 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo We Really Need Permutations? Impact of Width Expansion on Linear Mode Connectivity
Oct 09, 2025Recently, Ainsworth et al. empirically demonstrated that, given two independently trained models, applying a parameter permutation that preserves the input-output behavior allows the two models to be connected by a low-loss linear path. When such a path exists, the models are said to achieve linear mode connectivity (LMC). Prior studies, including Ainsworth et al., have reported that achieving LMC requires not only an appropriate permutation search but also sufficiently wide models (e.g., a 32 $\times$ width multiplier for ResNet-20). This is broadly believed to be because increasing the model width ensures a large enough space of candidate permutations, increasing the chance of finding one that yields LMC. In this work, we empirically demonstrate that, even without any permutations, simply widening the models is sufficient for achieving LMC when using a suitable softmax temperature calibration. We further explain why this phenomenon arises by analyzing intermediate layer outputs. Specifically, we introduce layerwise exponentially weighted connectivity (LEWC), which states that the output of each layer of the merged model can be represented as an exponentially weighted sum of the outputs of the corresponding layers of the original models. Consequently the merged model's output matches that of an ensemble of the original models, which facilitates LMC. To the best of our knowledge, this work is the first to show that widening the model not only facilitates nonlinear mode connectivity, as suggested in prior research, but also significantly increases the possibility of achieving linear mode connectivity.
Sparse-Autoencoder-Guided Internal Representation Unlearning for Large Language Models
Sep 19, 2025As large language models (LLMs) are increasingly deployed across various applications, privacy and copyright concerns have heightened the need for more effective LLM unlearning techniques. Many existing unlearning methods aim to suppress undesirable outputs through additional training (e.g., gradient ascent), which reduces the probability of generating such outputs. While such suppression-based approaches can control model outputs, they may not eliminate the underlying knowledge embedded in the model's internal activations; muting a response is not the same as forgetting it. Moreover, such suppression-based methods often suffer from model collapse. To address these issues, we propose a novel unlearning method that directly intervenes in the model's internal activations. In our formulation, forgetting is defined as a state in which the activation of a forgotten target is indistinguishable from that of ``unknown'' entities. Our method introduces an unlearning objective that modifies the activation of the target entity away from those of known entities and toward those of unknown entities in a sparse autoencoder latent space. By aligning the target's internal activation with those of unknown entities, we shift the model's recognition of the target entity from ``known'' to ``unknown'', achieving genuine forgetting while avoiding over-suppression and model collapse. Empirically, we show that our method effectively aligns the internal activations of the forgotten target, a result that the suppression-based approaches do not reliably achieve. Additionally, our method effectively reduces the model's recall of target knowledge in question-answering tasks without significant damage to the non-target knowledge.
Concept Unlearning in Large Language Models via Self-Constructed Knowledge Triplets
Sep 19, 2025Machine Unlearning (MU) has recently attracted considerable attention as a solution to privacy and copyright issues in large language models (LLMs). Existing MU methods aim to remove specific target sentences from an LLM while minimizing damage to unrelated knowledge. However, these approaches require explicit target sentences and do not support removing broader concepts, such as persons or events. To address this limitation, we introduce Concept Unlearning (CU) as a new requirement for LLM unlearning. We leverage knowledge graphs to represent the LLM's internal knowledge and define CU as removing the forgetting target nodes and associated edges. This graph-based formulation enables a more intuitive unlearning and facilitates the design of more effective methods. We propose a novel method that prompts the LLM to generate knowledge triplets and explanatory sentences about the forgetting target and applies the unlearning process to these representations. Our approach enables more precise and comprehensive concept removal by aligning the unlearning process with the LLM's internal knowledge representations. Experiments on real-world and synthetic datasets demonstrate that our method effectively achieves concept-level unlearning while preserving unrelated knowledge.
