 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept Unlearning in Large Language Models via Self-Constructed Knowledge Triplets
Sep 19, 2025Machine Unlearning (MU) has recently attracted considerable attention as a solution to privacy and copyright issues in large language models (LLMs). Existing MU methods aim to remove specific target sentences from an LLM while minimizing damage to unrelated knowledge. However, these approaches require explicit target sentences and do not support removing broader concepts, such as persons or events. To address this limitation, we introduce Concept Unlearning (CU) as a new requirement for LLM unlearning. We leverage knowledge graphs to represent the LLM's internal knowledge and define CU as removing the forgetting target nodes and associated edges. This graph-based formulation enables a more intuitive unlearning and facilitates the design of more effective methods. We propose a novel method that prompts the LLM to generate knowledge triplets and explanatory sentences about the forgetting target and applies the unlearning process to these representations. Our approach enables more precise and comprehensive concept removal by aligning the unlearning process with the LLM's internal knowledge representations. Experiments on real-world and synthetic datasets demonstrate that our method effectively achieves concept-level unlearning while preserving unrelated knowledge.
Sparse-Autoencoder-Guided Internal Representation Unlearning for Large Language Models
Sep 19, 2025As large language models (LLMs) are increasingly deployed across various applications, privacy and copyright concerns have heightened the need for more effective LLM unlearning techniques. Many existing unlearning methods aim to suppress undesirable outputs through additional training (e.g., gradient ascent), which reduces the probability of generating such outputs. While such suppression-based approaches can control model outputs, they may not eliminate the underlying knowledge embedded in the model's internal activations; muting a response is not the same as forgetting it. Moreover, such suppression-based methods often suffer from model collapse. To address these issues, we propose a novel unlearning method that directly intervenes in the model's internal activations. In our formulation, forgetting is defined as a state in which the activation of a forgotten target is indistinguishable from that of ``unknown'' entities. Our method introduces an unlearning objective that modifies the activation of the target entity away from those of known entities and toward those of unknown entities in a sparse autoencoder latent space. By aligning the target's internal activation with those of unknown entities, we shift the model's recognition of the target entity from ``known'' to ``unknown'', achieving genuine forgetting while avoiding over-suppression and model collapse. Empirically, we show that our method effectively aligns the internal activations of the forgotten target, a result that the suppression-based approaches do not reliably achieve. Additionally, our method effectively reduces the model's recall of target knowledge in question-answering tasks without significant damage to the non-target knowledge.
Positive-Unlabeled Diffusion Models for Preventing Sensitive Data Generation
Mar 05, 2025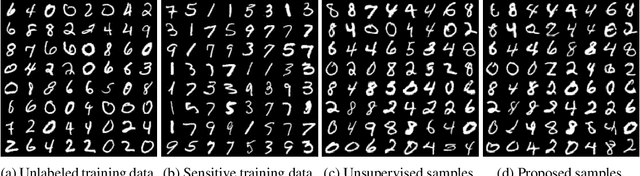
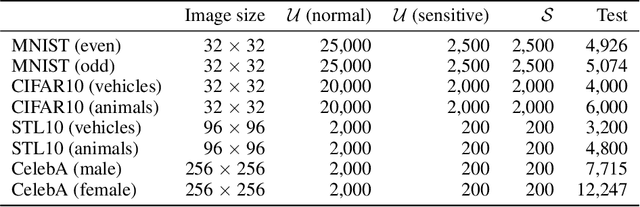
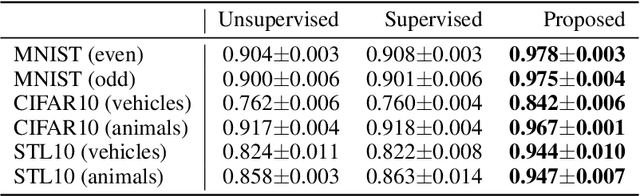

