 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-learning Representations for Learning from Multiple Annotators
Jun 12, 2025



We propose a meta-learning method for learning from multiple noisy annotators. In many applications such as crowdsourcing services, labels for supervised learning are given by multiple annotators. Since the annotators have different skills or biases, given labels can be noisy. To learn accurate classifiers, existing methods require many noisy annotated data. However, sufficient data might be unavailable in practice. To overcome the lack of data, the proposed method uses labeled data obtained in different but related tasks. The proposed method embeds each example in tasks to a latent space by using a neural network and constructs a probabilistic model for learning a task-specific classifier while estimating annotators' abilities on the latent space. This neural network is meta-learned to improve the expected test classification performance when the classifier is adapted to a given small amount of annotated data. This classifier adaptation is performed by maximizing the posterior probability via the expectation-maximization (EM) algorithm. Since each step in the EM algorithm is easily computed as a closed-form and is differentiable, the proposed method can efficiently backpropagate the loss through the EM algorithm to meta-learn the neural network. We show the effectiveness of our method with real-world datasets with synthetic noise and real-world crowdsourcing datasets.
Zero-shot Concept Bottleneck Models
Feb 13, 2025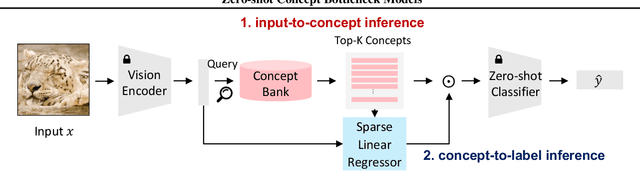

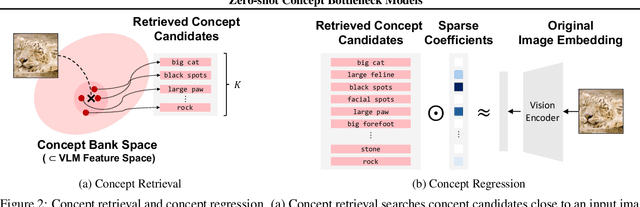

Concept bottleneck models (CBMs) are inherently interpretable and intervenable neural network models, which explain their final label prediction by the intermediate prediction of high-level semantic concepts. However, they require target task training to learn input-to-concept and concept-to-label mappings, incurring target dataset collections and training resources. In this paper, we present \textit{zero-shot concept bottleneck models} (Z-CBMs), which predict concepts and labels in a fully zero-shot manner without training neural networks. Z-CBMs utilize a large-scale concept bank, which is composed of millions of vocabulary extracted from the web, to describe arbitrary input in various domains. For the input-to-concept mapping, we introduce concept retrieval, which dynamically finds input-related concepts by the cross-modal search on the concept bank. In the concept-to-label inference, we apply concept regression to select essential concepts from the retrieved concepts by sparse linear regression. Through extensive experiments, we confirm that our Z-CBMs provide interpretable and intervenable concepts without any additional training. Code will be available at https://github.com/yshinya6/zcbm.
