 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Diverse Solutions in Deep Reinforcement Learning
Mar 12, 2021
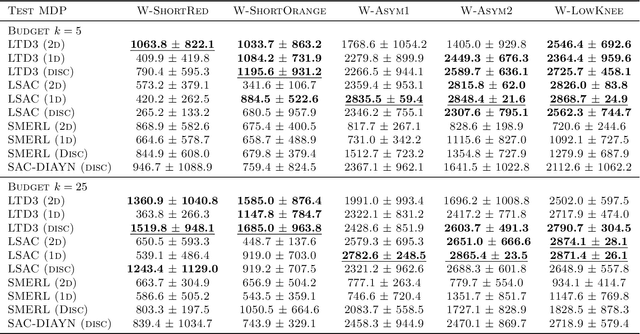
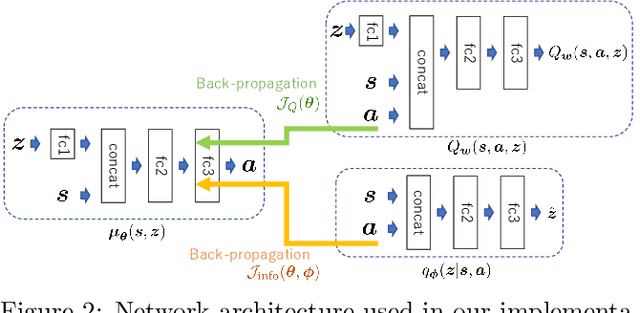
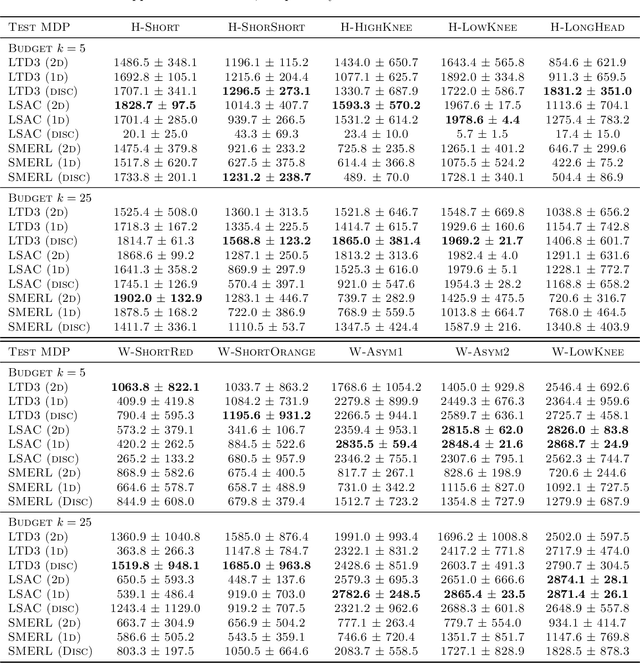
Reinforcement learning (RL) algorithms are typically limited to learning a single solution of a specified task, even though there often exists diverse solutions to a given task. Compared with learning a single solution, learning a set of diverse solutions is beneficial because diverse solutions enable robust few-shot adaptation and allow the user to select a preferred solution. Although previous studies have showed that diverse behaviors can be modeled with a policy conditioned on latent variables, an approach for modeling an infinite set of diverse solutions with continuous latent variables has not been investigated. In this study, we propose an RL method that can learn infinitely many solutions by training a policy conditioned on a continuous or discrete low-dimensional latent variable. Through continuous control tasks, we demonstrate that our method can learn diverse solutions in a data-efficient manner and that the solutions can be used for few-shot adaptation to solve unseen tasks.
