 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich Experiences Are Influential for RL Agents? Efficiently Estimating The Influence of Experiences
May 23, 2024



In reinforcement learning (RL) with experience replay, experiences stored in a replay buffer influence the RL agent's performance. Information about the influence of these experiences is valuable for various purposes, such as identifying experiences that negatively influence poorly performing RL agents. One method for estimating the influence of experiences is the leave-one-out (LOO) method. However, this method is usually computationally prohibitive. In this paper, we present Policy Iteration with Turn-over Dropout (PIToD), which efficiently estimates the influence of experiences. We evaluate how accurately PIToD estimates the influence of experiences and its efficiency compared to LOO. We then apply PIToD to amend poorly performing RL agents, i.e., we use PIToD to estimate negatively influential experiences for the RL agents and to delete the influence of these experiences. We show that RL agents' performance is significantly improved via amendments with PIToD.
Which Experiences Are Influential for Your Agent? Policy Iteration with Turn-over Dropout
Jan 26, 2023



In reinforcement learning (RL) with experience replay, experiences stored in a replay buffer influence the RL agent's performance. Information about the influence is valuable for various purposes, including experience cleansing and analysis. One method for estimating the influence of individual experiences is agent comparison, but it is prohibitively expensive when there is a large number of experiences. In this paper, we present PI+ToD as a method for efficiently estimating the influence of experiences. PI+ToD is a policy iteration that efficiently estimates the influence of experiences by utilizing turn-over dropout. We demonstrate the efficiency of PI+ToD with experiments in MuJoCo environments.
Soft Sensors and Process Control using AI and Dynamic Simulation
Aug 08, 2022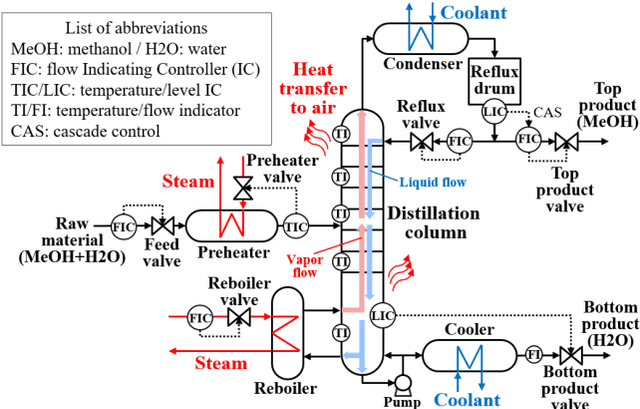
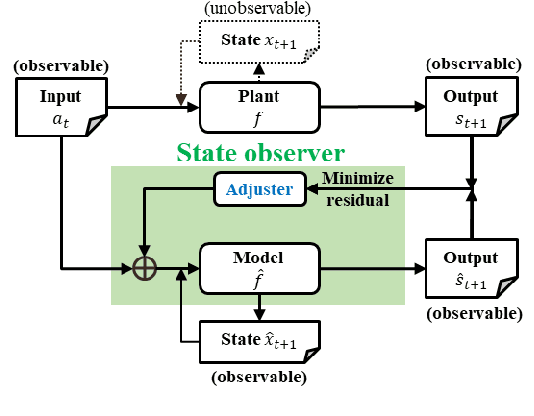
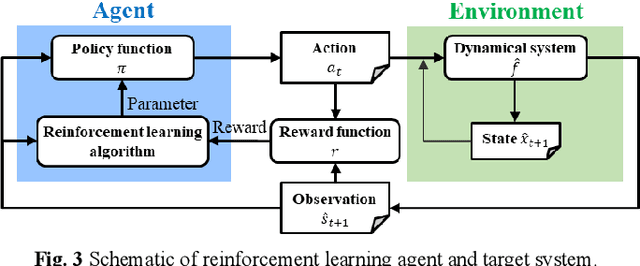
During the operation of a chemical plant, product quality must be consistently maintained, and the production of off-specification products should be minimized. Accordingly, process variables related to the product quality, such as the temperature and composition of materials at various parts of the plant must be measured, and appropriate operations (that is, control) must be performed based on the measurements. Some process variables, such as temperature and flow rate, can be measured continuously and instantaneously. However, other variables, such as composition and viscosity, can only be obtained through time-consuming analysis after sampling substances from the plant. Soft sensors have been proposed for estimating process variables that cannot be obtained in real time from easily measurable variables. However, the estimation accuracy of conventional statistical soft sensors, which are constructed from recorded measurements, can be very poor in unrecorded situations (extrapolation). In this study, we estimate the internal state variables of a plant by using a dynamic simulator that can estimate and predict even unrecorded situations on the basis of chemical engineering knowledge and an artificial intelligence (AI) technology called reinforcement learning, and propose to use the estimated internal state variables of a plant as soft sensors. In addition, we describe the prospects for plant operation and control using such soft sensors and the methodology to obtain the necessary prediction models (i.e., simulators) for the proposed system.