Analysis of Linear Mode Connectivity via Permutation-Based Weight Matching
Feb 19, 2024Recently, Ainsworth et al. showed that using weight matching (WM) to minimize the $L_2$ distance in a permutation search of model parameters effectively identifies permutations that satisfy linear mode connectivity (LMC), in which the loss along a linear path between two independently trained models with different seeds remains nearly constant. This paper provides a theoretical analysis of LMC using WM, which is crucial for understanding stochastic gradient descent's effectiveness and its application in areas like model merging. We first experimentally and theoretically show that permutations found by WM do not significantly reduce the $L_2$ distance between two models and the occurrence of LMC is not merely due to distance reduction by WM in itself. We then provide theoretical insights showing that permutations can change the directions of the singular vectors, but not the singular values, of the weight matrices in each layer. This finding shows that permutations found by WM mainly align the directions of singular vectors associated with large singular values across models. This alignment brings the singular vectors with large singular values, which determine the model functionality, closer between pre-merged and post-merged models, so that the post-merged model retains functionality similar to the pre-merged models, making it easy to satisfy LMC. Finally, we analyze the difference between WM and straight-through estimator (STE), a dataset-dependent permutation search method, and show that WM outperforms STE, especially when merging three or more models.
Revisiting Permutation Symmetry for Merging Models between Different Datasets
Jun 09, 2023
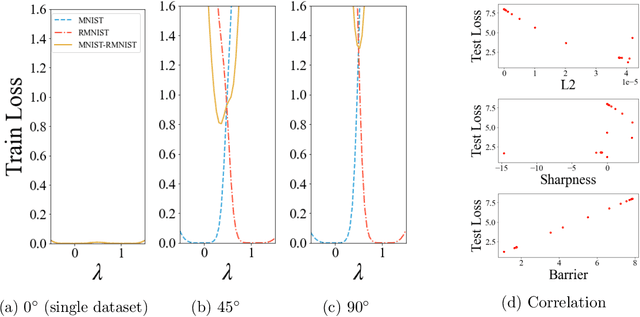


Model merging is a new approach to creating a new model by combining the weights of different trained models. Previous studies report that model merging works well for models trained on a single dataset with different random seeds, while model merging between different datasets is difficult. Merging knowledge from different datasets has practical significance, but it has not been well investigated. In this paper, we investigate the properties of merging models between different datasets. Through theoretical and empirical analyses, we find that the accuracy of the merged model decreases more significantly as the datasets diverge more and that the different loss landscapes for each dataset make model merging between different datasets difficult. We also show that merged models require datasets for merging in order to achieve a high accuracy. Furthermore, we show that condensed datasets created by dataset condensation can be used as substitutes for the original datasets when merging models. We conduct experiments for model merging between different datasets. When merging between MNIST and Fashion- MNIST models, the accuracy significantly improves by 28% using the dataset and 25% using the condensed dataset compared with not using the dataset.
One-Shot Machine Unlearning with Mnemonic Code
Jun 09, 2023



Deep learning has achieved significant improvements in accuracy and has been applied to various fields. With the spread of deep learning, a new problem has also emerged; deep learning models can sometimes have undesirable information from an ethical standpoint. This problem must be resolved if deep learning is to make sensitive decisions such as hiring and prison sentencing. Machine unlearning (MU) is the research area that responds to such demands. MU aims at forgetting about undesirable training data from a trained deep learning model. A naive MU approach is to re-train the whole model with the training data from which the undesirable data has been removed. However, re-training the whole model can take a huge amount of time and consumes significant computer resources. To make MU even more practical, a simple-yet-effective MU method is required. In this paper, we propose a one-shot MU method, which does not need additional training. To design one-shot MU, we add noise to the model parameters that are sensitive to undesirable information. In our proposed method, we use the Fisher information matrix (FIM) to estimate the sensitive model parameters. Training data were usually used to evaluate the FIM in existing methods. In contrast, we avoid the need to retain the training data for calculating the FIM by using class-specific synthetic signals called mnemonic code. Extensive experiments using artificial and natural datasets demonstrate that our method outperforms the existing methods.