Robust Imitation Learning from Noisy Demonstrations
Oct 31, 2020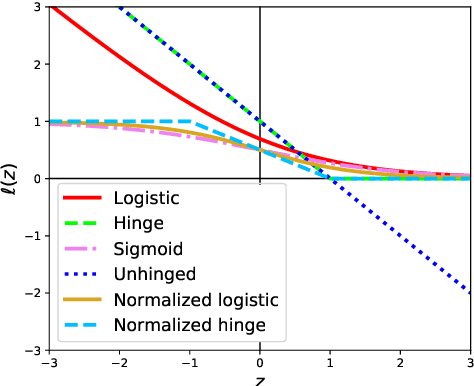
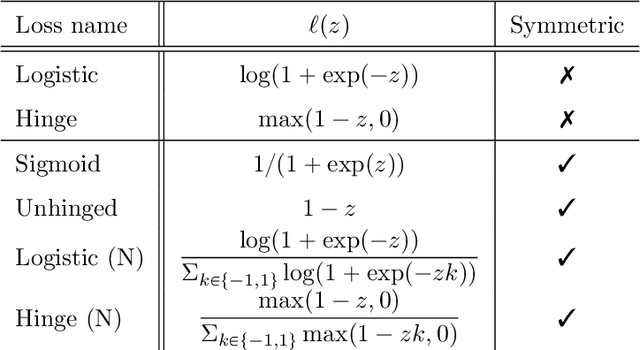
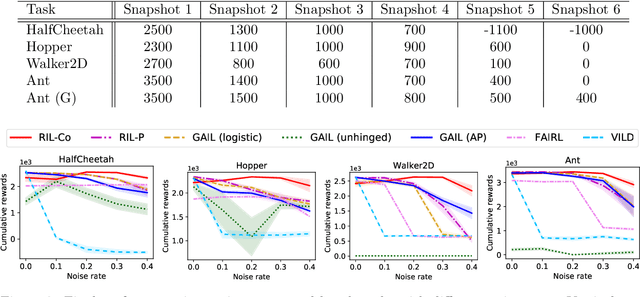
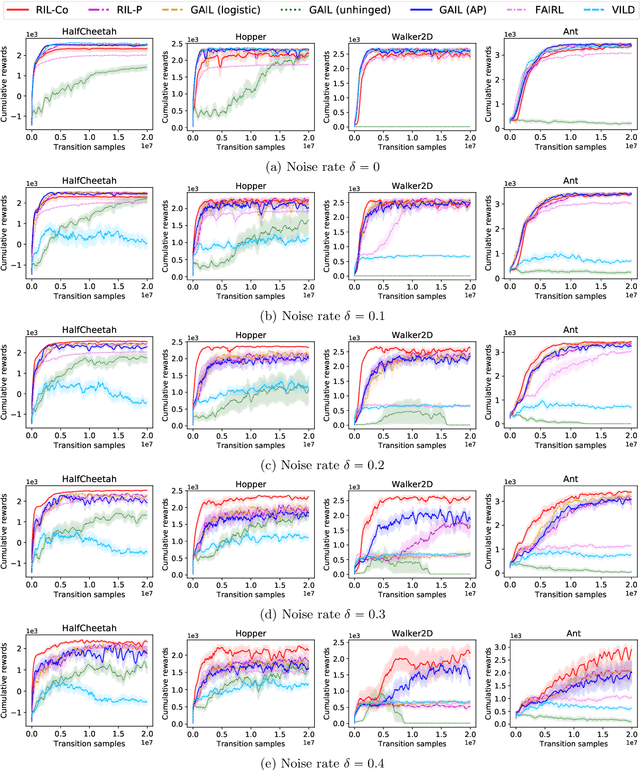
Learning from noisy demonstrations is a practical but highly challenging problem in imitation learning. In this paper, we first theoretically show that robust imitation learning can be achieved by optimizing a classification risk with a symmetric loss. Based on this theoretical finding, we then propose a new imitation learning method that optimizes the classification risk by effectively combining pseudo-labeling with co-training. Unlike existing methods, our method does not require additional labels or strict assumptions about noise distributions. Experimental results on continuous-control benchmarks show that our method is more robust compared to state-of-the-art methods.
