 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual Human Generative Model: Masked Modeling Approach for Learning Human Characteristics
Jun 19, 2023



Identifying the relationship between healthcare attributes, lifestyles, and personality is vital for understanding and improving physical and mental conditions. Machine learning approaches are promising for modeling their relationships and offering actionable suggestions. In this paper, we propose Virtual Human Generative Model (VHGM), a machine learning model for estimating attributes about healthcare, lifestyles, and personalities. VHGM is a deep generative model trained with masked modeling to learn the joint distribution of attributes conditioned on known ones. Using heterogeneous tabular datasets, VHGM learns more than 1,800 attributes efficiently. We numerically evaluate the performance of VHGM and its training techniques. As a proof-of-concept of VHGM, we present several applications demonstrating user scenarios, such as virtual measurements of healthcare attributes and hypothesis verifications of lifestyles.
Diffusion models for missing value imputation in tabular data
Oct 31, 2022



Missing value imputation in machine learning is the task of estimating the missing values in the dataset accurately using available information. In this task, several deep generative modeling methods have been proposed and demonstrated their usefulness, e.g., generative adversarial imputation networks. Recently, diffusion models have gained popularity because of their effectiveness in the generative modeling task in images, texts, audio, etc. To our knowledge, less attention has been paid to the investigation of the effectiveness of diffusion models for missing value imputation in tabular data. Based on recent development of diffusion models for time-series data imputation, we propose a diffusion model approach called "Conditional Score-based Diffusion Models for Tabular data" (CSDI_T). To effectively handle categorical variables and numerical variables simultaneously, we investigate three techniques: one-hot encoding, analog bits encoding, and feature tokenization. Experimental results on benchmark datasets demonstrated the effectiveness of CSDI_T compared with well-known existing methods, and also emphasized the importance of the categorical embedding techniques.
Is the Performance of My Deep Network Too Good to Be True? A Direct Approach to Estimating the Bayes Error in Binary Classification
Feb 01, 2022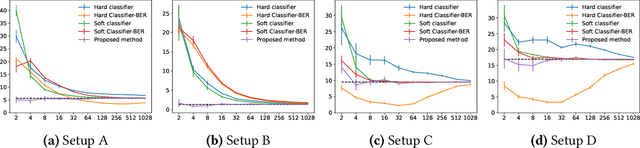

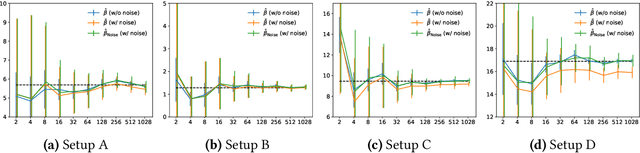

There is a fundamental limitation in the prediction performance that a machine learning model can achieve due to the inevitable uncertainty of the prediction target. In classification problems, this can be characterized by the Bayes error, which is the best achievable error with any classifier. The Bayes error can be used as a criterion to evaluate classifiers with state-of-the-art performance and can be used to detect test set overfitting. We propose a simple and direct Bayes error estimator, where we just take the mean of the labels that show \emph{uncertainty} of the classes. Our flexible approach enables us to perform Bayes error estimation even for weakly supervised data. In contrast to others, our method is model-free and even instance-free. Moreover, it has no hyperparameters and gives a more accurate estimate of the Bayes error than classifier-based baselines. Experiments using our method suggest that a recently proposed classifier, the Vision Transformer, may have already reached the Bayes error for certain benchmark datasets.