* This is an English version of the research paper in Japanese translated by the original authors. The original paper is published in Kagaku Kogaku Ronbunsyu by the Society of Chemical Engineers, Japan (SCEJ) on July 20th, 2022 (DOI: 10.1252/kakoronbunshu.48.141)
Railway Operation Rescheduling System via Dynamic Simulation and Reinforcement Learning
Jan 17, 2022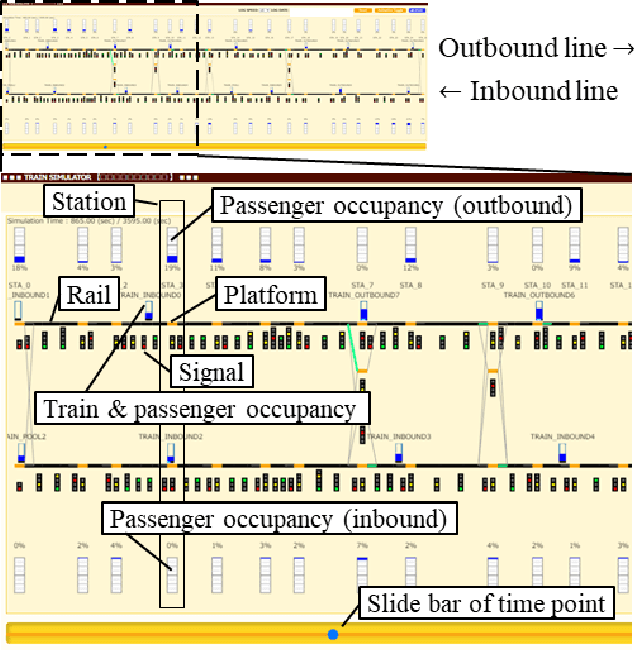
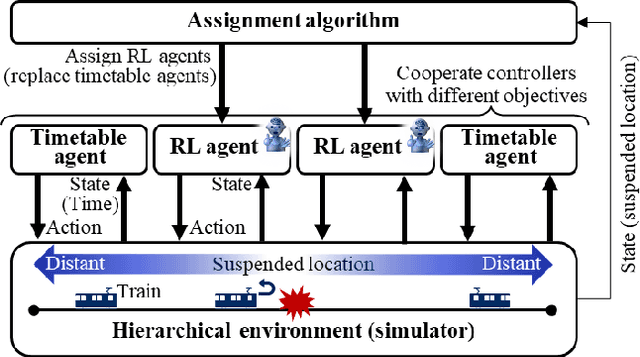
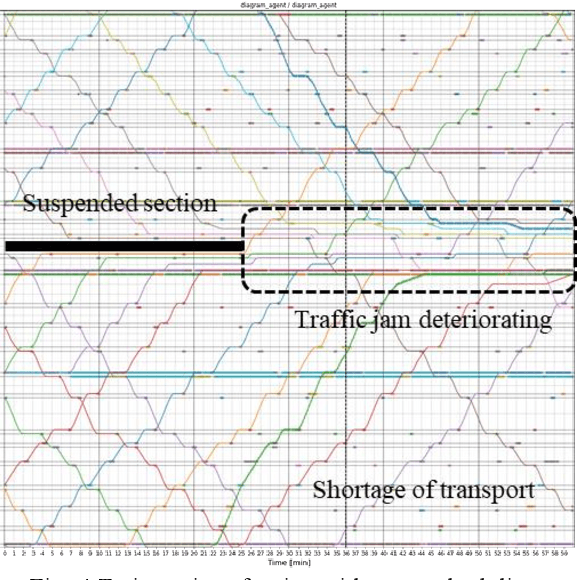
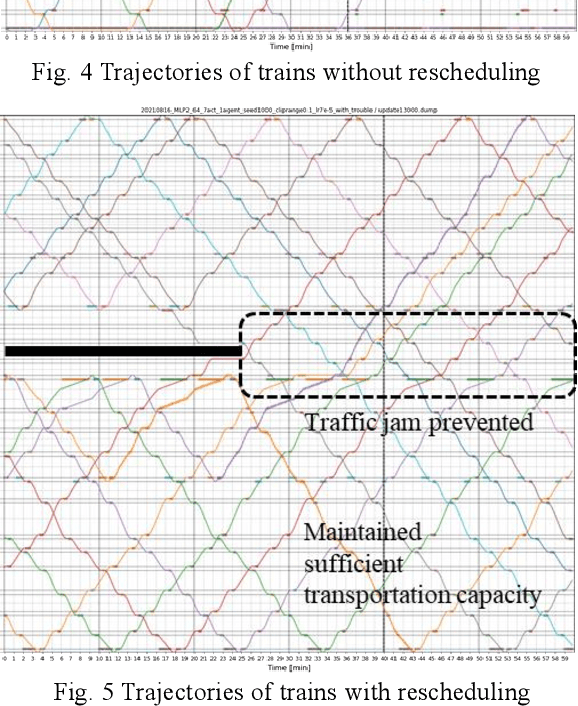
The number of railway service disruptions has been increasing owing to intensification of natural disasters. In addition, abrupt changes in social situations such as the COVID-19 pandemic require railway companies to modify the traffic schedule frequently. Therefore, automatic support for optimal scheduling is anticipated. In this study, an automatic railway scheduling system is presented. The system leverages reinforcement learning and a dynamic simulator that can simulate the railway traffic and passenger flow of a whole line. The proposed system enables rapid generation of the traffic schedule of a whole line because the optimization process is conducted