Meta-Model-Based Meta-Policy Optimization
Jun 05, 2020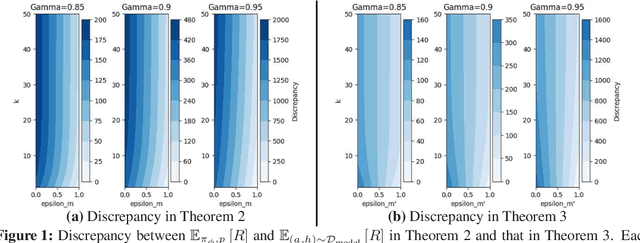
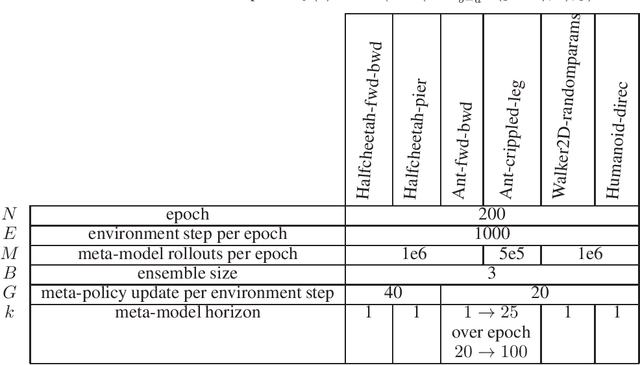
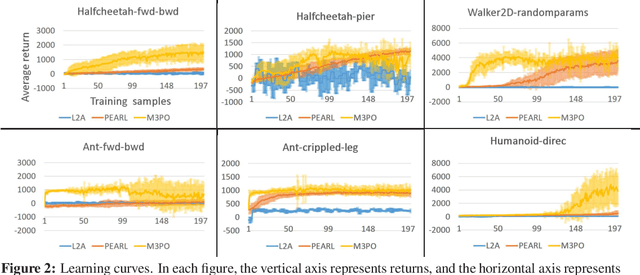
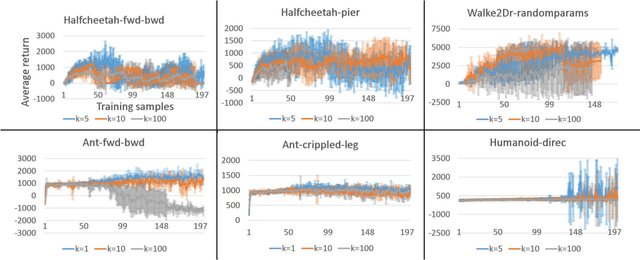
Model-based reinforcement learning (MBRL) has been applied to meta-learning settings and demonstrated its high sample efficiency. However, in previous MBRL for meta-learning settings, policies are optimized via rollouts that fully rely on a predictive model for an environment, and thus its performance in a real environment tends to degrade when the predictive model is inaccurate. In this paper, we prove that the performance degradation can be suppressed by using branched meta-rollouts. Based on this theoretical analysis, we propose meta-model-based meta-policy optimization (M3PO), in which the branched meta-rollouts are used for policy optimization. We demonstrate that M3PO outperforms existing meta reinforcement learning methods in continuous-control benchmarks.
