 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-learning Representations for Learning from Multiple Annotators
Jun 12, 2025



We propose a meta-learning method for learning from multiple noisy annotators. In many applications such as crowdsourcing services, labels for supervised learning are given by multiple annotators. Since the annotators have different skills or biases, given labels can be noisy. To learn accurate classifiers, existing methods require many noisy annotated data. However, sufficient data might be unavailable in practice. To overcome the lack of data, the proposed method uses labeled data obtained in different but related tasks. The proposed method embeds each example in tasks to a latent space by using a neural network and constructs a probabilistic model for learning a task-specific classifier while estimating annotators' abilities on the latent space. This neural network is meta-learned to improve the expected test classification performance when the classifier is adapted to a given small amount of annotated data. This classifier adaptation is performed by maximizing the posterior probability via the expectation-maximization (EM) algorithm. Since each step in the EM algorithm is easily computed as a closed-form and is differentiable, the proposed method can efficiently backpropagate the loss through the EM algorithm to meta-learn the neural network. We show the effectiveness of our method with real-world datasets with synthetic noise and real-world crowdsourcing datasets.
Meta-learning for Positive-unlabeled Classification
Jun 06, 2024



We propose a meta-learning method for positive and unlabeled (PU) classification, which improves the performance of binary classifiers obtained from only PU data in unseen target tasks. PU learning is an important problem since PU data naturally arise in real-world applications such as outlier detection and information retrieval. Existing PU learning methods require many PU data, but sufficient data are often unavailable in practice. The proposed method minimizes the test classification risk after the model is adapted to PU data by using related tasks that consist of positive, negative, and unlabeled data. We formulate the adaptation as an estimation problem of the Bayes optimal classifier, which is an optimal classifier to minimize the classification risk. The proposed method embeds each instance into a task-specific space using neural networks. With the embedded PU data, the Bayes optimal classifier is estimated through density-ratio estimation of PU densities, whose solution is obtained as a closed-form solution. The closed-form solution enables us to efficiently and effectively minimize the test classification risk. We empirically show that the proposed method outperforms existing methods with one synthetic and three real-world datasets.
GuP: Fast Subgraph Matching by Guard-based Pruning
Jun 11, 2023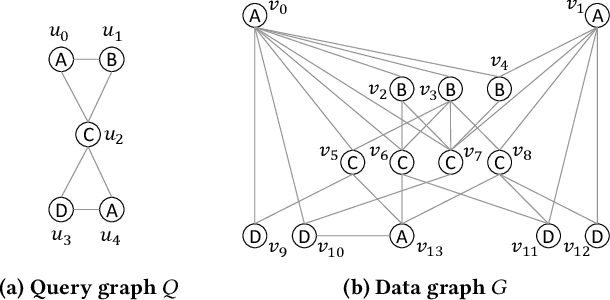