in advance as the training. The system is evaluated using an interruption scenario, and the results demonstrate that the system can generate optimized schedules of the whole line in a few minutes.
Dropout Q-Functions for Doubly Efficient Reinforcement Learning
Oct 05, 2021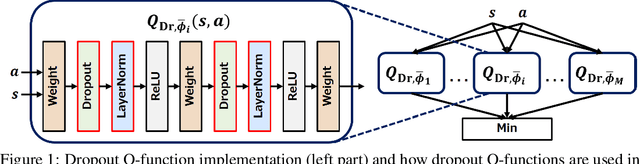
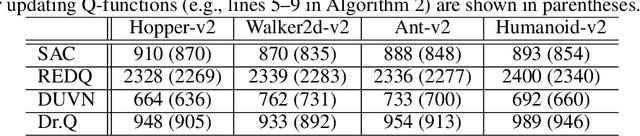
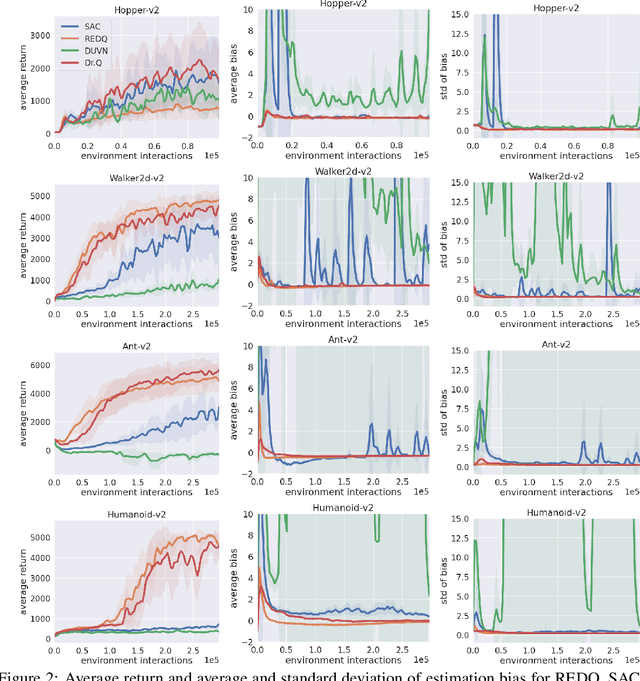
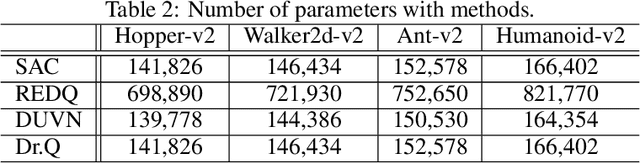
Randomized ensemble double Q-learning (REDQ) has recently achieved state-of-the-art sample efficiency on continuous-action reinforcement learning benchmarks. This superior sample efficiency is possible by using a large Q-function ensemble. However, REDQ is much less computationally efficient than non-ensemble counterparts such as Soft Actor-Critic (SAC). To make REDQ more computationally efficient, we propose a method of improving computational efficiency called Dr.Q, which is a variant of REDQ that uses a small ensemble of dropout Q-functions. Our dropout Q-functions are simple Q-functions equipped with dropout connection and layer normalization. Despite its simplicity of implementation, our experimental results indicate that Dr.Q is doubly (sample and computationally) efficient. It achieved comparable sample efficiency with REDQ and much better computational efficiency than REDQ and comparable computational efficiency with that of SAC.
Meta-Model-Based Meta-Policy Optimization
Jun 05, 2020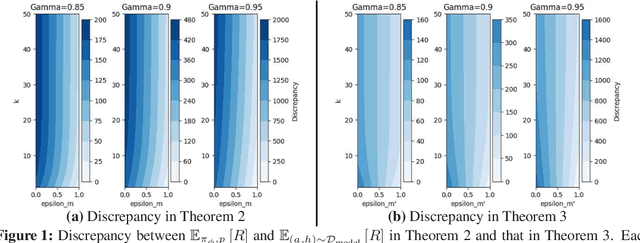
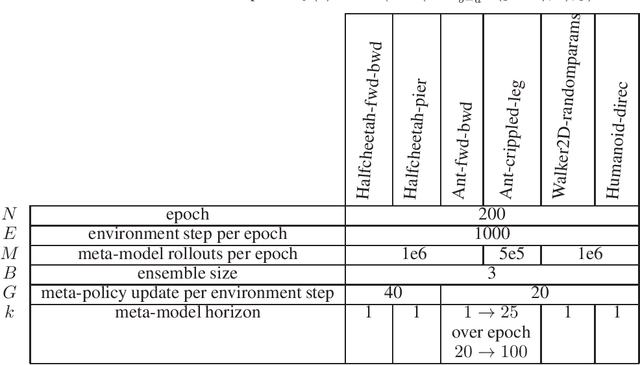
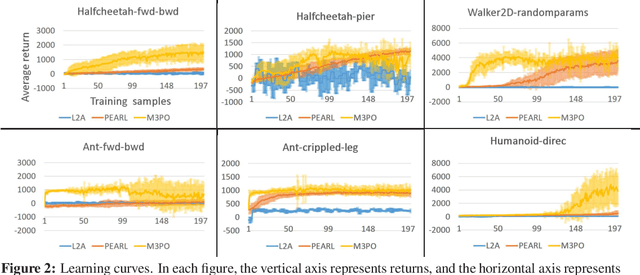
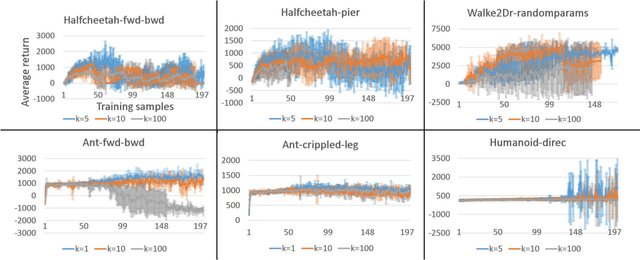
Model-based reinforcement learning (MBRL) has been applied to meta-learning settings and demonstrated its high sample efficiency. However, in previous MBRL for meta-learning settings, policies are optimized via rollouts that fully rely on a predictive model for an environment, and thus its performance in a real environment tends to degrade when the predictive model is inaccurate. In this paper, we prove that the performance degradation can be suppressed by using branched meta-rollouts. Based on this theoretical analysis, we propose meta-model-based meta-policy optimization (M3PO), in which the branched meta-rollouts are used for policy optimization. We demonstrate that M3PO outperforms existing meta reinforcement learning methods in continuous-control benchmarks.