VILD: Variational Imitation Learning with Diverse-quality Demonstrations
Sep 15, 2019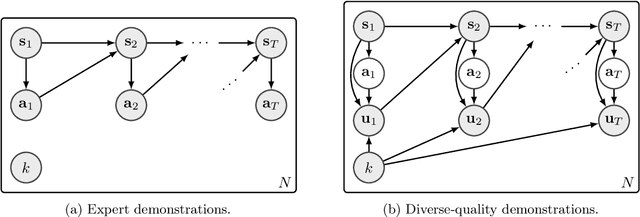
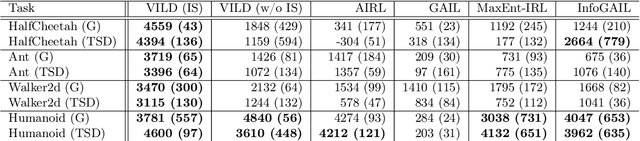
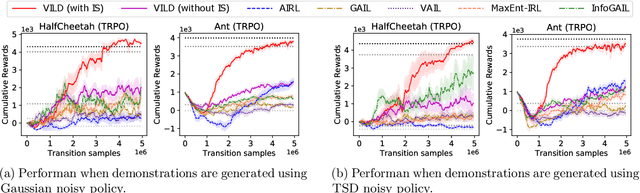
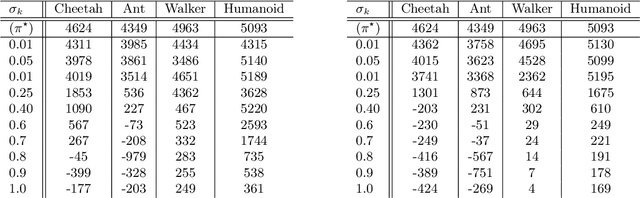
The goal of imitation learning (IL) is to learn a good policy from high-quality demonstrations. However, the quality of demonstrations in reality can be diverse, since it is easier and cheaper to collect demonstrations from a mix of experts and amateurs. IL in such situations can be challenging, especially when the level of demonstrators' expertise is unknown. We propose a new IL method called \underline{v}ariational \underline{i}mitation \underline{l}earning with \underline{d}iverse-quality demonstrations (VILD), where we explicitly model the level of demonstrators' expertise with a probabilistic graphical model and estimate it along with a reward function. We show that a naive approach to estimation is not suitable to large state and action spaces, and fix its issues by using a variational approach which can be easily implemented using existing reinforcement learning methods. Experiments on continuous-control benchmarks demonstrate that VILD outperforms state-of-the-art methods. Our work enables scalable and data-efficient IL under more realistic settings than before.
Imitation Learning from Imperfect Demonstration
Jan 30, 2019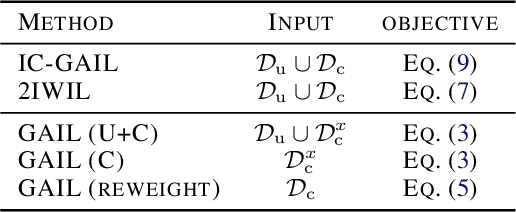
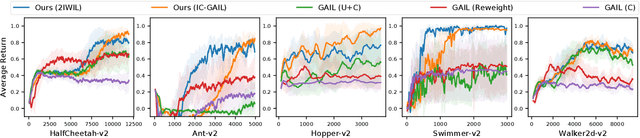
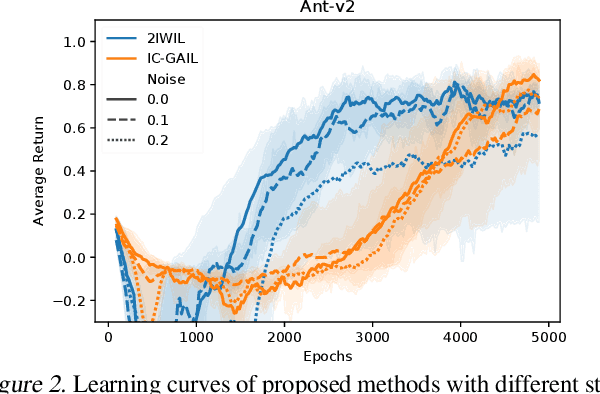
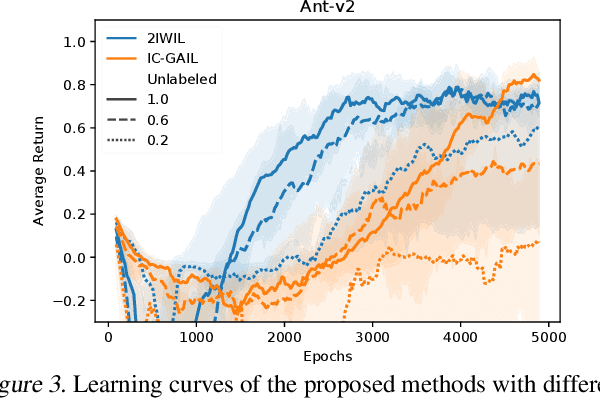
Imitation learning (IL) aims to learn an optimal policy from demonstrations. However, such demonstrations are often imperfect since collecting optimal ones is costly. To effectively learn from imperfect demonstrations, we propose a novel approach that utilizes confidence scores, which describe the quality of demonstrations. More specifically, we propose two confidence-based IL methods, namely two-step importance weighting IL (2IWIL) and generative adversarial IL with imperfect demonstration and confidence (IC-GAIL). We show that confidence scores given only to a small portion of sub-optimal demonstrations significantly improve the performance of IL both theoretically and empirically.
