 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmoothness Analysis of Loss Functions of Adversarial Training
Mar 02, 2021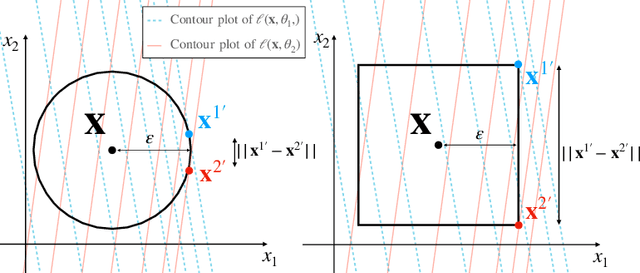
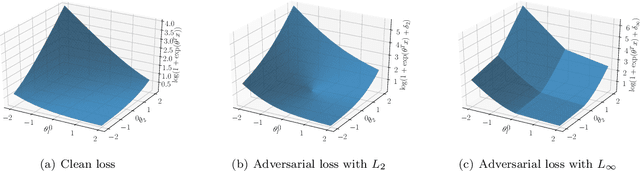
Deep neural networks are vulnerable to adversarial attacks. Recent studies of adversarial robustness focus on the loss landscape in the parameter space since it is related to optimization performance. These studies conclude that it is hard to optimize the loss function for adversarial training with respect to parameters because the loss function is not smooth: i.e., its gradient is not Lipschitz continuous. However, this analysis ignores the dependence of adversarial attacks on parameters. Since adversarial attacks are the worst noise for the models, they should depend on the parameters of the models. In this study, we analyze the smoothness of the loss function of adversarial training for binary linear classification considering the dependence. We reveal that the Lipschitz continuity depends on the types of constraints of adversarial attacks in this case. Specifically, under the L2 constraints, the adversarial loss is smooth except at zero.
Adversarial Training Makes Weight Loss Landscape Sharper in Logistic Regression
Feb 05, 2021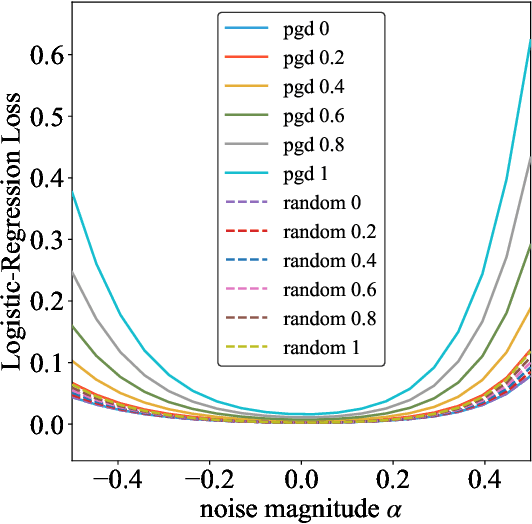
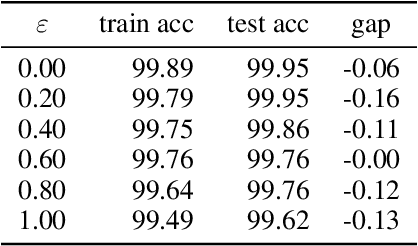
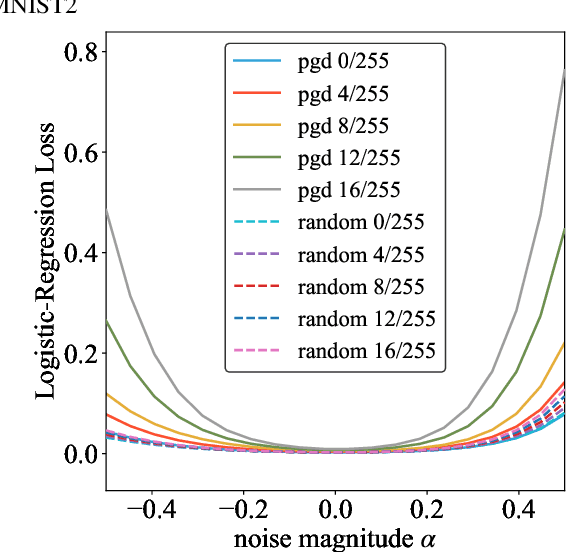
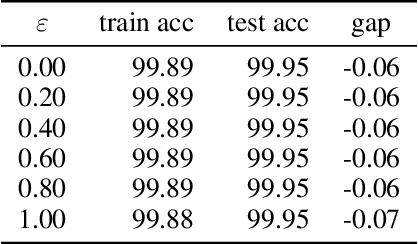
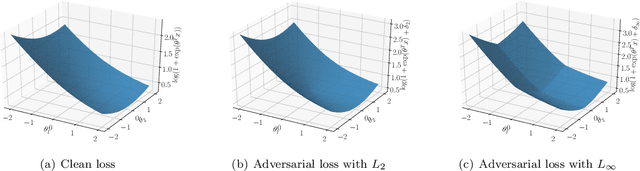
Adversarial training is actively studied for learning robust models against adversarial examples. A recent study finds that adversarially trained models degenerate generalization performance on adversarial examples when their weight loss landscape, which is loss changes with respect to weights, is sharp. Unfortunately, it has been experimentally shown that adversarial training sharpens the weight