 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-driven Projection Generation for Efficiently Solving Heterogeneous Quadratic Programming Problems
Oct 30, 2025We propose a data-driven framework for efficiently solving quadratic programming (QP) problems by reducing the number of variables in high-dimensional QPs using instance-specific projection. A graph neural network-based model is designed to generate projections tailored to each QP instance, enabling us to produce high-quality solutions even for previously unseen problems. The model is trained on heterogeneous QPs to minimize the expected objective value evaluated on the projected solutions. This is formulated as a bilevel optimization problem; the inner optimization solves the QP under a given projection using a QP solver, while the outer optimization updates the model parameters. We develop an efficient algorithm to solve this bilevel optimization problem, which computes parameter gradients without backpropagating through the solver. We provide a theoretical analysis of the generalization ability of solving QPs with projection matrices generated by neural networks. Experimental results demonstrate that our method produces high-quality feasible solutions with reduced computation time, outperforming existing methods.
MetaCaDI: A Meta-Learning Framework for Scalable Causal Discovery with Unknown Interventions
Oct 25, 2025Uncovering the underlying causal mechanisms of complex real-world systems remains a significant challenge, as these systems often entail high data collection costs and involve unknown interventions. We introduce MetaCaDI, the first framework to cast the joint discovery of a causal graph and unknown interventions as a meta-learning problem. MetaCaDI is a Bayesian framework that learns a shared causal graph structure across multiple experiments and is optimized to rapidly adapt to new, few-shot intervention target prediction tasks. A key innovation is our model's analytical adaptation, which uses a closed-form solution to bypass expensive and potentially unstable gradient-based bilevel optimization. Extensive experiments on synthetic and complex gene expression data demonstrate that MetaCaDI significantly outperforms state-of-the-art methods. It excels at both causal graph recovery and identifying intervention targets from as few as 10 data instances, proving its robustness in data-scarce scenarios.
Concept Unlearning in Large Language Models via Self-Constructed Knowledge Triplets
Sep 19, 2025Machine Unlearning (MU) has recently attracted considerable attention as a solution to privacy and copyright issues in large language models (LLMs). Existing MU methods aim to remove specific target sentences from an LLM while minimizing damage to unrelated knowledge. However, these approaches require explicit target sentences and do not support removing broader concepts, such as persons or events. To address this limitation, we introduce Concept Unlearning (CU) as a new requirement for LLM unlearning. We leverage knowledge graphs to represent the LLM's internal knowledge and define CU as removing the forgetting target nodes and associated edges. This graph-based formulation enables a more intuitive unlearning and facilitates the design of more effective methods. We propose a novel method that prompts the LLM to generate knowledge triplets and explanatory sentences about the forgetting target and applies the unlearning process to these representations. Our approach enables more precise and comprehensive concept removal by aligning the unlearning process with the LLM's internal knowledge representations. Experiments on real-world and synthetic datasets demonstrate that our method effectively achieves concept-level unlearning while preserving unrelated knowledge.
Meta-learning Representations for Learning from Multiple Annotators
Jun 12, 2025We propose a meta-learning method for learning from multiple noisy annotators. In many applications such as crowdsourcing services, labels for supervised learning are given by multiple annotators. Since the annotators have different skills or biases, given labels can be noisy. To learn accurate classifiers, existing methods require many noisy annotated data. However, sufficient data might be unavailable in practice. To overcome the lack of data, the proposed method uses labeled data obtained in different but related tasks. The proposed method embeds each example in tasks to a latent space by using a neural network and constructs a probabilistic model for learning a task-specific classifier while estimating annotators' abilities on the latent space. This neural network is meta-learned to improve the expected test classification performance when the classifier is adapted to a given small amount of annotated data. This classifier adaptation is performed by maximizing the posterior probability via the expectation-maximization (EM) algorithm. Since each step in the EM algorithm is easily computed as a closed-form and is differentiable, the proposed method can efficiently backpropagate the loss through the EM algorithm to meta-learn the neural network. We show the effectiveness of our method with real-world datasets with synthetic noise and real-world crowdsourcing datasets.