Cross-lingual Transfer for Text Classification with Dictionary-based Heterogeneous Graph
Sep 10, 2021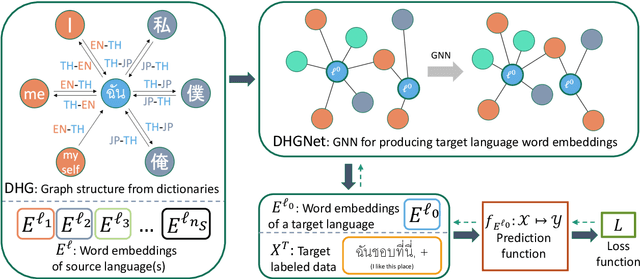
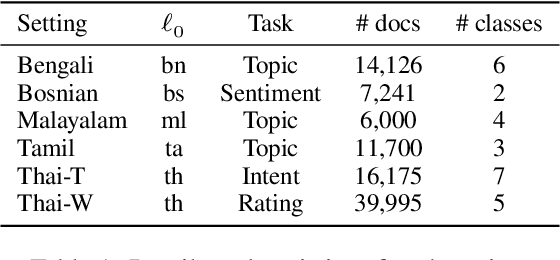
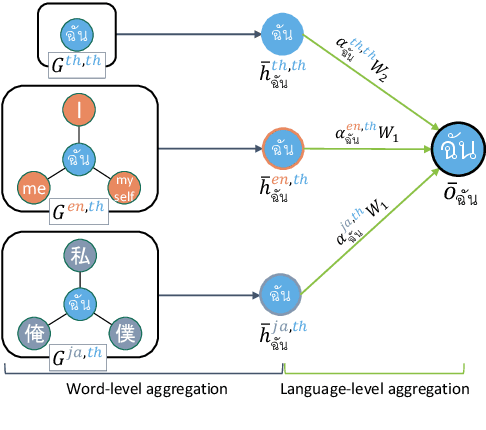
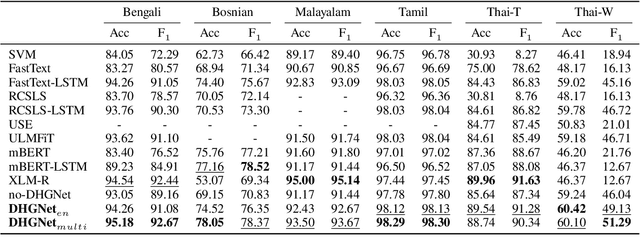
In cross-lingual text classification, it is required that task-specific training data in high-resource source languages are available, where the task is identical to that of a low-resource target language. However, collecting such training data can be infeasible because of the labeling cost, task characteristics, and privacy concerns. This paper proposes an alternative solution that uses only task-independent word embeddings of high-resource languages and bilingual dictionaries. First, we construct a dictionary-based heterogeneous graph (DHG) from bilingual dictionaries. This opens the possibility to use graph neural networks for cross-lingual transfer. The remaining challenge is the heterogeneity of DHG because multiple languages are considered. To address this challenge, we propose dictionary-based heterogeneous graph neural network (DHGNet) that effectively handles the heterogeneity of DHG by two-step aggregations, which are word-level and language-level aggregations. Experimental results demonstrate that our method outperforms pretrained models even though it does not access to large corpora. Furthermore, it can perform well even though dictionaries contain many incorrect translations. Its robustness allows the usage of a wider range of dictionaries such as an automatically constructed dictionary and crowdsourced dictionary, which are convenient for real-world applications.
A Symmetric Loss Perspective of Reliable Machine Learning
Jan 05, 2021
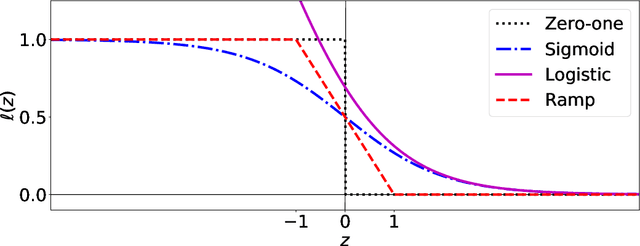


When minimizing the empirical risk in binary classification, it is a common practice to replace the zero-one loss with a surrogate loss to make the learning objective feasible to optimize. Examples of well-known surrogate losses for binary classification include the logistic loss, hinge loss, and sigmoid loss. It is known that the choice of a surrogate loss can highly influence the performance of the trained classifier and therefore it should be carefully chosen. Recently, surrogate losses that satisfy a certain symmetric condition (aka., symmetric losses) have demonstrated their usefulness in learning from corrupted labels. In this article, we provide an overview of symmetric losses and their applications. First, we review how a symmetric loss can yield robust classification from corrupted labels in balanced error rate (BER) minimization and area under the receiver operating characteristic curve (AUC) maximization. Then, we demonstrate how the robust AUC maximization method can benefit natural language processing in the problem where we want to learn only from relevant keywords and unlabeled documents. Finally, we conclude this article by discussing future directions, including potential applications of symmetric losses for reliable machine learning and the design of non-symmetric losses that can benefit from the symmetric condition.
