 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Approach for Weakly Supervised Multicalibration
May 11, 2026Multicalibration requires predicted scores to agree with label probabilities across rich families of subgroups and score-dependent tests, but existing methods require clean input-label pairs for evaluation and post-processing. This assumption fails in weakly supervised learning (WSL) regimes -- including positive-unlabeled, unlabeled-unlabeled, and positive-confidence learning -- where clean labels are costly or unavailable even though reliable uncertainty estimates may be crucial. We address this gap by developing estimators of multicalibration error and post-hoc correction methods for WSL settings in which clean input-label pairs are unavailable. We propose a unified framework for estimating and correcting multicalibration under weak supervision by combining contamination-matrix risk rewrites with witness-based calibration constraints, yielding corrected multicalibration moments with finite-sample guarantees. We further propose weak-label multicalibration boost (WLMC), a generic post-hoc recalibration algorithm under weak supervision. Finally, we conduct experiments across multiple weak-supervision settings to evaluate multicalibration behavior and offer empirical insight into uncertainty estimation under weak supervision.
Robust and Computationally Efficient Linear Contextual Bandits under Adversarial Corruption and Heavy-Tailed Noise
Mar 16, 2026We study linear contextual bandits under adversarial corruption and heavy-tailed noise with finite $(1+ε)$-th moments for some $ε\in (0,1]$. Existing work that addresses both adversarial corruption and heavy-tailed noise relies on a finite variance (i.e., finite second-moment) assumption and suffers from computational inefficiency. We propose a computationally efficient algorithm based on online mirror descent that achieves robustness to both adversarial corruption and heavy-tailed noise. While the existing algorithm incurs $\mathcal{O}(t\log T)$ computational cost, our algorithm reduces this to $\mathcal{O}(1)$ per round. We establish an additive regret bound consisting of a term depending on the $(1+ε)$-moment bound of the noise and a term depending on the total amount of corruption. In particular, when $ε= 1$, our result recovers existing guarantees under finite-variance assumptions. When no corruption is present, it matches the best-known rates for linear contextual bandits with heavy-tailed noise. Moreover, the algorithm requires no prior knowledge of the noise moment bound or the total amount of corruption and still guarantees sublinear regret.
Data-driven Projection Generation for Efficiently Solving Heterogeneous Quadratic Programming Problems
Oct 30, 2025We propose a data-driven framework for efficiently solving quadratic programming (QP) problems by reducing the number of variables in high-dimensional QPs using instance-specific projection. A graph neural network-based model is designed to generate projections tailored to each QP instance, enabling us to produce high-quality solutions even for previously unseen problems. The model is trained on heterogeneous QPs to minimize the expected objective value evaluated on the projected solutions. This is formulated as a bilevel optimization problem; the inner optimization solves the QP under a given projection using a QP solver, while the outer optimization updates the model parameters. We develop an efficient algorithm to solve this bilevel optimization problem, which computes parameter gradients without backpropagating through the solver. We provide a theoretical analysis of the generalization ability of solving QPs with projection matrices generated by neural networks. Experimental results demonstrate that our method produces high-quality feasible solutions with reduced computation time, outperforming existing methods.
Uniform convergence of the smooth calibration error and its relationship with functional gradient
May 26, 2025Calibration is a critical requirement for reliable probabilistic prediction, especially in high-risk applications. However, the theoretical understanding of which learning algorithms can simultaneously achieve high accuracy and good calibration remains limited, and many existing studies provide empirical validation or a theoretical guarantee in restrictive settings. To address this issue, in this work, we focus on the smooth calibration error (CE) and provide a uniform convergence bound, showing that the smooth CE is bounded by the sum of the smooth CE over the training dataset and a generalization gap. We further prove that the functional gradient of the loss function can effectively control the training smooth CE. Based on this framework, we analyze three representative algorithms: gradient boosting trees, kernel boosting, and two-layer neural networks. For each, we derive conditions under which both classification and calibration performances are simultaneously guaranteed. Our results offer new theoretical insights and practical guidance for designing reliable probabilistic models with provable calibration guarantees.
