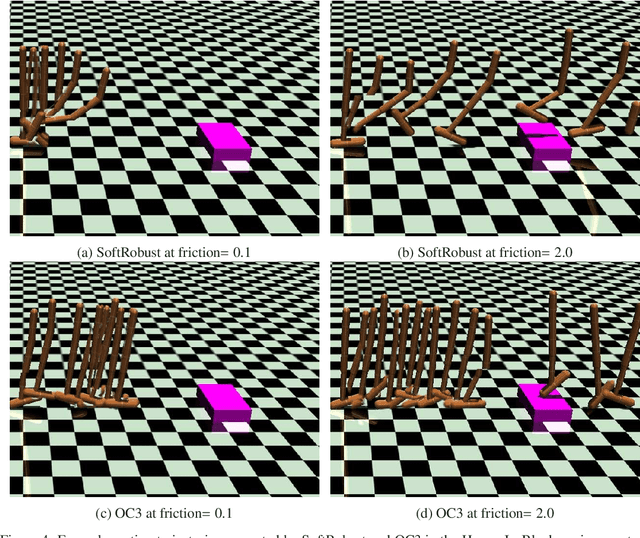
Options are generally learned by using an inaccurate environment model (or simulator), which contains uncertain model parameters. While there are several methods to learn options that are robust against the uncertainty of model parameters, these methods only consider either the worst case or the average (ordinary) case for learning options. This limited consideration of the cases often produces options that do not work well in the unconsidered case. In this paper, we propose a conditional value at risk (CVaR)-based method to learn options that work well in both the average and worst cases. We extend the CVaR-based policy gradient method proposed by Chow and Ghavamzadeh (2014) to deal with robust Markov decision processes and then apply the extended method to learning robust options. We conduct experiments to evaluate our method in multi-joint robot control tasks (HopperIceBlock, Half-Cheetah, and Walker2D). Experimental results show that our method produces options that 1) give better worst-case performance than the options learned only to minimize the average-case loss, and 2) give better average-case performance than the options learned only to minimize the worst-case loss.