Evaluating Time-Series Training Dataset through Lens of Spectrum in Deep State Space Models
Aug 29, 2024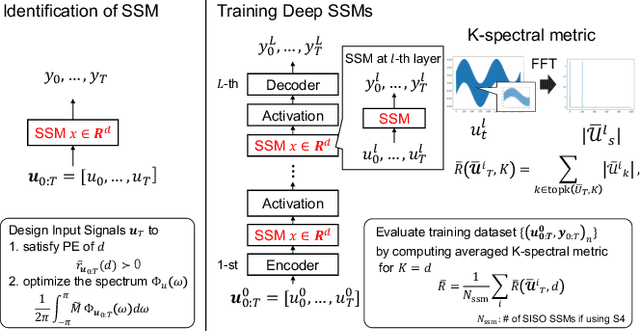

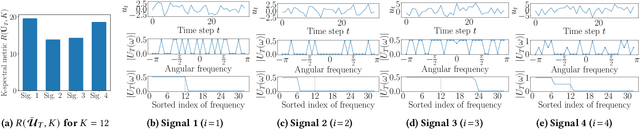
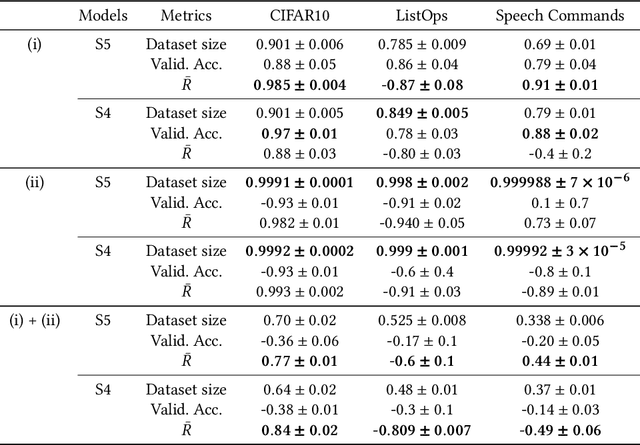
This study investigates a method to evaluate time-series datasets in terms of the performance of deep neural networks (DNNs) with state space models (deep SSMs) trained on the dataset. SSMs have attracted attention as components inside DNNs to address time-series data. Since deep SSMs have powerful representation capacities, training datasets play a crucial role in solving a new task. However, the effectiveness of training datasets cannot be known until deep SSMs are actually trained on them. This can increase the cost of data collection for new tasks, as a trial-and-error process of data collection and time-consuming training are needed to achieve the necessary performance. To advance the practical use of deep SSMs, the metric of datasets to estimate the performance early in the training can be one key element. To this end, we introduce the concept of data evaluation methods used in system identification. In system identification of linear dynamical systems, the effectiveness of datasets is evaluated by using the spectrum of input signals. We introduce this concept to deep SSMs, which are nonlinear dynamical systems. We propose the K-spectral metric, which is the sum of the top-K spectra of signals inside deep SSMs, by focusing on the fact that each layer of a deep SSM can be regarded as a linear dynamical system. Our experiments show that the K-spectral metric has a large absolute value of the correlation coefficient with the performance and can be used to evaluate the quality of training datasets.
Fast Regularized Discrete Optimal Transport with Group-Sparse Regularizers
Mar 14, 2023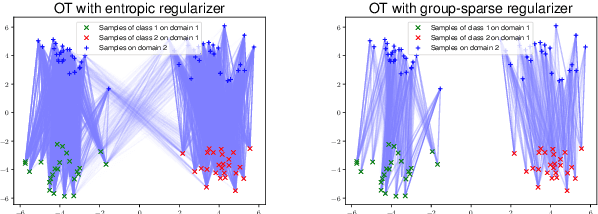
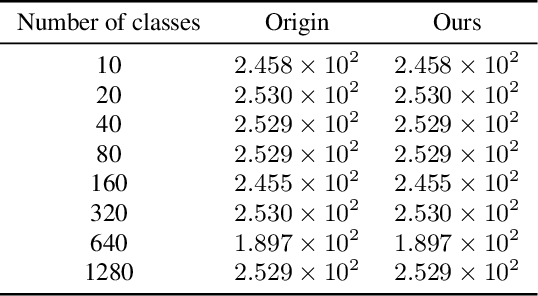
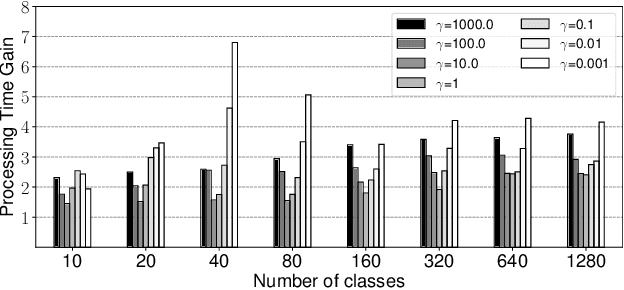
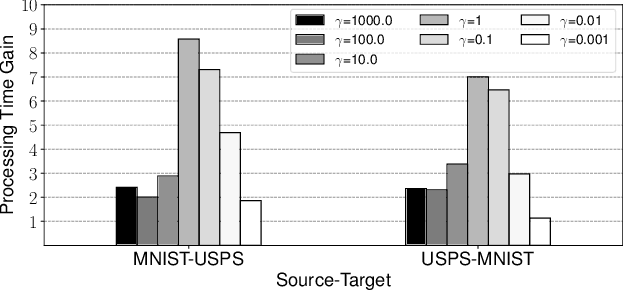
Regularized discrete optimal transport (OT) is a powerful tool to measure the distance between two discrete distributions that have been constructed from data samples on two different domains. While it has a wide range of applications in machine learning, in some cases the sampled data from only one of the domains will have class labels such as unsupervised domain adaptation. In