PAC-Bayes Analysis for Recalibration in Classification
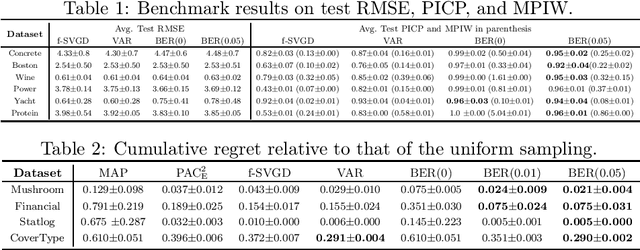
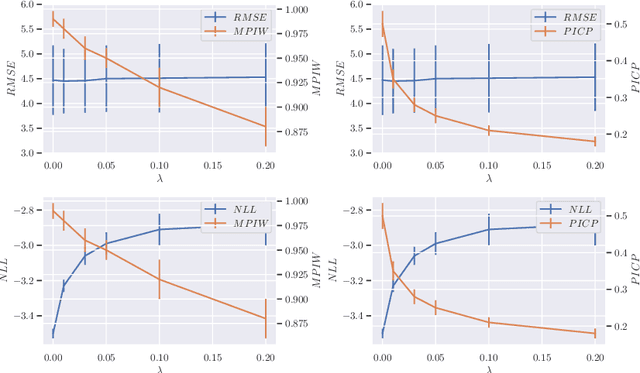
Jun 10, 2024Nonparametric estimation with binning is widely employed in the calibration error evaluation and the recalibration of machine learning models. Recently, theoretical analyses of the bias induced by this estimation approach have been actively pursued; however, the understanding of the generalization of the calibration error to unknown data remains limited. In addition, although many recalibration algorithms have been proposed, their generalization performance lacks theoretical guarantees. To address this problem, we conduct a generalization analysis of the calibration error under the probably approximately correct (PAC) Bayes framework. This approach enables us to derive a first optimizable upper bound for the generalization error in the calibration context. We then propose a generalization-aware recalibration algorithm based on our generalization theory. Numerical experiments show that our algorithm improves the Gaussian-process-based recalibration performance on various benchmark datasets and models.
Time-Independent Information-Theoretic Generalization Bounds for SGLD
Nov 02, 2023
We provide novel information-theoretic generalization bounds for stochastic gradient Langevin dynamics (SGLD) under the assumptions of smoothness and dissipativity, which are widely used in sampling and non-convex optimization studies. Our bounds are time-independent and decay to zero as the sample size increases, regardless of the number of iterations and whether the step size is fixed. Unlike previous studies, we derive the generalization error bounds by focusing on the time evolution of the Kullback--Leibler divergence, which is related to the stability of datasets and is the upper bound of the mutual information between output parameters and an input dataset. Additionally, we establish the first information-theoretic generalization bound when the training and test loss are the same by showing that a loss function of SGLD is sub-exponential. This bound is also time-independent and removes the problematic step size dependence in existing work, leading to an improved excess risk bound by combining our analysis with the existing non-convex optimization error bounds.
Information-theoretic Analysis of Test Data Sensitivity in Uncertainty
Jul 23, 2023



Bayesian inference is often utilized for uncertainty quantification tasks. A recent analysis by Xu and Raginsky 2022 rigorously decomposed the predictive uncertainty in Bayesian inference into two uncertainties, called aleatoric and epistemic uncertainties, which represent the inherent randomness in the data-generating process and the variability due to insufficient data, respectively. They analyzed those uncertainties in an information-theoretic way, assuming that the model is well-specified and treating the model's parameters as latent variables. However, the existing information-theoretic analysis of uncertainty cannot explain the widely believed property of uncertainty, known as the sensitivity between the test and training data. It implies that when test data are similar to training data in some sense, the epistemic uncertainty should become small. In this work, we study such uncertainty sensitivity using our novel decomposition method for the predictive uncertainty. Our analysis successfully defines such sensitivity using information-theoretic quantities. Furthermore, we extend the existing analysis of Bayesian meta-learning and show the novel sensitivities among tasks for the first time.
Excess risk analysis for epistemic uncertainty with application to variational inference
Jun 02, 2022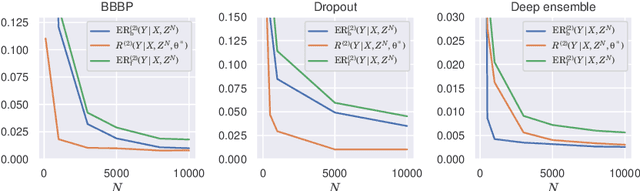
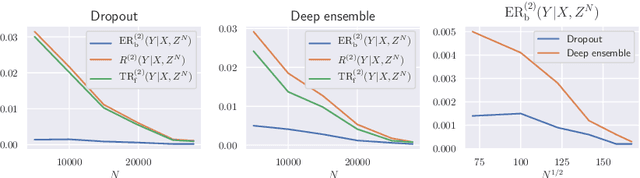
We analyze the epistemic uncertainty (EU) of supervised learning in Bayesian inference by focusing on the excess risk. Existing analysis is limited to the Bayesian setting, which assumes a correct model and exact Bayesian posterior distribution. Thus we cannot apply the existing theory to modern Bayesian algorithms, such as variational inference. To address this, we present a novel EU analysis in the frequentist setting, where data is generated from an unknown distribution. We show a relation between the generalization ability and the widely used EU measurements, such as the variance and entropy of the predictive distribution. Then we show their convergence behaviors theoretically. Finally, we propose new variational inference that directly controls the prediction and EU evaluation performances based on the PAC-Bayesian theory. Numerical experiments show that our algorithm significantly improves the EU evaluation over the existing methods.