Hierarchical Reinforcement Learning via Advantage-Weighted Information Maximization
Jan 05, 2019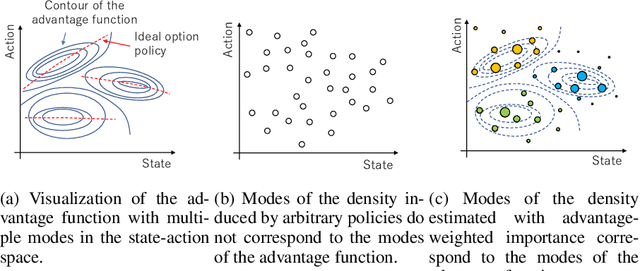


Real-world tasks are often highly structured. Hierarchical reinforcement learning (HRL) has attracted research interest as an approach for leveraging the hierarchical structure of a given task in reinforcement learning (RL). However, identifying the hierarchical policy structure that enhances the performance of RL is not a trivial task. In this paper, we propose an HRL method that learns a latent variable of a hierarchical policy using mutual information maximization. Our approach can be interpreted as a way to learn a discrete and latent representation of the state-action space. To learn option policies that correspond to modes of the advantage function, we introduce advantage-weighted importance sampling. In our HRL method, the gating policy learns to select option policies based on an option-value function, and these option policies are optimized based on the deterministic policy gradient method. This framework is derived by leveraging the analogy between a monolithic policy in standard RL and a hierarchical policy in HRL by using a deterministic option policy. Experimental results indicate that our HRL approach can learn a diversity of options and that it can enhance the performance of RL in continuous control tasks.
TD-Regularized Actor-Critic Methods
Dec 23, 2018

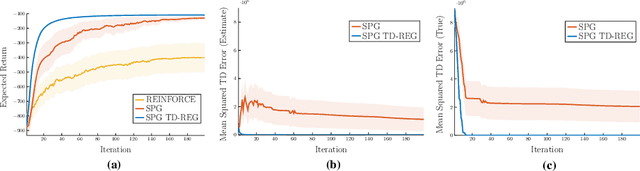
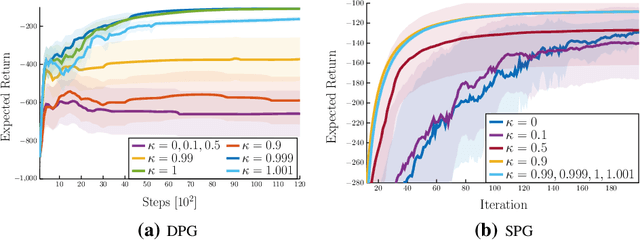
Actor-critic methods can achieve incredible performance on difficult reinforcement learning problems, but they are also prone to instability. This is partly due to the interaction between the actor and critic during learning, e.g., an inaccurate step taken by one of them might adversely affect the other and destabilize the learning. To avoid such issues, we propose to regularize the learning objective of the actor by penalizing the temporal difference (TD) error of the critic. This improves stability by avoiding large steps in the actor update whenever the critic is highly inaccurate. The resulting method, which we call the TD-regularized actor-critic method, is a simple plug-and-play approach to improve stability and overall performance of the actor-critic methods. Evaluations on standard benchmarks confirm this.