this kind of problem setting, a group-sparse regularizer is frequently leveraged as a regularization term to handle class labels. In particular, it can preserve the label structure on the data samples by corresponding the data samples with the same class label to one group-sparse regularization term. As a result, we can measure the distance while utilizing label information by solving the regularized optimization problem with gradient-based algorithms. However, the gradient computation is expensive when the number of classes or data samples is large because the number of regularization terms and their respective sizes also turn out to be large. This paper proposes fast discrete OT with group-sparse regularizers. Our method is based on two ideas. The first is to safely skip the computations of the gradients that must be zero. The second is to efficiently extract the gradients that are expected to be nonzero. Our method is guaranteed to return the same value of the objective function as that of the original method. Experiments show that our method is up to 8.6 times faster than the original method without degrading accuracy.
Fast Saturating Gate for Learning Long Time Scales with Recurrent Neural Networks
Oct 04, 2022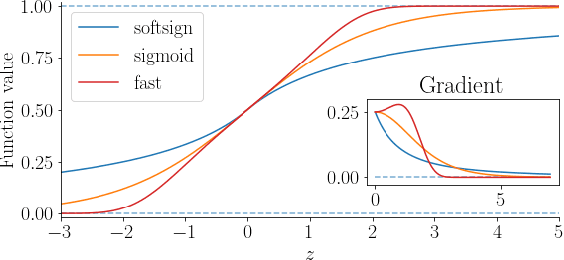

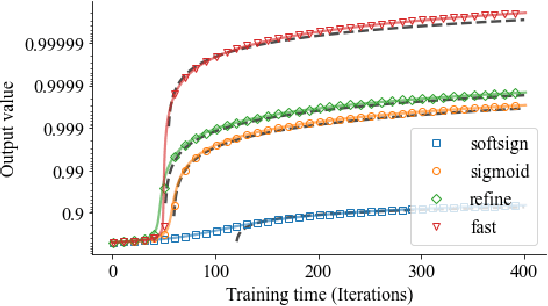
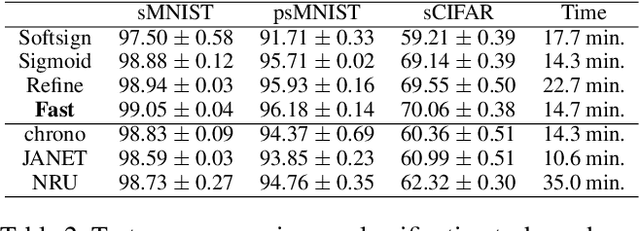
Gate functions in recurrent models, such as an LSTM and GRU, play a central role in learning various time scales in modeling time series data by using a bounded activation function. However, it is difficult to train gates to capture extremely long time scales due to gradient vanishing of the bounded function for large inputs, which is known as the saturation problem. We closely analyze the relation between saturation of the gate function and efficiency of the training. We prove that the gradient vanishing of the gate function can be mitigated by accelerating the convergence of the saturating function, i.e., making the output of the function converge to 0 or 1 faster. Based on the analysis results, we propose a gate function called fast gate that has a doubly exponential convergence rate with respect to inputs by simple function composition. We empirically show that our method outperforms previous methods in accuracy and computational efficiency on benchmark tasks involving extremely long time scales.