loss landscape, but this phenomenon has not been theoretically clarified. Therefore, we theoretically analyze this phenomenon in this paper. As a first step, this paper proves that adversarial training with the L2 norm constraints sharpens the weight loss landscape in the linear logistic regression model. Our analysis reveals that the sharpness of the weight loss landscape is caused by the noise aligned in the direction of increasing the loss, which is used in adversarial training. We theoretically and experimentally confirm that the weight loss landscape becomes sharper as the magnitude of the noise of adversarial training increases in the linear logistic regression model. Moreover, we experimentally confirm the same phenomena in ResNet18 with softmax as a more general case.
Supervised Anomaly Detection based on Deep Autoregressive Density Estimators
Apr 12, 2019
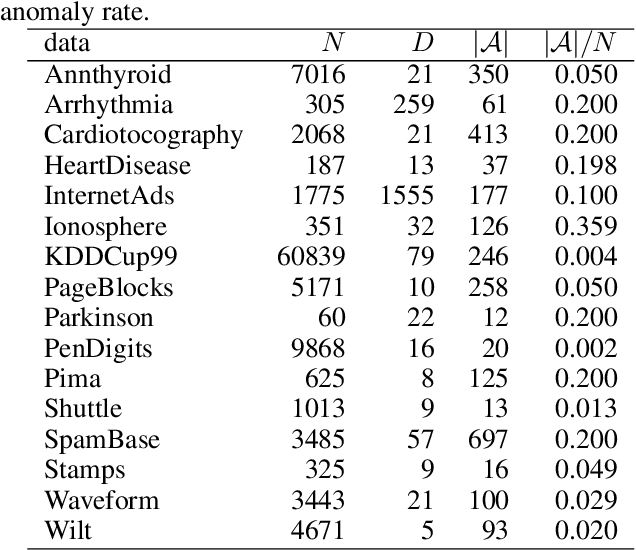
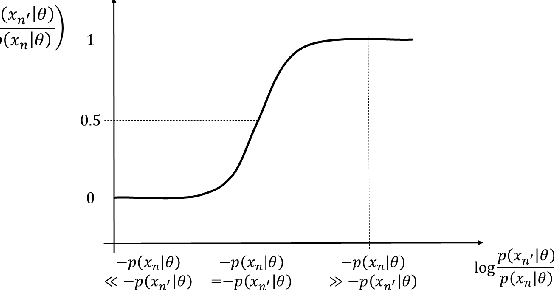
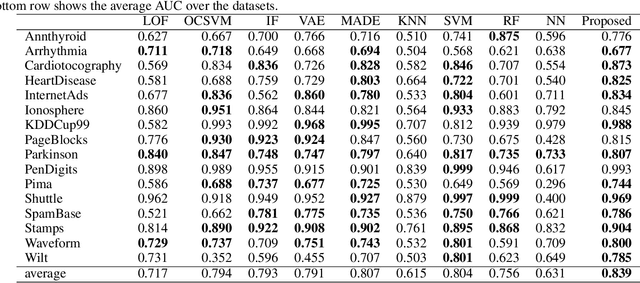
We propose a supervised anomaly detection method based on neural density estimators, where the negative log likelihood is used for the anomaly score. Density estimators have been widely used for unsupervised anomaly detection. By the recent advance of deep learning, the density estimation performance has been greatly improved. However, the neural density estimators cannot exploit anomaly label information, which would be valuable for improving the anomaly detection performance. The proposed method effectively utilizes the anomaly label information by training the neural density estimator so that the likelihood of normal instances is maximized and the likelihood of anomalous instances is lower than that of the normal instances. We employ an autoregressive model for the neural density estimator, which enables us to calculate the likelihood exactly. With the experiments using 16 datasets, we demonstrate that the proposed method improves the anomaly detection performance with a few labeled anomalous instances, and achieves better performance than existing unsupervised and supervised anomaly detection methods.