Diffusion models are powerful generative models but often generate sensitive data that are unwanted by users, mainly because the unlabeled training data frequently contain such sensitive data. Since labeling all sensitive data in the large-scale unlabeled training data is impractical, we address this problem by using a small amount of labeled sensitive data. In this paper, we propose positive-unlabeled diffusion models, which prevent the generation of sensitive data using unlabeled and sensitive data. Our approach can approximate the evidence lower bound (ELBO) for normal (negative) data using only unlabeled and sensitive (positive) data. Therefore, even without labeled normal data, we can maximize the ELBO for normal data and minimize it for labeled sensitive data, ensuring the generation of only normal data. Through experiments across various datasets and settings, we demonstrated that our approach can prevent the generation of sensitive images without compromising image quality.
Deep Positive-Unlabeled Anomaly Detection for Contaminated Unlabeled Data
May 29, 2024
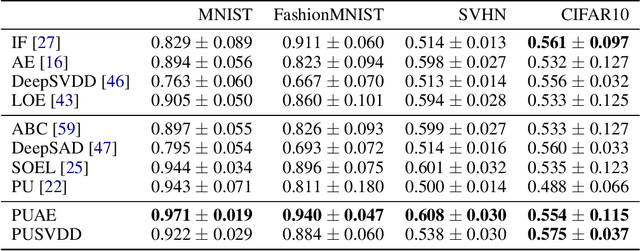


Semi-supervised anomaly detection, which aims to improve the performance of the anomaly detector by using a small amount of anomaly data in addition to unlabeled data, has attracted attention. Existing semi-supervised approaches assume that unlabeled data are mostly normal. They train the anomaly detector to minimize the anomaly scores for the unlabeled data, and to maximize those for the anomaly data. However, in practice, the unlabeled data are often contaminated with anomalies. This weakens the effect of maximizing the anomaly scores for anomalies, and prevents us from improving the detection performance. To solve this problem, we propose the positive-unlabeled autoencoder, which is based on positive-unlabeled learning and the anomaly detector such as the autoencoder. With our approach, we can approximate the anomaly scores for normal data using the unlabeled and anomaly data. Therefore, without the labeled normal data, we can train the anomaly detector to minimize the anomaly scores for normal data, and to maximize those for the anomaly data. In addition, our approach is applicable to various anomaly detectors such as the DeepSVDD. Experiments on various datasets show that our approach achieves better detection performance than existing approaches.
LogELECTRA: Self-supervised Anomaly Detection for Unstructured Logs
Feb 16, 2024



System logs are some of the most important information for the maintenance of software systems, which have become larger and more complex in recent years. The goal of log-based anomaly detection is to automatically detect system anomalies by analyzing the large number of logs generated in a short period of time, which is a critical challenge in the real world. Previous studies have used a log parser to extract templates from unstructured log data and detect anomalies on the basis of patterns of the template occurrences. These methods have limitations for logs with unknown templates. Furthermore, since most log anomalies are known to be point anomalies rather than contextual anomalies, detection methods based on occurrence patterns can cause unnecessary delays in detection. In this paper, we propose LogELECTRA, a new log anomaly detection model that analyzes a single line of log messages more deeply on the basis of self-supervised anomaly detection. LogELECTRA specializes in detecting log anomalies as point anomalies by applying ELECTRA, a natural language processing model, to analyze the semantics of a single line of log messages. LogELECTRA outperformed existing state-of-the-art methods in experiments on the public benchmark log datasets BGL, Sprit, and Thunderbird.
ARDIR: Improving Robustness using Knowledge Distillation of Internal Representation
Nov 01, 2022
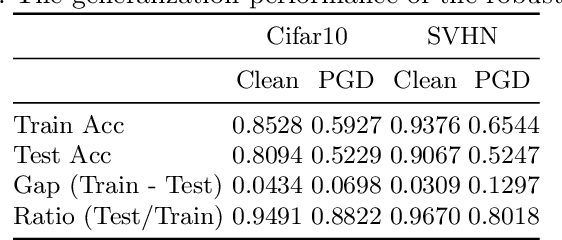


Adversarial training is the most promising method for learning robust models against adversarial examples. A recent study has shown that knowledge distillation between the same architectures is effective in improving the performance of adversarial training. Exploiting knowledge distillation is a new approach to improve adversarial training and has attracted much attention. However, its performance is still insufficient. Therefore, we propose Adversarial Robust Distillation with Internal Representation~(ARDIR) to utilize knowledge distillation even more effectively. In addition to the output of the teacher model, ARDIR uses the internal representation of the teacher model as a label for adversarial training. This enables the student model to be trained with richer, more informative labels. As a result, ARDIR can learn more robust student models. We show that ARDIR outperforms previous methods in our experiments.