Learning Robust Options by Conditional Value at Risk Optimization
Jun 11, 2019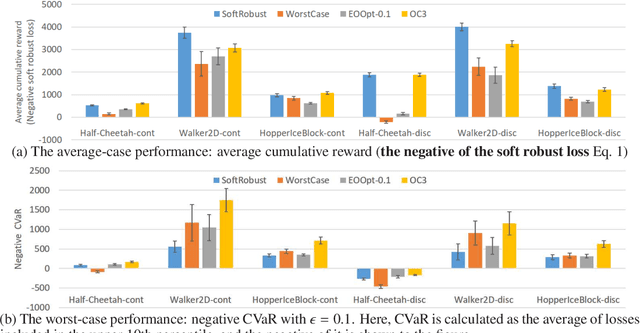
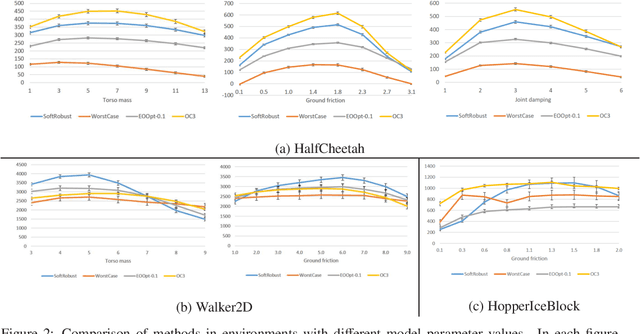
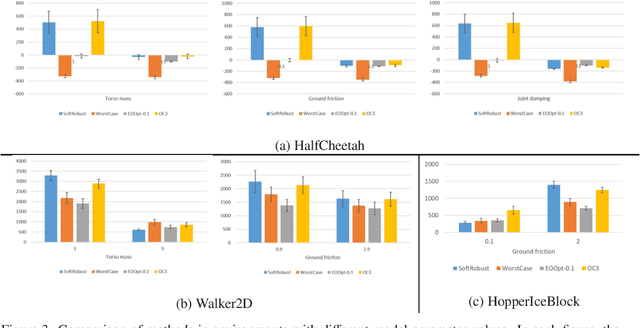
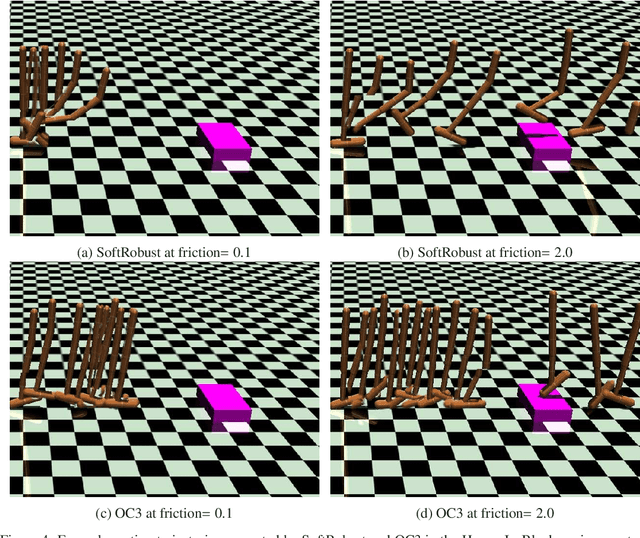
Options are generally learned by using an inaccurate environment model (or simulator), which contains uncertain model parameters. While there are several methods to learn options that are robust against the uncertainty of model parameters, these methods only consider either the worst case or the average (ordinary) case for learning options. This limited consideration of the cases often produces options that do not work well in the unconsidered case. In this paper, we propose a conditional value at risk (CVaR)-based method to learn options that work well in both the average and worst cases. We extend the CVaR-based policy gradient method proposed by Chow and Ghavamzadeh (2014) to deal with robust Markov decision processes and then apply the extended method to learning robust options. We conduct experiments to evaluate our method in multi-joint robot control tasks (HopperIceBlock, Half-Cheetah, and Walker2D). Experimental results show that our method produces options that 1) give better worst-case performance than the options learned only to minimize the average-case loss, and 2) give better average-case performance than the options learned only to minimize the worst-case loss.