On Focal Loss for Class-Posterior Probability Estimation: A Theoretical Perspective
Dec 14, 2020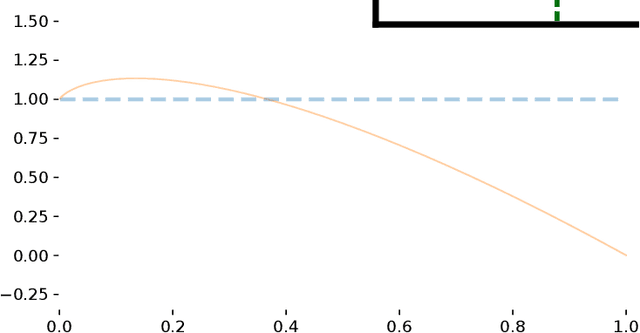
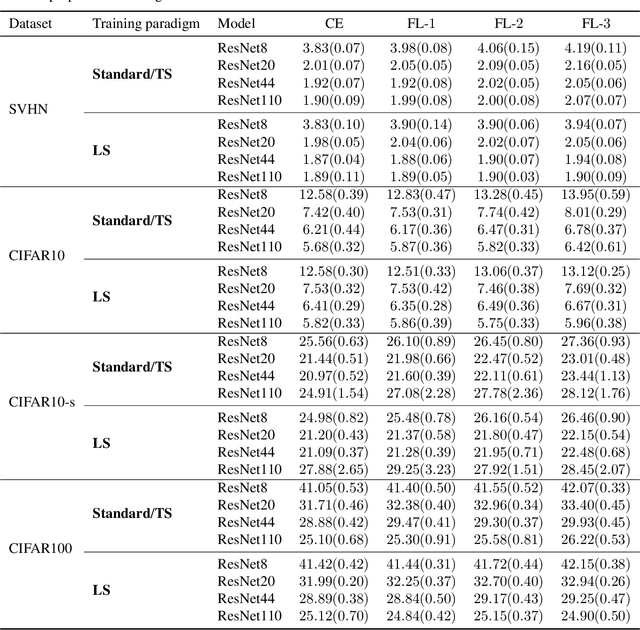
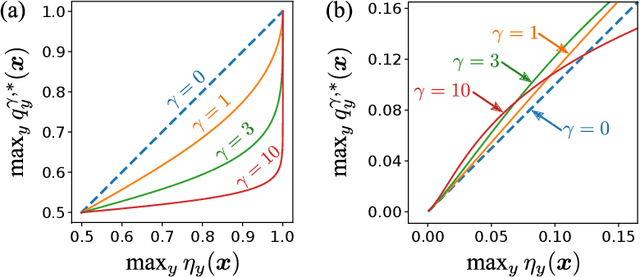
The focal loss has demonstrated its effectiveness in many real-world applications such as object detection and image classification, but its theoretical understanding has been limited so far. In this paper, we first prove that the focal loss is classification-calibrated, i.e., its minimizer surely yields the Bayes-optimal classifier and thus the use of the focal loss in classification can be theoretically justified. However, we also prove a negative fact that the focal loss is not strictly proper, i.e., the confidence score of the classifier obtained by focal loss minimization does not match the true class-posterior probability and thus it is not reliable as a class-posterior probability estimator. To mitigate this problem, we next prove that a particular closed-form transformation of the confidence score allows us to recover the true class-posterior probability. Through experiments on benchmark datasets, we demonstrate that our proposed transformation significantly improves the accuracy of class-posterior probability estimation.