K$^2$IE: Kernel Method-based Kernel Intensity Estimators for Inhomogeneous Poisson Processes
May 30, 2025Kernel method-based intensity estimators, formulated within reproducing kernel Hilbert spaces (RKHSs), and classical kernel intensity estimators (KIEs) have been among the most easy-to-implement and feasible methods for estimating the intensity functions of inhomogeneous Poisson processes. While both approaches share the term "kernel", they are founded on distinct theoretical principles, each with its own strengths and limitations. In this paper, we propose a novel regularized kernel method for Poisson processes based on the least squares loss and show that the resulting intensity estimator involves a specialized variant of the representer theorem: it has the dual coefficient of unity and coincides with classical KIEs. This result provides new theoretical insights into the connection between classical KIEs and kernel method-based intensity estimators, while enabling us to develop an efficient KIE by leveraging advanced techniques from RKHS theory. We refer to the proposed model as the kernel method-based kernel intensity estimator (K$^2$IE). Through experiments on synthetic datasets, we show that K$^2$IE achieves comparable predictive performance while significantly surpassing the state-of-the-art kernel method-based estimator in computational efficiency.
Positive-Unlabeled Diffusion Models for Preventing Sensitive Data Generation
Mar 05, 2025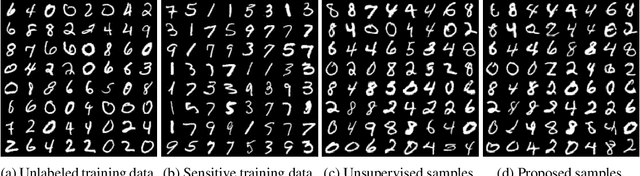
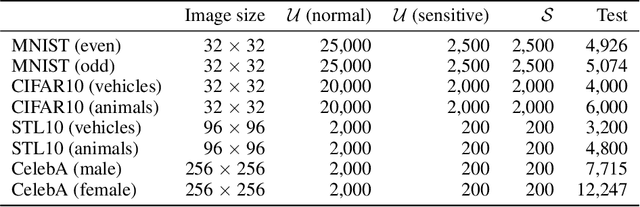
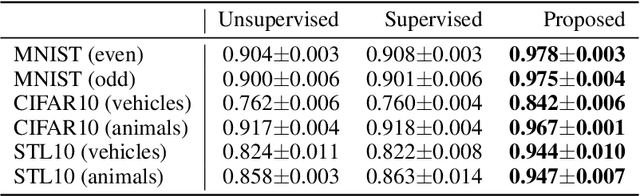

Diffusion models are powerful generative models but often generate sensitive data that are unwanted by users, mainly because the unlabeled training data frequently contain such sensitive data. Since labeling all sensitive data in the large-scale unlabeled training data is impractical, we address this problem by using a small amount of labeled sensitive data. In this paper, we propose positive-unlabeled diffusion models, which prevent the generation of sensitive data using unlabeled and sensitive data. Our approach can approximate the evidence lower bound (ELBO) for normal (negative) data using only unlabeled and sensitive (positive) data. Therefore, even without labeled normal data, we can maximize the ELBO for normal data and minimize it for labeled sensitive data, ensuring the generation of only normal data. Through experiments across various datasets and settings, we demonstrated that our approach can prevent the generation of sensitive images without compromising image quality.