Loss function based second-order Jensen inequality and its application to particle variational inference
Jun 10, 2021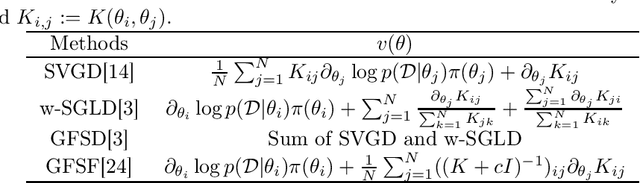

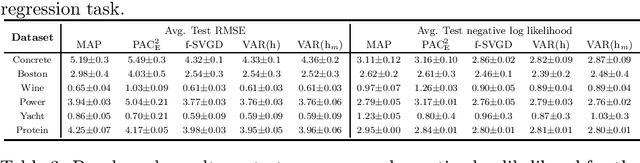

Bayesian model averaging, obtained as the expectation of a likelihood function by a posterior distribution, has been widely used for prediction, evaluation of uncertainty, and model selection. Various approaches have been developed to efficiently capture the information in the posterior distribution; one such approach is the optimization of a set of models simultaneously with interaction to ensure the diversity of the individual models in the same way as ensemble learning. A representative approach is particle variational inference (PVI), which uses an ensemble of models as an empirical approximation for the posterior distribution. PVI iteratively updates each model with a repulsion force to ensure the diversity of the optimized models. However, despite its promising performance, a theoretical understanding of this repulsion and its association with the generalization ability remains unclear. In this paper, we tackle this problem in light of PAC-Bayesian analysis. First, we provide a new second-order Jensen inequality, which has the repulsion term based on the loss function. Thanks to the repulsion term, it is tighter than the standard Jensen inequality. Then, we derive a novel generalization error bound and show that it can be reduced by enhancing the diversity of models. Finally, we derive a new PVI that optimizes the generalization error bound directly. Numerical experiments demonstrate that the performance of the proposed PVI compares favorably with existing methods in the experiment.
Time-varying Gaussian Process Bandit Optimization with Non-constant Evaluation Time
Mar 11, 2020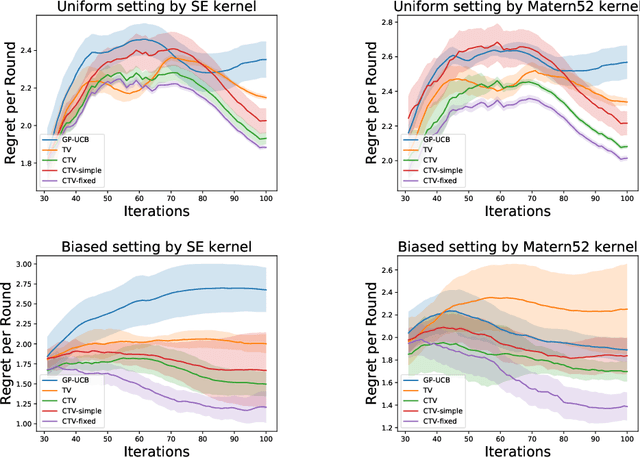
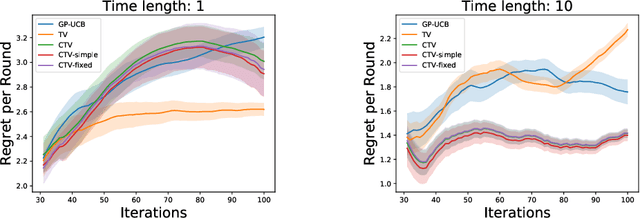
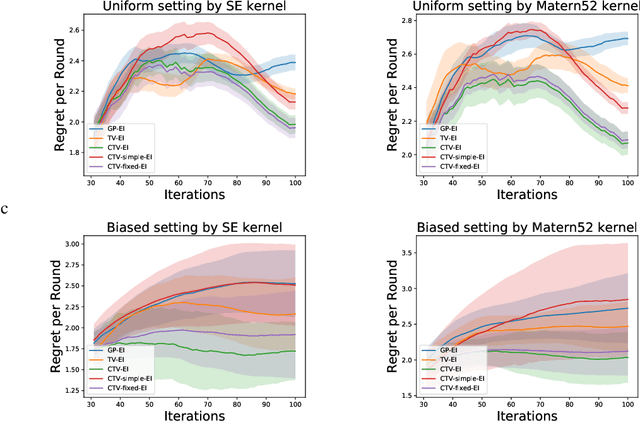
The Gaussian process bandit is a problem in which we want to find a maximizer of a black-box function with the minimum number of function evaluations. If the black-box function varies with time, then time-varying Bayesian optimization is a promising framework. However, a drawback with current methods is in the assumption that the evaluation time for every observation is constant, which can be unrealistic for many practical applications, e.g., recommender systems and environmental monitoring. As a result, the performance of current methods can be degraded when this assumption is violated. To cope with this problem, we propose a novel time-varying Bayesian optimization algorithm that can effectively handle the non-constant evaluation time. Furthermore, we theoretically establish a regret bound of our algorithm. Our bound elucidates that a pattern of the evaluation time sequence can hugely affect the difficulty of the problem. We also provide experimental results to validate the practical effectiveness of the proposed method.