Autoencoding Binary Classifiers for Supervised Anomaly Detection
Mar 26, 2019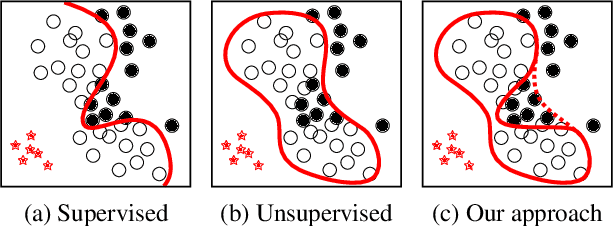
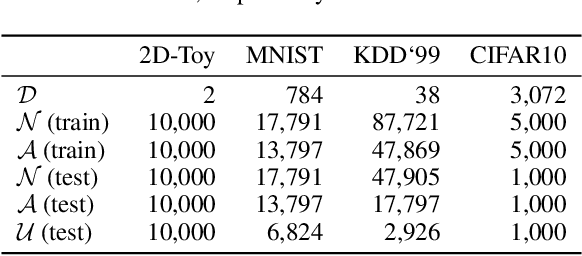
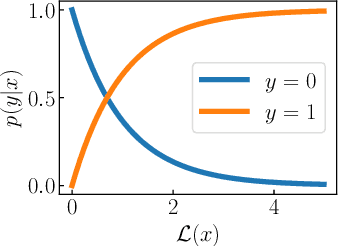
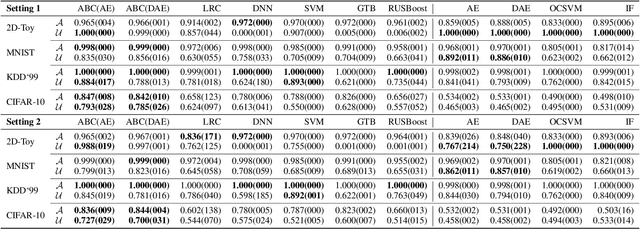
We propose the Autoencoding Binary Classifiers (ABC), a novel supervised anomaly detector based on the Autoencoder (AE). There are two main approaches in anomaly detection: supervised and unsupervised. The supervised approach accurately detects the known anomalies included in training data, but it cannot detect the unknown anomalies. Meanwhile, the unsupervised approach can detect both known and unknown anomalies that are located away from normal data points. However, it does not detect known anomalies as accurately as the supervised approach. Furthermore, even if we have labeled normal data points and anomalies, the unsupervised approach cannot utilize these labels. The ABC is a probabilistic binary classifier that effectively exploits the label information, where normal data points are modeled using the AE as a component. By maximizing the likelihood, the AE in the proposed ABC is trained to minimize the reconstruction error for normal data points, and to maximize it for known anomalies. Since our approach becomes able to reconstruct the normal data points accurately and fails to reconstruct the known and unknown anomalies, it can accurately discriminate both known and unknown anomalies from normal data points. Experimental results show that the ABC achieves higher detection performance than existing supervised and unsupervised methods.