Deep Koopman-layered Model with Universal Property Based on Toeplitz Matrices
Oct 03, 2024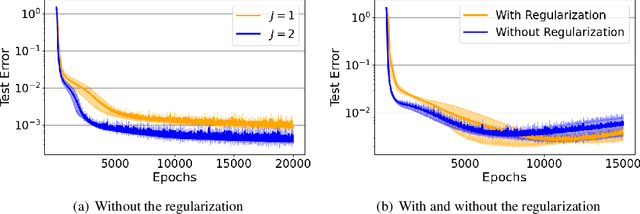
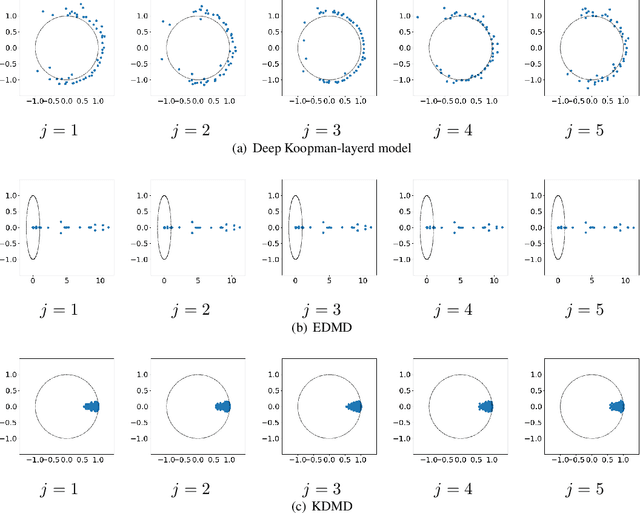
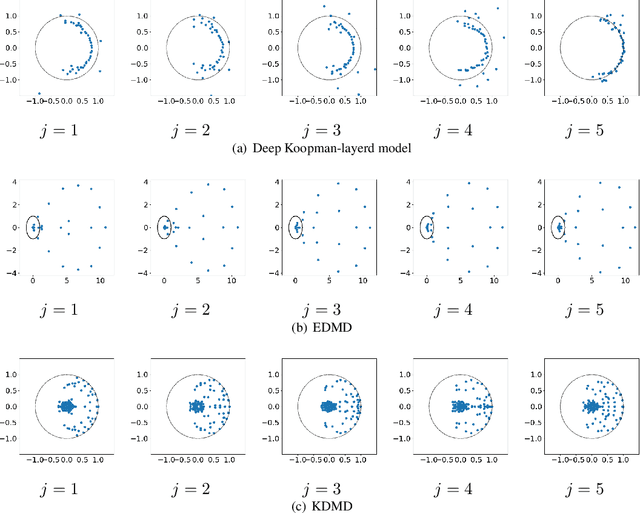
We propose deep Koopman-layered models with learnable parameters in the form of Toeplitz matrices for analyzing the dynamics of time-series data. The proposed model has both theoretical solidness and flexibility. By virtue of the universal property of Toeplitz matrices and the reproducing property underlined in the model, we can show its universality and the generalization property. In addition, the flexibility of the proposed model enables the model to fit time-series data coming from nonautonomous dynamical systems. When training the model, we apply Krylov subspace methods for efficient computations. In addition, the proposed model can be regarded as a neural ODE-based model. In this sense, the proposed model establishes a new connection among Koopman operators, neural ODEs, and numerical linear algebraic methods.
Meta-learning for Positive-unlabeled Classification
Jun 06, 2024



We propose a meta-learning method for positive and unlabeled (PU) classification, which improves the performance of binary classifiers obtained from only PU data in unseen target tasks. PU learning is an important problem since PU data naturally arise in real-world applications such as outlier detection and information retrieval. Existing PU learning methods require many PU data, but sufficient data are often unavailable in practice. The proposed method minimizes the test classification risk after the model is adapted to PU data by using related tasks that consist of positive, negative, and unlabeled data. We formulate the adaptation as an estimation problem of the Bayes optimal classifier, which is an optimal classifier to minimize the classification risk. The proposed method embeds each instance into a task-specific space using neural networks. With the embedded PU data, the Bayes optimal classifier is estimated through density-ratio estimation of PU densities, whose solution is obtained as a closed-form solution. The closed-form solution enables us to efficiently and effectively minimize the test classification risk. We empirically show that the proposed method outperforms existing methods with one synthetic and three real-world datasets.