Active Deep Q-learning with Demonstration
Dec 06, 2018
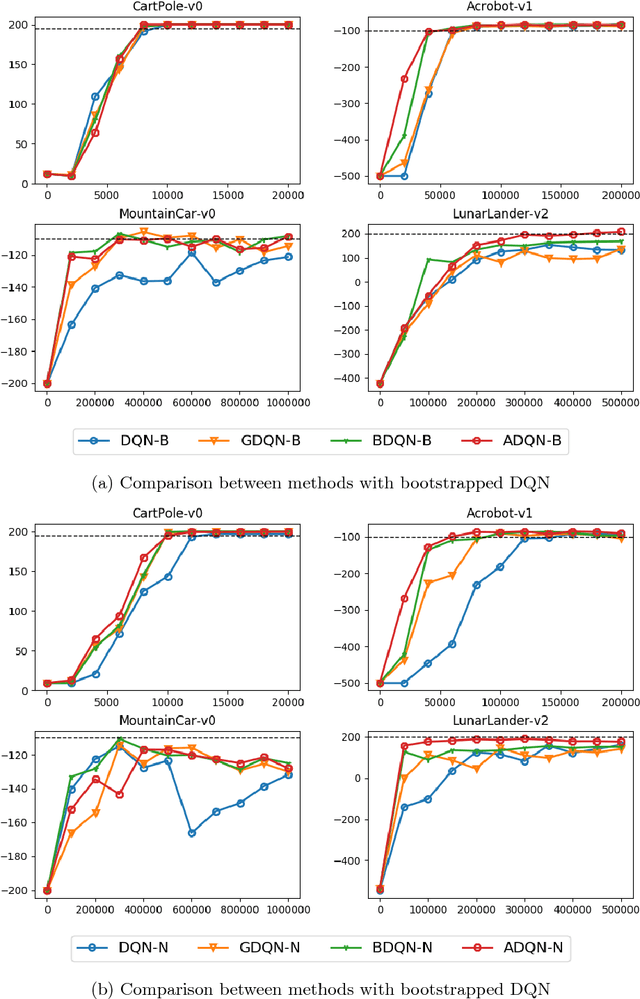
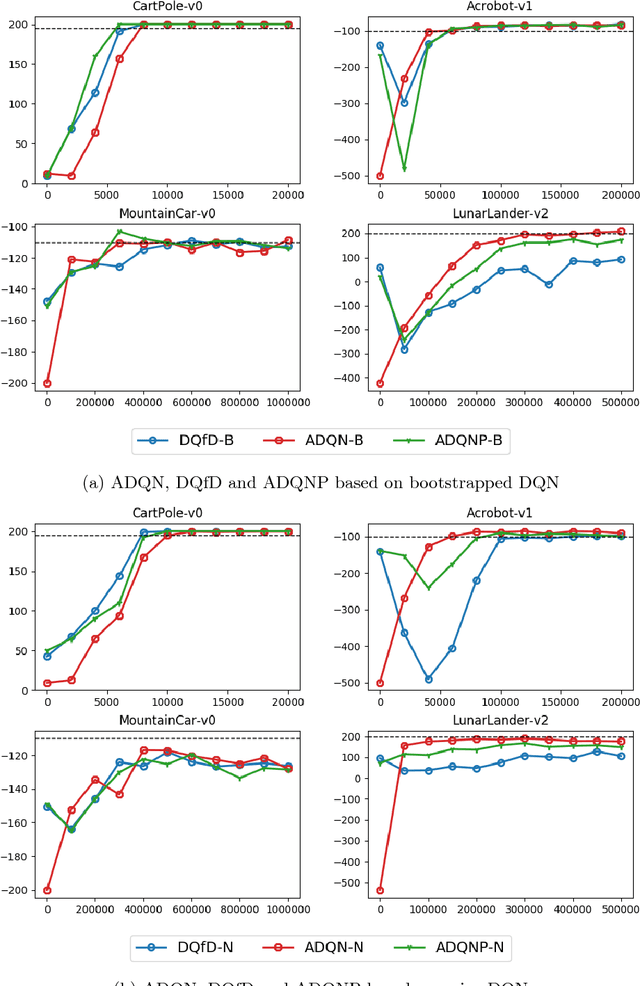
Recent research has shown that although Reinforcement Learning (RL) can benefit from expert demonstration, it usually takes considerable efforts to obtain enough demonstration. The efforts prevent training decent RL agents with expert demonstration in practice. In this work, we propose Active Reinforcement Learning with Demonstration (ARLD), a new framework to streamline RL in terms of demonstration efforts by allowing the RL agent to query for demonstration actively during training. Under the framework, we propose Active Deep Q-Network, a novel query strategy which adapts to the dynamically-changing distributions during the RL training process by estimating the uncertainty of recent states. The expert demonstration data within Active DQN are then utilized by optimizing supervised max-margin loss in addition to temporal difference loss within usual DQN training. We propose two methods of estimating the uncertainty based on two state-of-the-art DQN models, namely the divergence of bootstrapped DQN and the variance of noisy DQN. The empirical results validate that both methods not only learn faster than other passive expert demonstration methods with the same amount of demonstration and but also reach super-expert level of performance across four different tasks.
