 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrapped by Their Own Light: Deployable and Stealth Retroreflective Patch Attacks on Traffic Sign Recognition Systems
Nov 13, 2025Traffic sign recognition plays a critical role in ensuring safe and efficient transportation of autonomous vehicles but remain vulnerable to adversarial attacks using stickers or laser projections. While existing attack vectors demonstrate security concerns, they suffer from visual detectability or implementation constraints, suggesting unexplored vulnerability surfaces in TSR systems. We introduce the Adversarial Retroreflective Patch (ARP), a novel attack vector that combines the high deployability of patch attacks with the stealthiness of laser projections by utilizing retroreflective materials activated only under victim headlight illumination. We develop a retroreflection simulation method and employ black-box optimization to maximize attack effectiveness. ARP achieves $\geq$93.4\% success rate in dynamic scenarios at 35 meters and $\geq$60\% success rate against commercial TSR systems in real-world conditions. Our user study demonstrates that ARP attacks maintain near-identical stealthiness to benign signs while achieving $\geq$1.9\% higher stealthiness scores than previous patch attacks. We propose the DPR Shield defense, employing strategically placed polarized filters, which achieves $\geq$75\% defense success rates for stop signs and speed limit signs against micro-prism patches.
Application of Adversarial Examples to Physical ECG Signals
Aug 20, 2021

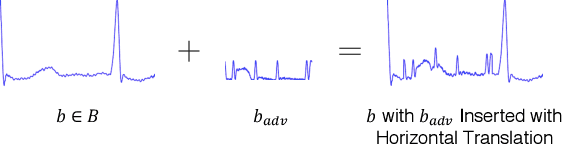

This work aims to assess the reality and feasibility of the adversarial attack against cardiac diagnosis system powered by machine learning algorithms. To this end, we introduce adversarial beats, which are adversarial perturbations tailored specifically against electrocardiograms (ECGs) beat-by-beat classification system. We first formulate an algorithm to generate adversarial examples for the ECG classification neural network model, and study its attack success rate. Next, to evaluate its feasibility in a physical environment, we mount a hardware attack by designing a malicious signal generator which injects adversarial beats into ECG sensor readings. To the best of our knowledge, our work is the first in evaluating the proficiency of adversarial examples for ECGs in a physical setup. Our real-world experiments demonstrate that adversarial beats successfully manipulated the diagnosis results 3-5 times out of 40 attempts throughout the course of 2 minutes. Finally, we discuss the overall feasibility and impact of the attack, by clearly defining motives and constraints of expected attackers along with our experimental results.
Learning Robust Options by Conditional Value at Risk Optimization
Jun 11, 2019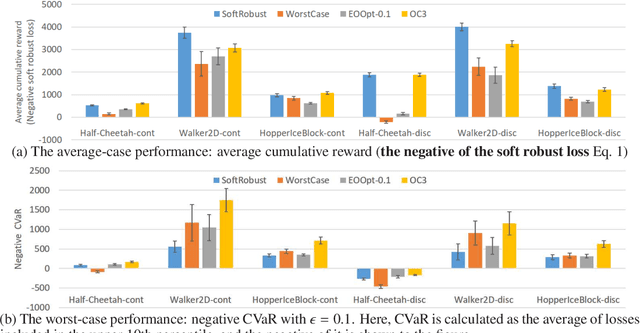
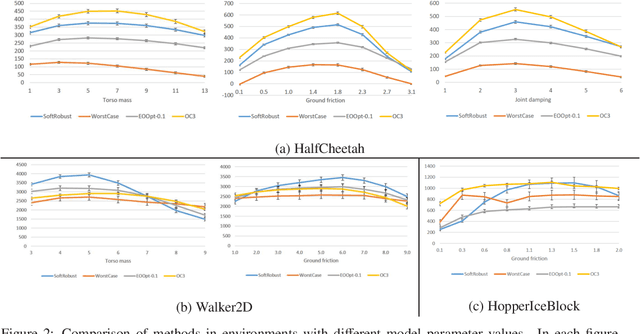
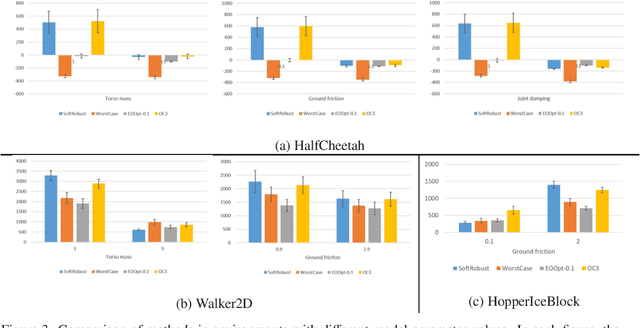
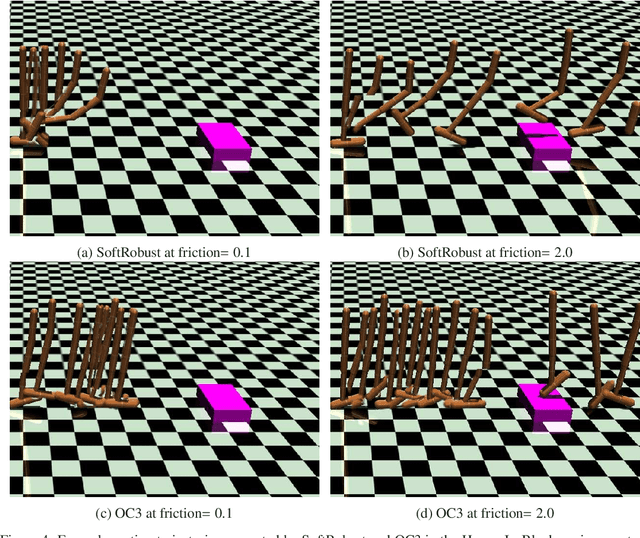
Options are generally learned by using an inaccurate environment model (or simulator), which contains uncertain model parameters. While there are several methods to learn options that are robust against the uncertainty of model parameters, these methods only consider either the worst case or the average (ordinary) case for learning options. This limited consideration of the cases often produces options that do not work well in the unconsidered case. In this paper, we propose a conditional value at risk (CVaR)-based method to learn options that work well in both the average and worst cases. We extend the CVaR-based policy gradient method proposed by Chow and Ghavamzadeh (2014) to deal with robust Markov decision processes and then apply the extended method to learning robust options. We conduct experiments to evaluate our method in multi-joint robot control tasks (HopperIceBlock, Half-Cheetah, and Walker2D). Experimental results show that our method produces options that 1) give better worst-case performance than the options learned only to minimize the average-case loss, and 2) give better average-case performance than the options learned only to minimize the worst-case loss.
Stay On-Topic: Generating Context-specific Fake Restaurant Reviews
Jun 28, 2018