ARDIR: Improving Robustness using Knowledge Distillation of Internal Representation
Nov 01, 2022
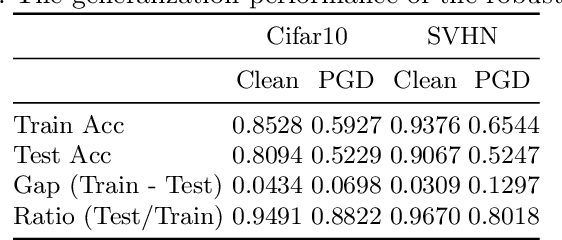


Adversarial training is the most promising method for learning robust models against adversarial examples. A recent study has shown that knowledge distillation between the same architectures is effective in improving the performance of adversarial training. Exploiting knowledge distillation is a new approach to improve adversarial training and has attracted much attention. However, its performance is still insufficient. Therefore, we propose Adversarial Robust Distillation with Internal Representation~(ARDIR) to utilize knowledge distillation even more effectively. In addition to the output of the teacher model, ARDIR uses the internal representation of the teacher model as a label for adversarial training. This enables the student model to be trained with richer, more informative labels. As a result, ARDIR can learn more robust student models. We show that ARDIR outperforms previous methods in our experiments.
Switching One-Versus-the-Rest Loss to Increase the Margin of Logits for Adversarial Robustness
Jul 21, 2022
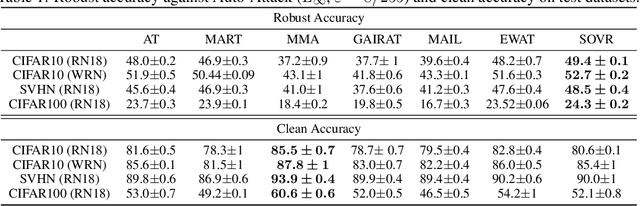


Defending deep neural networks against adversarial examples is a key challenge for AI safety. To improve the robustness effectively, recent methods focus on important data points near the decision boundary in adversarial training. However, these methods are vulnerable to Auto-Attack, which is an ensemble of parameter-free attacks for reliable evaluation. In this paper, we experimentally investigate the causes of their vulnerability and find that existing methods reduce margins between logits for the true label and the other labels while keeping their gradient norms non-small values. Reduced margins and non-small gradient norms cause their vulnerability since the largest logit can be easily flipped by the perturbation. Our experiments also show that the histogram of the logit margins has two peaks, i.e., small and large logit margins. From the observations, we propose switching one-versus-the-rest loss (SOVR), which uses one-versus-the-rest loss when data have small logit margins so that it increases the margins. We find that SOVR increases logit margins more than existing methods while keeping gradient norms small and outperforms them in terms of the robustness against Auto-Attack.
Smoothness Analysis of Loss Functions of Adversarial Training
Mar 02, 2021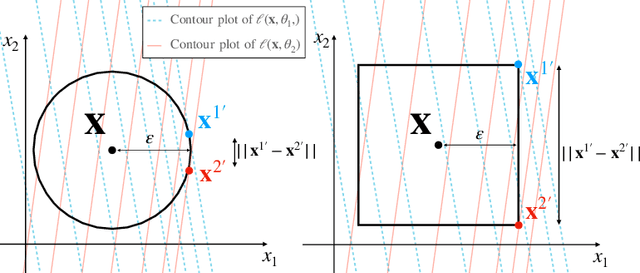
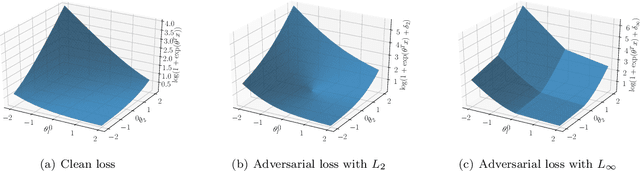
Deep neural networks are vulnerable to adversarial attacks. Recent studies of adversarial robustness focus on the loss landscape in the parameter space since it is related to optimization performance. These studies conclude that it is hard to optimize the loss function for adversarial training with respect to parameters because the loss function is not smooth: i.e., its gradient is not Lipschitz continuous. However, this analysis ignores the dependence of adversarial attacks on parameters. Since adversarial attacks are the worst noise for the models, they should depend on the parameters of the models. In this study, we analyze the smoothness of the loss function of adversarial training for binary linear classification considering the dependence. We reveal that the Lipschitz continuity depends on the types of constraints of adversarial attacks in this case. Specifically, under the L2 constraints, the adversarial loss is smooth except at zero.