Switching One-Versus-the-Rest Loss to Increase the Margin of Logits for Adversarial Robustness
Jul 21, 2022
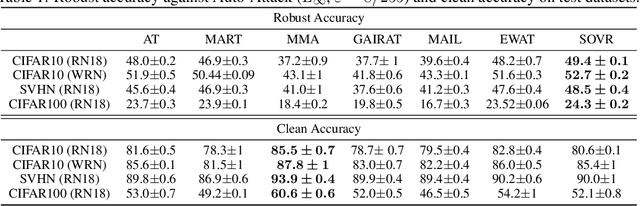


Defending deep neural networks against adversarial examples is a key challenge for AI safety. To improve the robustness effectively, recent methods focus on important data points near the decision boundary in adversarial training. However, these methods are vulnerable to Auto-Attack, which is an ensemble of parameter-free attacks for reliable evaluation. In this paper, we experimentally investigate the causes of their vulnerability and find that existing methods reduce margins between logits for the true label and the other labels while keeping their gradient norms non-small values. Reduced margins and non-small gradient norms cause their vulnerability since the largest logit can be easily flipped by the perturbation. Our experiments also show that the histogram of the logit margins has two peaks, i.e., small and large logit margins. From the observations, we propose switching one-versus-the-rest loss (SOVR), which uses one-versus-the-rest loss when data have small logit margins so that it increases the margins. We find that SOVR increases logit margins more than existing methods while keeping gradient norms small and outperforms them in terms of the robustness against Auto-Attack.
Meta-ticket: Finding optimal subnetworks for few-shot learning within randomly initialized neural networks
May 31, 2022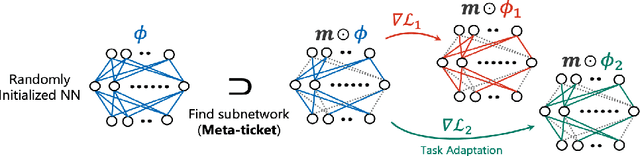
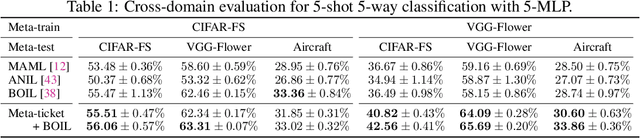

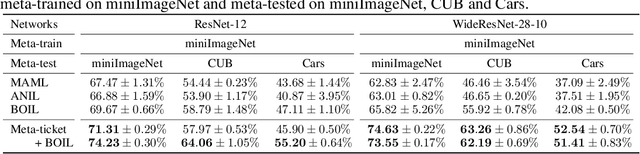
Few-shot learning for neural networks (NNs) is an important problem that aims to train NNs with a few data. The main challenge is how to avoid overfitting since over-parameterized NNs can easily overfit to such small dataset. Previous work (e.g. MAML by Finn et al. 2017) tackles this challenge by meta-learning, which learns how to learn from a few data by using various tasks. On the other hand, one conventional approach to avoid overfitting is restricting hypothesis spaces by endowing sparse NN structures like convolution layers in computer vision. However, although such manually-designed sparse structures are sample-efficient for sufficiently large datasets, they are still insufficient for few-shot learning. Then the following questions naturally arise: (1) Can we find sparse structures effective for few-shot learning by meta-learning? (2) What benefits will it bring in terms of meta-generalization? In this work, we propose a novel meta-learning approach, called Meta-ticket, to find optimal sparse subnetworks for few-shot learning within randomly initialized NNs. We empirically validated that Meta-ticket successfully discover sparse subnetworks that can learn specialized features for each given task. Due to this task-wise adaptation ability, Meta-ticket achieves superior meta-generalization compared to MAML-based methods especially with large NNs.