Synthesizing Chemical Plant Operation Procedures using Knowledge, Dynamic Simulation and Deep Reinforcement Learning
Mar 06, 2019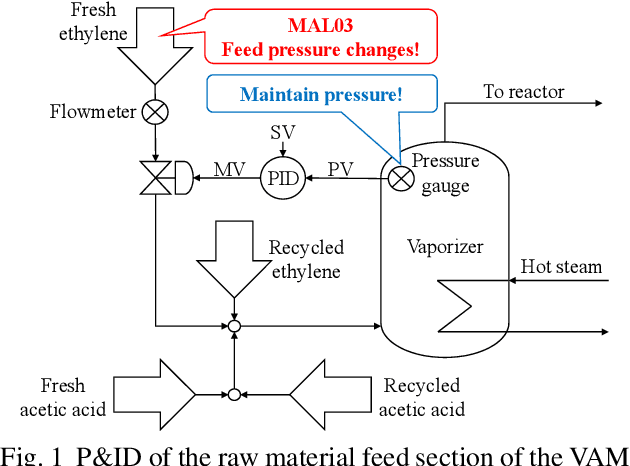

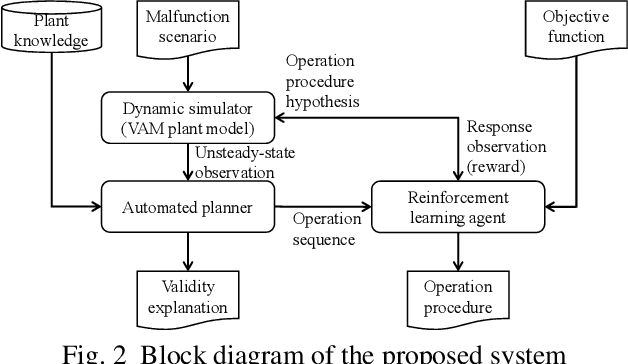
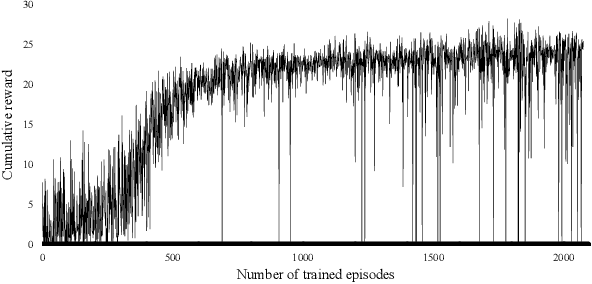
Chemical plants are complex and dynamical systems consisting of many components for manipulation and sensing, whose state transitions depend on various factors such as time, disturbance, and operation procedures. For the purpose of supporting human operators of chemical plants, we are developing an AI system that can semi-automatically synthesize operation procedures for efficient and stable operation. Our system can provide not only appropriate operation procedures but also reasons why the procedures are considered to be valid. This is achieved by integrating automated reasoning and deep reinforcement learning technologies with a chemical plant simulator and external knowledge. Our preliminary experimental results demonstrate that it can synthesize a procedure that achieves a much faster recovery from a malfunction compared to standard PID control.
