 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogELECTRA: Self-supervised Anomaly Detection for Unstructured Logs
Feb 16, 2024



System logs are some of the most important information for the maintenance of software systems, which have become larger and more complex in recent years. The goal of log-based anomaly detection is to automatically detect system anomalies by analyzing the large number of logs generated in a short period of time, which is a critical challenge in the real world. Previous studies have used a log parser to extract templates from unstructured log data and detect anomalies on the basis of patterns of the template occurrences. These methods have limitations for logs with unknown templates. Furthermore, since most log anomalies are known to be point anomalies rather than contextual anomalies, detection methods based on occurrence patterns can cause unnecessary delays in detection. In this paper, we propose LogELECTRA, a new log anomaly detection model that analyzes a single line of log messages more deeply on the basis of self-supervised anomaly detection. LogELECTRA specializes in detecting log anomalies as point anomalies by applying ELECTRA, a natural language processing model, to analyze the semantics of a single line of log messages. LogELECTRA outperformed existing state-of-the-art methods in experiments on the public benchmark log datasets BGL, Sprit, and Thunderbird.
ARDIR: Improving Robustness using Knowledge Distillation of Internal Representation
Nov 01, 2022
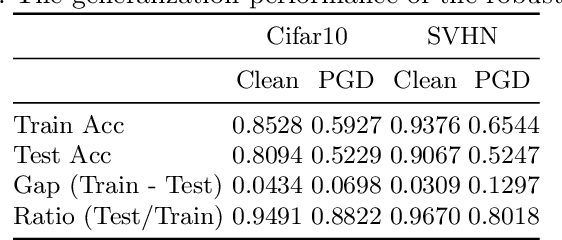


Adversarial training is the most promising method for learning robust models against adversarial examples. A recent study has shown that knowledge distillation between the same architectures is effective in improving the performance of adversarial training. Exploiting knowledge distillation is a new approach to improve adversarial training and has attracted much attention. However, its performance is still insufficient. Therefore, we propose Adversarial Robust Distillation with Internal Representation~(ARDIR) to utilize knowledge distillation even more effectively. In addition to the output of the teacher model, ARDIR uses the internal representation of the teacher model as a label for adversarial training. This enables the student model to be trained with richer, more informative labels. As a result, ARDIR can learn more robust student models. We show that ARDIR outperforms previous methods in our experiments.
Adversarial Training Makes Weight Loss Landscape Sharper in Logistic Regression
Feb 05, 2021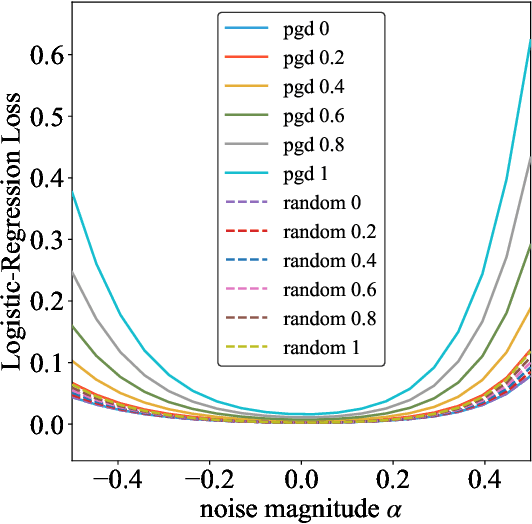
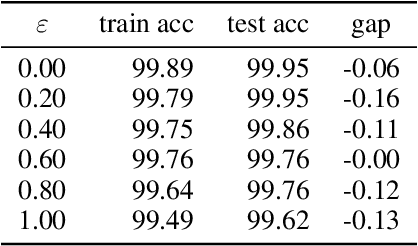
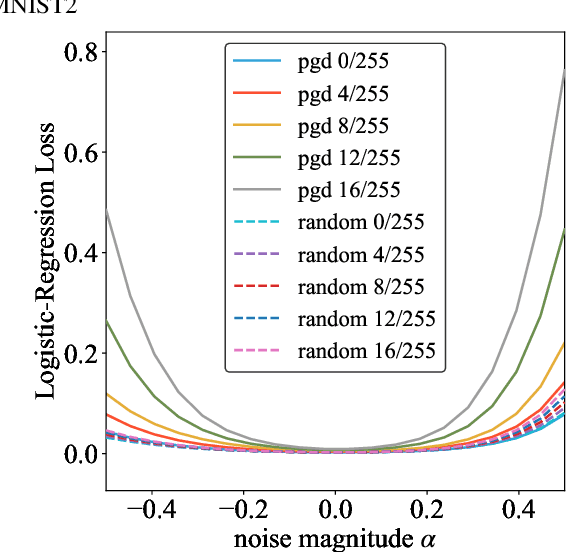
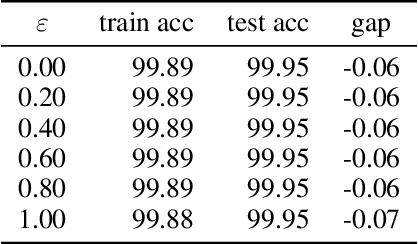
Adversarial training is actively studied for learning robust models against adversarial examples. A recent study finds that adversarially trained models degenerate generalization performance on adversarial examples when their weight loss landscape, which is loss changes with respect to weights, is sharp. Unfortunately, it has been experimentally shown that adversarial training sharpens the weight loss landscape, but this phenomenon has not been theoretically clarified. Therefore, we theoretically analyze this phenomenon in this paper. As a first step, this paper proves that adversarial training with the L2 norm constraints sharpens the weight loss landscape in the linear logistic regression model. Our analysis reveals that the sharpness of the weight loss landscape is caused by the noise aligned in the direction of increasing the loss, which is used in adversarial training. We theoretically and experimentally confirm that the weight loss landscape becomes sharper as the magnitude of the noise of adversarial training increases in the linear logistic regression model. Moreover, we experimentally confirm the same phenomena in ResNet18 with softmax as a more general case.