Robust Imitation Learning from Noisy Demonstrations
Oct 31, 2020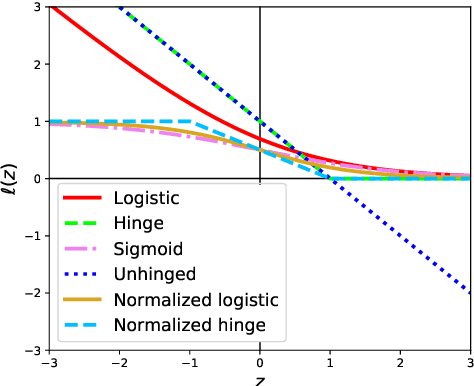
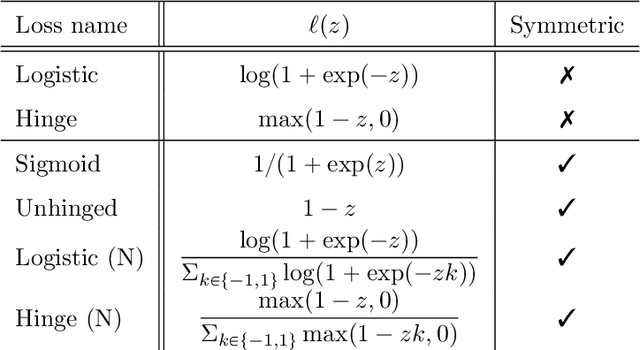
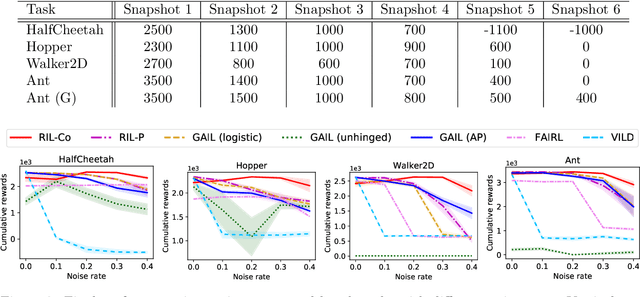
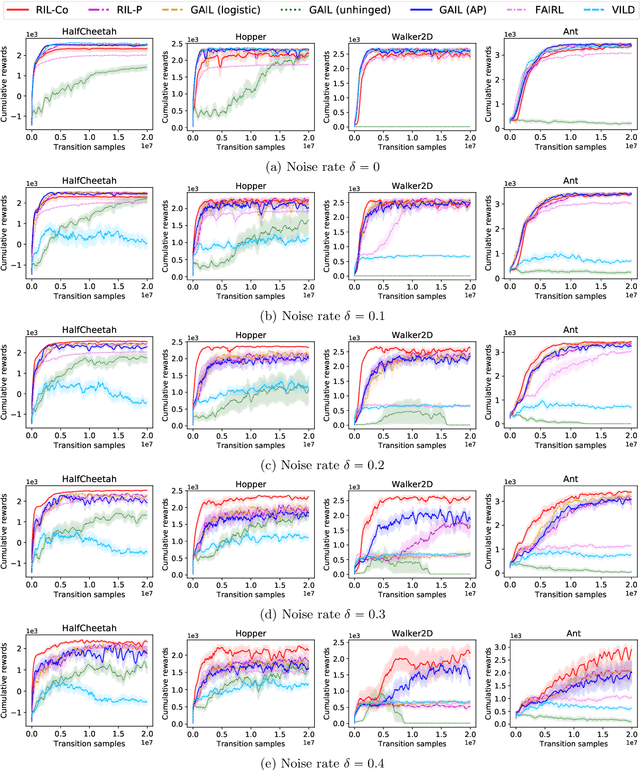
Learning from noisy demonstrations is a practical but highly challenging problem in imitation learning. In this paper, we first theoretically show that robust imitation learning can be achieved by optimizing a classification risk with a symmetric loss. Based on this theoretical finding, we then propose a new imitation learning method that optimizes the classification risk by effectively combining pseudo-labeling with co-training. Unlike existing methods, our method does not require additional labels or strict assumptions about noise distributions. Experimental results on continuous-control benchmarks show that our method is more robust compared to state-of-the-art methods.