Refining Manually-Designed Symbol Grounding and High-Level Planning by Policy Gradients
Sep 29, 2018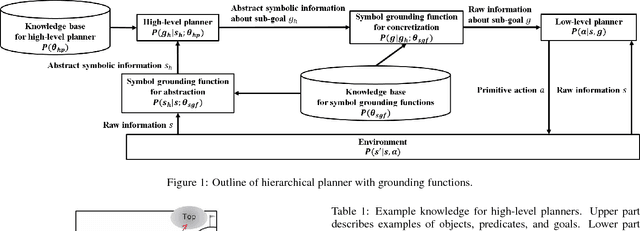
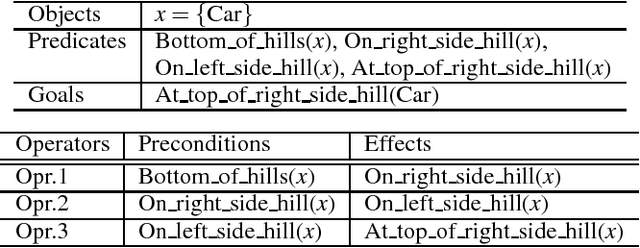

Hierarchical planners that produce interpretable and appropriate plans are desired, especially in its application to supporting human decision making. In the typical development of the hierarchical planners, higher-level planners and symbol grounding functions are manually created, and this manual creation requires much human effort. In this paper, we propose a framework that can automatically refine symbol grounding functions and a high-level planner to reduce human effort for designing these modules. In our framework, symbol grounding and high-level planning, which are based on manually-designed knowledge bases, are modeled with semi-Markov decision processes. A policy gradient method is then applied to refine the modules, in which two terms for updating the modules are considered. The first term, called a reinforcement term, contributes to updating the modules to improve the overall performance of a hierarchical planner to produce appropriate plans. The second term, called a penalty term, contributes to keeping refined modules consistent with the manually-designed original modules. Namely, it keeps the planner, which uses the refined modules, producing interpretable plans. We perform preliminary experiments to solve the Mountain car problem, and its results show that a manually-designed high-level planner and symbol grounding function were successfully refined by our framework.
Monte Carlo Tree Search with Scalable Simulation Periods for Continuously Running Tasks
Sep 07, 2018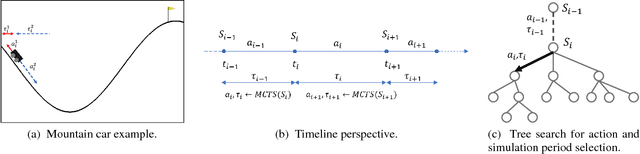