Pruning Randomly Initialized Neural Networks with Iterative Randomization
Jun 17, 2021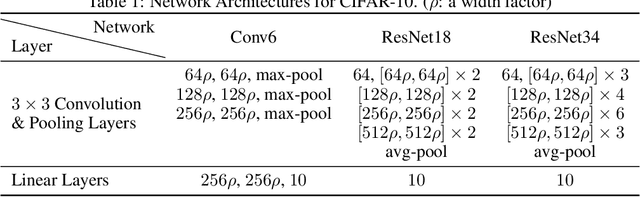
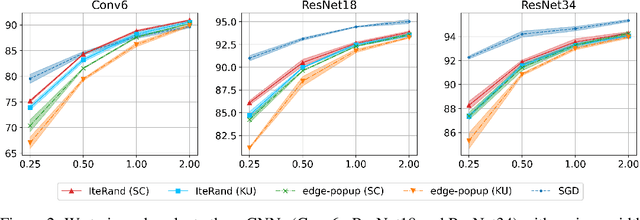


Pruning the weights of randomly initialized neural networks plays an important role in the context of lottery ticket hypothesis. Ramanujan et al. (2020) empirically showed that only pruning the weights can achieve remarkable performance instead of optimizing the weight values. However, to achieve the same level of performance as the weight optimization, the pruning approach requires more parameters in the networks before pruning and thus more memory space. To overcome this parameter inefficiency, we introduce a novel framework to prune randomly initialized neural networks with iteratively randomizing weight values (IteRand). Theoretically, we prove an approximation theorem in our framework, which indicates that the randomizing operations are provably effective to reduce the required number of the parameters. We also empirically demonstrate the parameter efficiency in multiple experiments on CIFAR-10 and ImageNet.
Smoothness Analysis of Loss Functions of Adversarial Training
Mar 02, 2021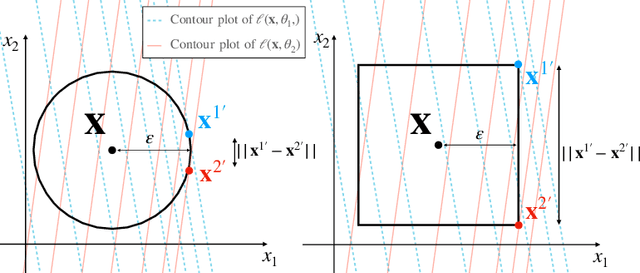
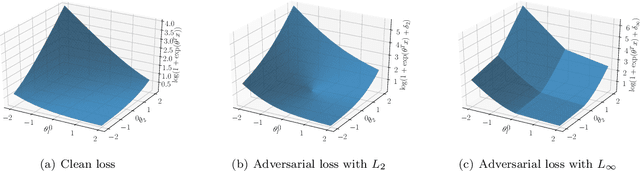
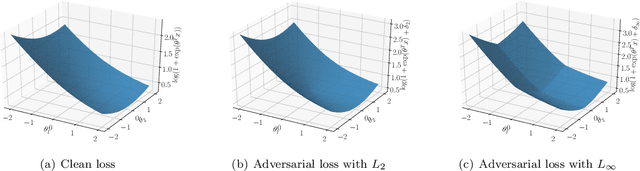
Deep neural networks are vulnerable to adversarial attacks. Recent studies of adversarial robustness focus on the loss landscape in the parameter space since it is related to optimization performance. These studies conclude that it is hard to optimize the loss function for adversarial training with respect to parameters because the loss function is not smooth: i.e., its gradient is not Lipschitz continuous. However, this analysis ignores the dependence of adversarial attacks on parameters. Since adversarial attacks are the worst noise for the models, they should depend on the parameters of the models. In this study, we analyze the smoothness of the loss function of adversarial training for binary linear classification considering the dependence. We reveal that the Lipschitz continuity depends on the types of constraints of adversarial attacks in this case. Specifically, under the L2 constraints, the adversarial loss is smooth except at zero.