Adversarial Training Makes Weight Loss Landscape Sharper in Logistic Regression
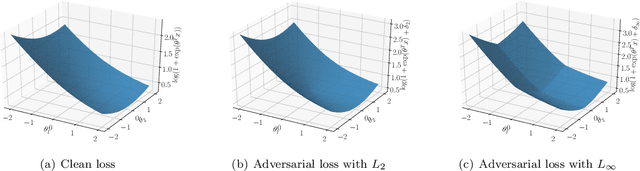
Feb 05, 2021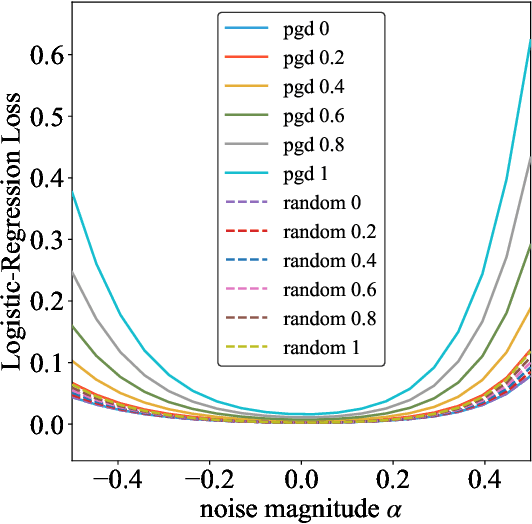
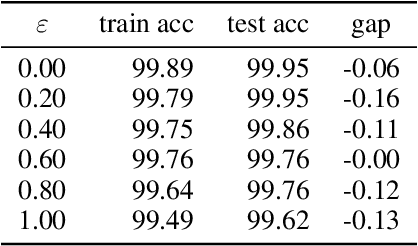
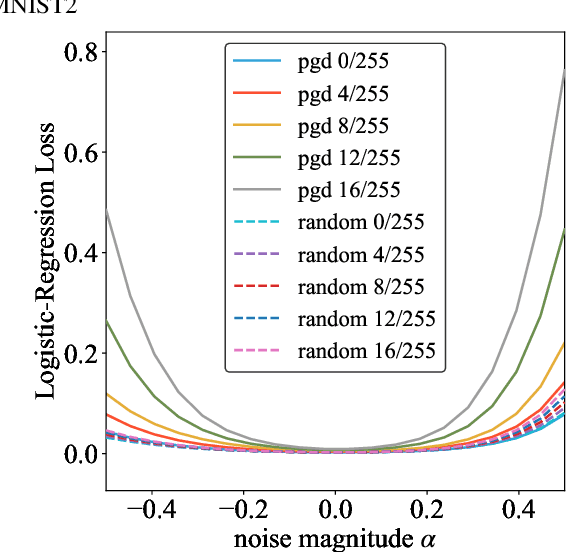
Adversarial training is actively studied for learning robust models against adversarial examples. A recent study finds that adversarially trained models degenerate generalization performance on adversarial examples when their weight loss landscape, which is loss changes with respect to weights, is sharp. Unfortunately, it has been experimentally shown that adversarial training sharpens the weight loss landscape, but this phenomenon has not been theoretically clarified. Therefore, we theoretically analyze this phenomenon in this paper. As a first step, this paper proves that adversarial training with the L2 norm constraints sharpens the weight loss landscape in the linear logistic regression model. Our analysis reveals that the sharpness of the weight loss landscape is caused by the noise aligned in the direction of increasing the loss, which is used in adversarial training. We theoretically and experimentally confirm that the weight loss landscape becomes sharper as the magnitude of the noise of adversarial training increases in the linear logistic regression model. Moreover, we experimentally confirm the same phenomena in ResNet18 with softmax as a more general case.