Deep Positive-Unlabeled Anomaly Detection for Contaminated Unlabeled Data
May 29, 2024
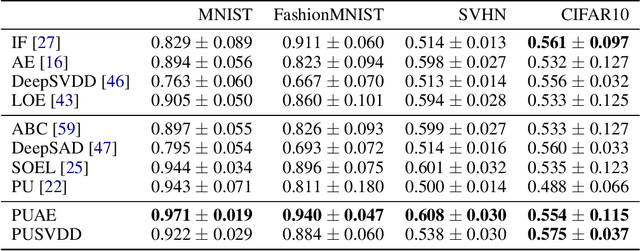


Semi-supervised anomaly detection, which aims to improve the performance of the anomaly detector by using a small amount of anomaly data in addition to unlabeled data, has attracted attention. Existing semi-supervised approaches assume that unlabeled data are mostly normal. They train the anomaly detector to minimize the anomaly scores for the unlabeled data, and to maximize those for the anomaly data. However, in practice, the unlabeled data are often contaminated with anomalies. This weakens the effect of maximizing the anomaly scores for anomalies, and prevents us from improving the detection performance. To solve this problem, we propose the positive-unlabeled autoencoder, which is based on positive-unlabeled learning and the anomaly detector such as the autoencoder. With our approach, we can approximate the anomaly scores for normal data using the unlabeled and anomaly data. Therefore, without the labeled normal data, we can train the anomaly detector to minimize the anomaly scores for normal data, and to maximize those for the anomaly data. In addition, our approach is applicable to various anomaly detectors such as the DeepSVDD. Experiments on various datasets show that our approach achieves better detection performance than existing approaches.
Neural Operators Meet Energy-based Theory: Operator Learning for Hamiltonian and Dissipative PDEs
Feb 14, 2024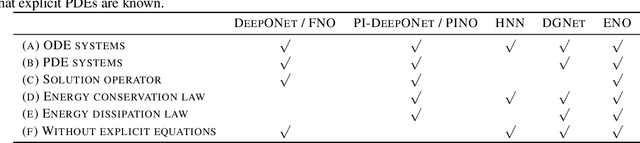

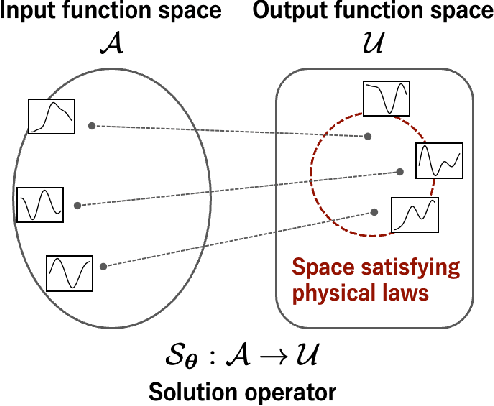
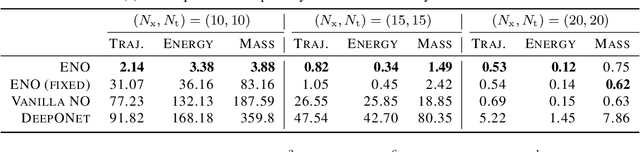
The operator learning has received significant attention in recent years, with the aim of learning a mapping between function spaces. Prior works have proposed deep neural networks (DNNs) for learning such a mapping, enabling the learning of solution operators of partial differential equations (PDEs). However, these works still struggle to learn dynamics that obeys the laws of physics. This paper proposes Energy-consistent Neural Operators (ENOs), a general framework for learning solution operators of PDEs that follows the energy conservation or dissipation law from observed solution trajectories. We introduce a novel penalty function inspired by the energy-based theory of physics for training, in which the energy functional is modeled by another DNN, allowing one to bias the outputs of the DNN-based solution operators to ensure energetic consistency without explicit PDEs. Experiments on multiple physical systems show that ENO outperforms existing DNN models in predicting solutions from data, especially in super-resolution settings.