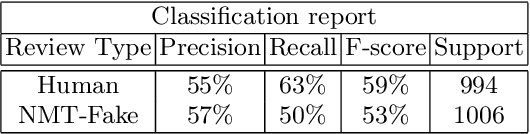
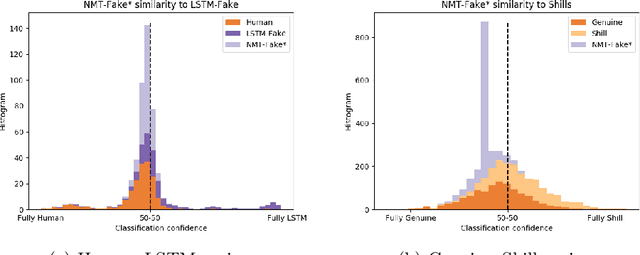
Automatically generated fake restaurant reviews are a threat to online review systems. Recent research has shown that users have difficulties in detecting machine-generated fake reviews hiding among real restaurant reviews. The method used in this work (char-LSTM ) has one drawback: it has difficulties staying in context, i.e. when it generates a review for specific target entity, the resulting review may contain phrases that are unrelated to the target, thus increasing its detectability. In this work, we present and evaluate a more sophisticated technique based on neural machine translation (NMT) with which we can generate reviews that stay on-topic. We test multiple variants of our technique using native English speakers on Amazon Mechanical Turk. We demonstrate that reviews generated by the best variant have almost optimal undetectability (class-averaged F-score 47%). We conduct a user study with skeptical users and show that our method evades detection more frequently compared to the state-of-the-art (average evasion 3.2/4 vs 1.5/4) with statistical significance, at level {\alpha} = 1% (Section 4.3). We develop very effective detection tools and reach average F-score of 97% in classifying these. Although fake reviews are very effective in fooling people, effective automatic detection is still feasible.