Classification with Rejection Based on Cost-sensitive Classification
Oct 31, 2020
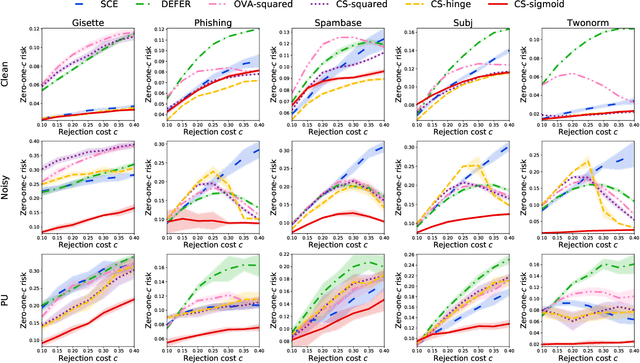
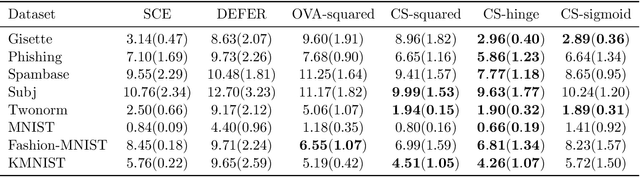

The goal of classification with rejection is to avoid risky misclassification in error-critical applications such as medical diagnosis and product inspection. In this paper, based on the relationship between classification with rejection and cost-sensitive classification, we propose a novel method of classification with rejection by learning an ensemble of cost-sensitive classifiers, which satisfies all the following properties for the first time: (i) it can avoid estimating class-posterior probabilities, resulting in improved classification accuracy. (ii) it allows a flexible choice of losses including non-convex ones, (iii) it does not require complicated modifications when using different losses, (iv) it is applicable to both binary and multiclass cases, and (v) it is theoretically justifiable for any classification-calibrated loss. Experimental results demonstrate the usefulness of our proposed approach in clean-labeled, noisy-labeled, and positive-unlabeled classification.
Learning from Aggregate Observations
Apr 14, 2020

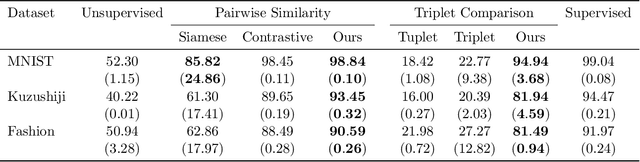
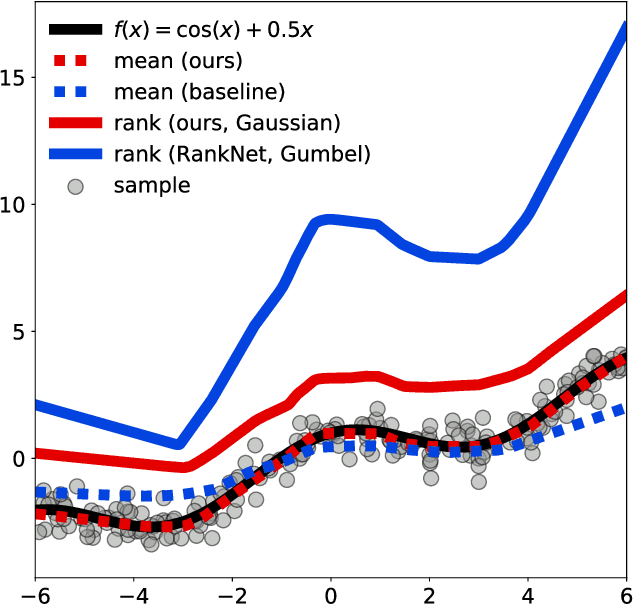
We study the problem of learning from aggregate observations where supervision signals are given to sets of instances instead of individual instances, while the goal is still to predict labels of unseen individuals. A well-known example is multiple instance learning (MIL). In this paper, we extend MIL beyond binary classification to other problems such as multiclass classification and regression. We present a probabilistic framework that is applicable to a variety of aggregate observations, e.g., pairwise similarity for classification and mean/difference/rank observation for regression. We propose a simple yet effective method based on the maximum likelihood principle, which can be simply implemented for various differentiable models such as deep neural networks and gradient boosting machines. Experiments on three novel problem settings -- classification via triplet comparison and regression via mean/rank observation indicate the effectiveness of the proposed method.