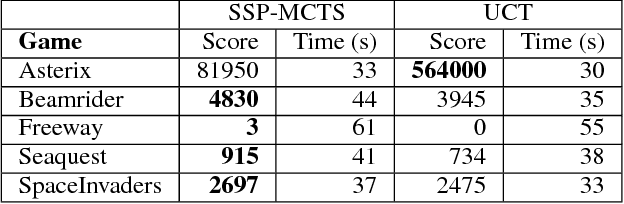
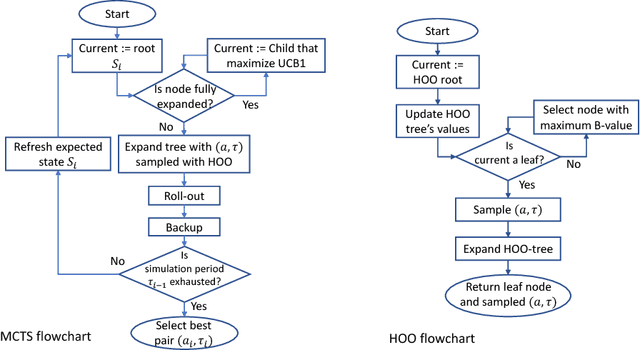
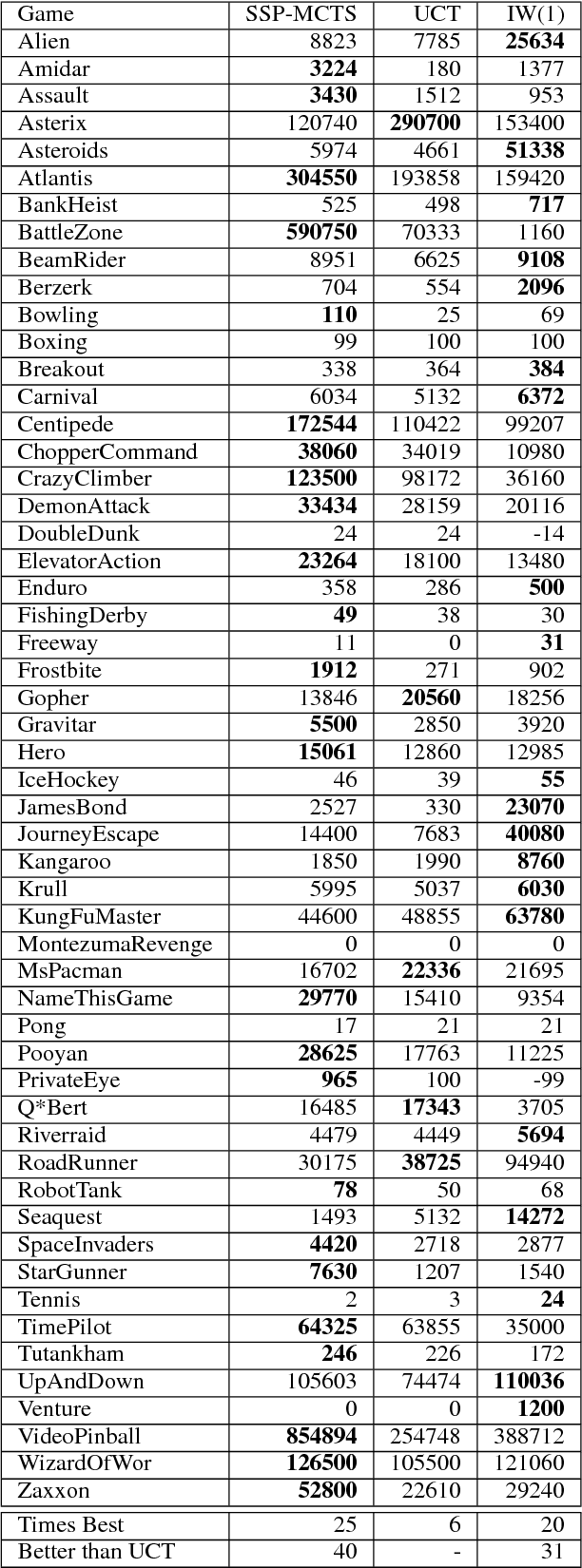
Monte Carlo Tree Search (MCTS) is particularly adapted to domains where the potential actions can be represented as a tree of sequential decisions. For an effective action selection, MCTS performs many simulations to build a reliable tree representation of the decision space. As such, a bottleneck to MCTS appears when enough simulations cannot be performed between action selections. This is particularly highlighted in continuously running tasks, for which the time available to perform simulations between actions tends to be limited due to the environment's state constantly changing. In this paper, we present an approach that takes advantage of the anytime characteristic of MCTS to increase the simulation time when allowed. Our approach is to effectively balance the prospect of selecting an action with the time that can be spared to perform MCTS simulations before the next action selection. For that, we considered the simulation time as a decision variable to be selected alongside an action. We extended the Hierarchical Optimistic Optimization applied to Tree (HOOT) method to adapt our approach to environments with a continuous decision space. We evaluated our approach for environments with a continuous decision space through OpenAI gym's Pendulum and Continuous Mountain Car environments and for environments with discrete action space through the arcade learning environment (ALE) platform. The evaluation results show that, with variable simulation times, the proposed approach outperforms the conventional MCTS in the evaluated continuous decision space tasks and improves the performance of MCTS in most of the ALE tasks.