Fast and Scalable Bayesian Deep Learning by Weight-Perturbation in Adam
Aug 02, 2018
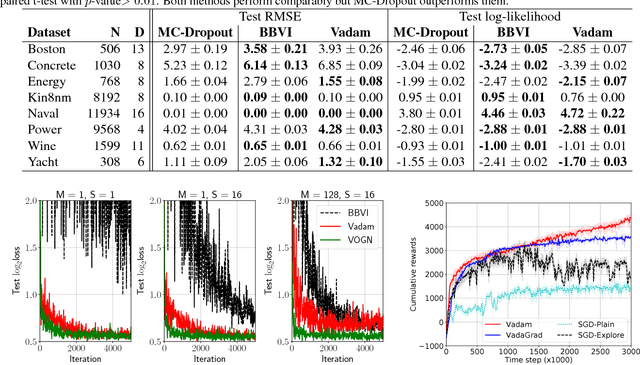
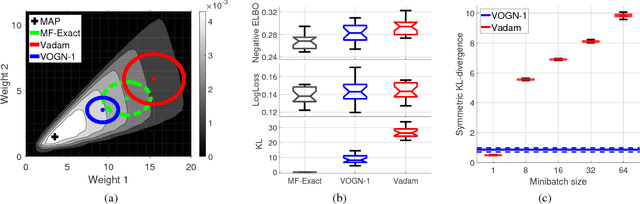

Uncertainty computation in deep learning is essential to design robust and reliable systems. Variational inference (VI) is a promising approach for such computation, but requires more effort to implement and execute compared to maximum-likelihood methods. In this paper, we propose new natural-gradient algorithms to reduce such efforts for Gaussian mean-field VI. Our algorithms can be implemented within the Adam optimizer by perturbing the network weights during gradient evaluations, and uncertainty estimates can be cheaply obtained by using the vector that adapts the learning rate. This requires lower memory, computation, and implementation effort than existing VI methods, while obtaining uncertainty estimates of comparable quality. Our empirical results confirm this and further suggest that the weight-perturbation in our algorithm could be useful for exploration in reinforcement learning and stochastic optimization.