Time-varying Gaussian Process Bandit Optimization with Non-constant Evaluation Time
Mar 11, 2020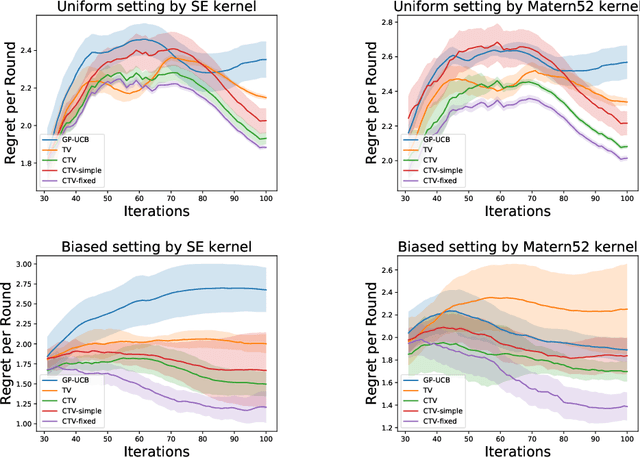
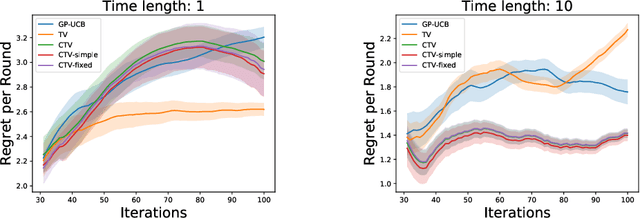
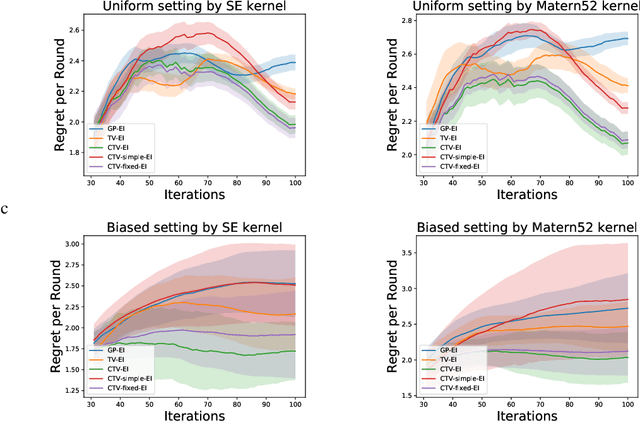
The Gaussian process bandit is a problem in which we want to find a maximizer of a black-box function with the minimum number of function evaluations. If the black-box function varies with time, then time-varying Bayesian optimization is a promising framework. However, a drawback with current methods is in the assumption that the evaluation time for every observation is constant, which can be unrealistic for many practical applications, e.g., recommender systems and environmental monitoring. As a result, the performance of current methods can be degraded when this assumption is violated. To cope with this problem, we propose a novel time-varying Bayesian optimization algorithm that can effectively handle the non-constant evaluation time. Furthermore, we theoretically establish a regret bound of our algorithm. Our bound elucidates that a pattern of the evaluation time sequence can hugely affect the difficulty of the problem. We also provide experimental results to validate the practical effectiveness of the proposed method.