Variational Autoencoder with Implicit Optimal Priors
Sep 14, 2018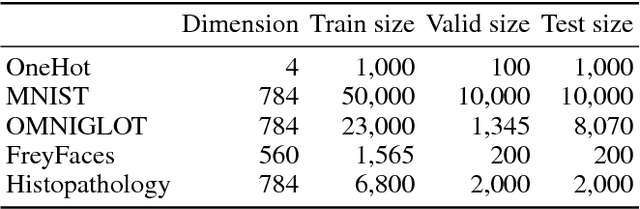
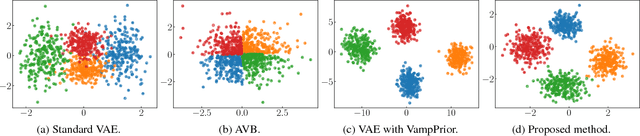
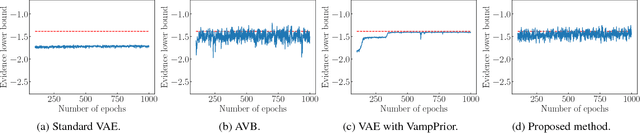

The variational autoencoder (VAE) is a powerful generative model that can estimate the probability of a data point by using latent variables. In the VAE, the posterior of the latent variable given the data point is regularized by the prior of the latent variable using Kullback Leibler (KL) divergence. Although the standard Gaussian distribution is usually used for the prior, this simple prior incurs over-regularization. As a sophisticated prior, the aggregated posterior has been introduced, which is the expectation of the posterior over the data distribution. This prior is optimal for the VAE in terms of maximizing the training objective function. However, KL divergence with the aggregated posterior cannot be calculated in a closed form, which prevents us from using this optimal prior. With the proposed method, we introduce the density ratio trick to estimate this KL divergence without modeling the aggregated posterior explicitly. Since the density ratio trick does not work well in high dimensions, we rewrite this KL divergence that contains the high-dimensional density ratio into the sum of the analytically calculable term and the low-dimensional density ratio term, to which the density ratio trick is applied. Experiments on various datasets show that the VAE with this implicit optimal prior achieves high density estimation performance.
Sigsoftmax: Reanalysis of the Softmax Bottleneck
May 28, 2018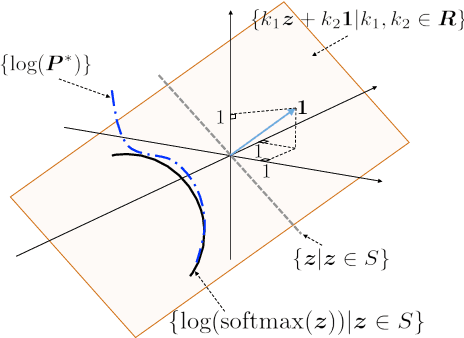



Softmax is an output activation function for modeling categorical probability distributions in many applications of deep learning. However, a recent study revealed that softmax can be a bottleneck of representational capacity of neural networks in language modeling (the softmax bottleneck). In this paper, we propose an output activation function for breaking the softmax bottleneck without additional parameters. We re-analyze the softmax bottleneck from the perspective of the output set of log-softmax and identify the cause of the softmax bottleneck. On the basis of this analysis, we propose sigsoftmax, which is composed of a multiplication of an exponential function and sigmoid function. Sigsoftmax can break the softmax bottleneck. The experiments on language modeling demonstrate that sigsoftmax and mixture of sigsoftmax outperform softmax and mixture of softmax, respectively.