* Camera ready version
Guide Actor-Critic for Continuous Control
Feb 22, 2018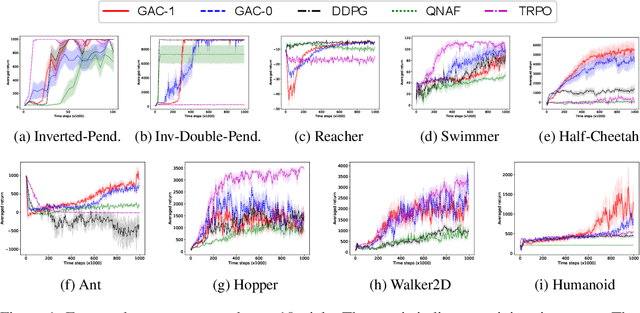
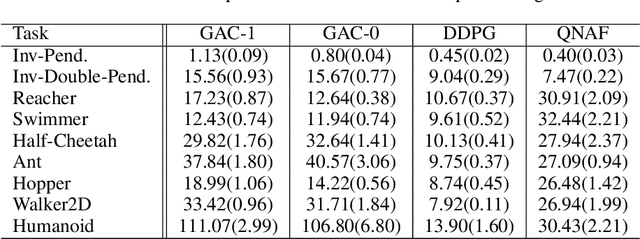
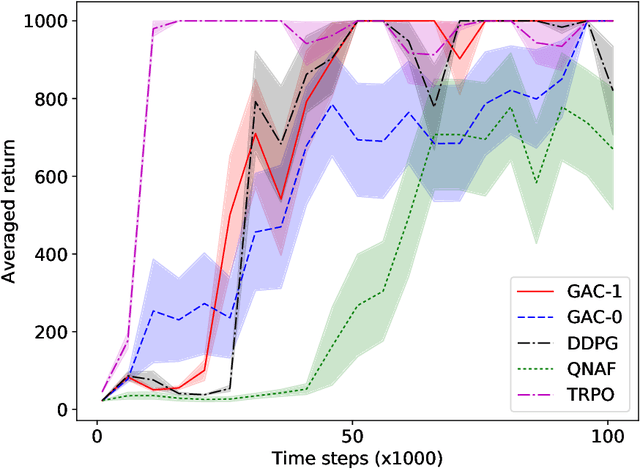
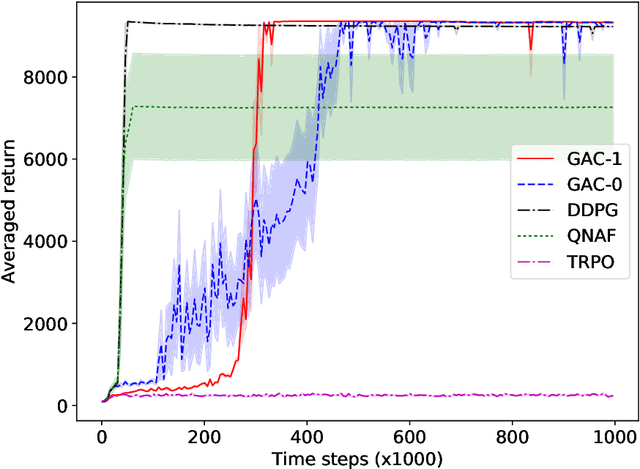
Actor-critic methods solve reinforcement learning problems by updating a parameterized policy known as an actor in a direction that increases an estimate of the expected return known as a critic. However, existing actor-critic methods only use values or gradients of the critic to update the policy parameter. In this paper, we propose a novel actor-critic method called the guide actor-critic (GAC). GAC firstly learns a guide actor that locally maximizes the critic and then it updates the policy parameter based on the guide actor by supervised learning. Our main theoretical contributions are two folds. First, we show that GAC updates the guide actor by performing second-order optimization in the action space where the curvature matrix is based on the Hessians of the critic. Second, we show that the deterministic policy gradient method is a special case of GAC when the Hessians are ignored. Through experiments, we show that our method is a promising reinforcement learning method for continuous controls.