Constraining Logits by Bounded Function for Adversarial Robustness
Oct 06, 2020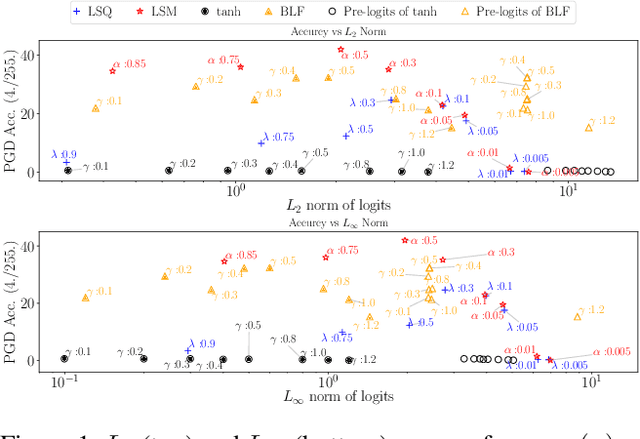
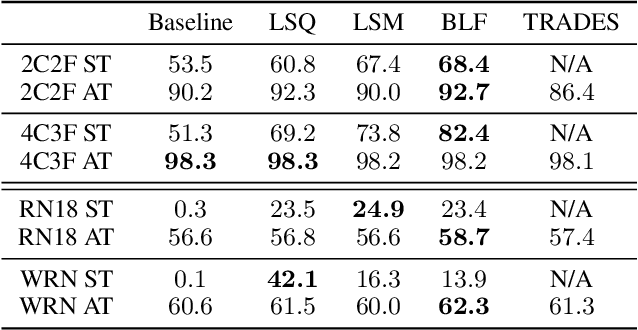
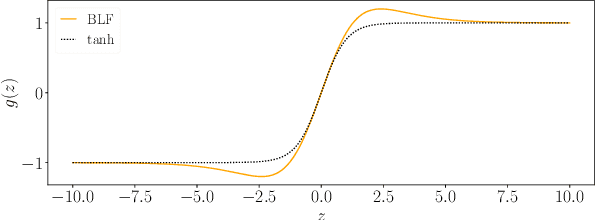
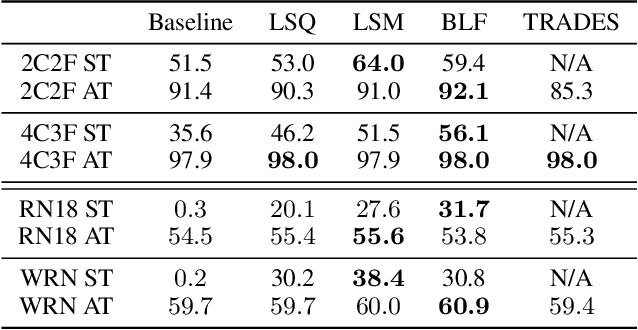
We propose a method for improving adversarial robustness by addition of a new bounded function just before softmax. Recent studies hypothesize that small logits (inputs of softmax) by logit regularization can improve adversarial robustness of deep learning. Following this hypothesis, we analyze norms of logit vectors at the optimal point under the assumption of universal approximation and explore new methods for constraining logits by addition of a bounded function before softmax. We theoretically and empirically reveal that small logits by addition of a common activation function, e.g., hyperbolic tangent, do not improve adversarial robustness since input vectors of the function (pre-logit vectors) can have large norms. From the theoretical findings, we develop the new bounded function. The addition of our function improves adversarial robustness because it makes logit and pre-logit vectors have small norms. Since our method only adds one activation function before softmax, it is easy to combine our method with adversarial training. Our experiments demonstrate that our method is comparable to logit regularization methods in terms of accuracies on adversarially perturbed datasets without adversarial training. Furthermore, it is superior or comparable to logit regularization methods and a recent defense method (TRADES) when using adversarial training.