Subgraph matching, which finds subgraphs isomorphic to a query, is the key to information retrieval from data represented as a graph. To avoid redundant exploration in the data, existing methods restrict the search space by extracting candidate vertices and candidate edges that may constitute isomorphic subgraphs. However, it still requires expensive computation because candidate vertices induce many subgraphs that are not isomorphic to the query. In this paper, we propose GuP, a subgraph matching algorithm with pruning based on guards. Guards are a pattern of intermediate search states that never find isomorphic subgraphs. GuP attaches a guard on each candidate vertex and edge and filters out them adaptively to the search state. The experimental results showed that GuP can efficiently solve various queries, including those that the state-of-the-art methods could not solve in practical time.
Fast Regularized Discrete Optimal Transport with Group-Sparse Regularizers
Mar 14, 2023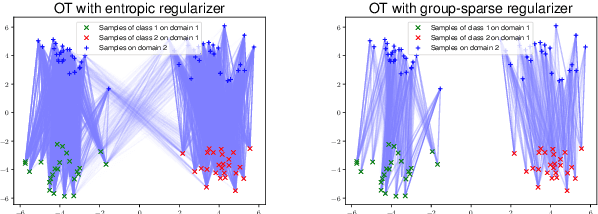
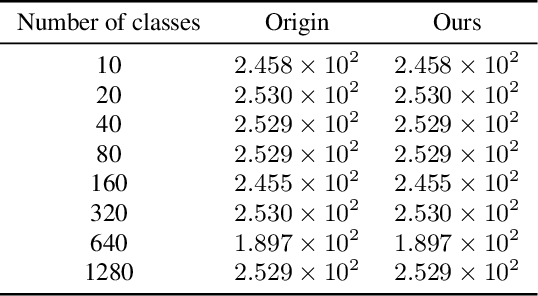
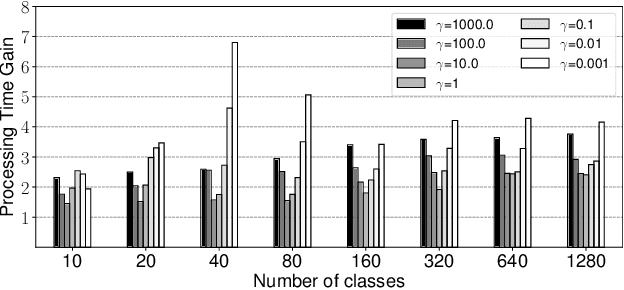
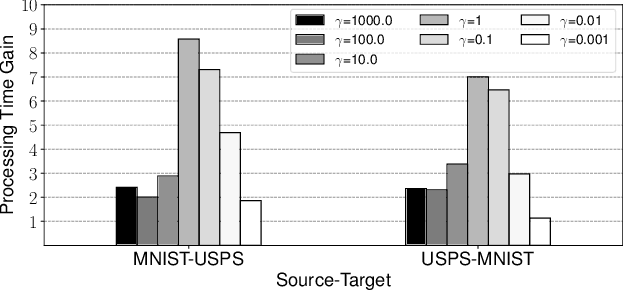
Regularized discrete optimal transport (OT) is a powerful tool to measure the distance between two discrete distributions that have been constructed from data samples on two different domains. While it has a wide range of applications in machine learning, in some cases the sampled data from only one of the domains will have class labels such as unsupervised domain adaptation. In this kind of problem setting, a group-sparse regularizer is frequently leveraged as a regularization term to handle class labels. In particular, it can preserve the label structure on the data samples by corresponding the data samples with the same class label to one group-sparse regularization term. As a result, we can measure the distance while utilizing label information by solving the regularized optimization problem with gradient-based algorithms. However, the gradient computation is expensive when the number of classes or data samples is large because the number of regularization terms and their respective sizes also turn out to be large. This paper proposes fast discrete OT with group-sparse regularizers. Our method is based on two ideas. The first is to safely skip the computations of the gradients that must be zero. The second is to efficiently extract the gradients that are expected to be nonzero. Our method is guaranteed to return the same value of the objective function as that of the original method. Experiments show that our method is up to 8.6 times faster than the original method without degrading accuracy.
Few-shot Learning for Unsupervised Feature Selection
Jul 02, 2021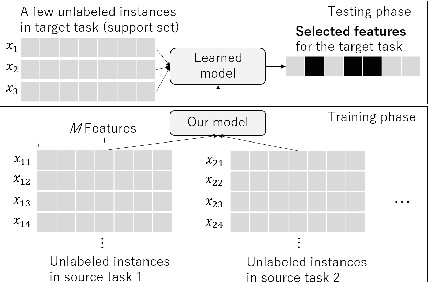
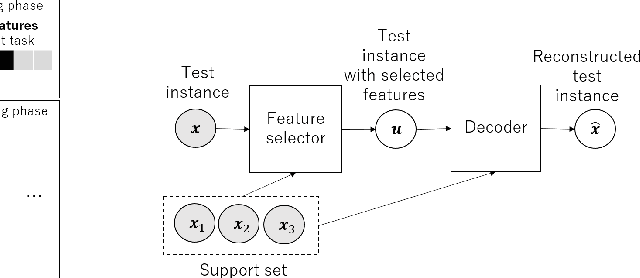

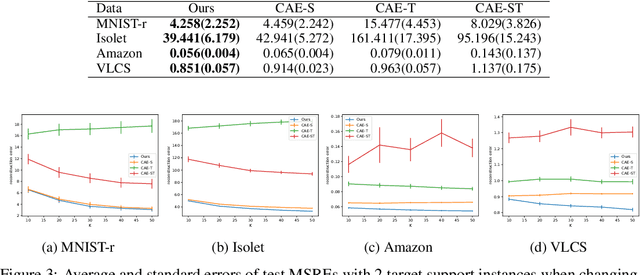
We propose a few-shot learning method for unsupervised feature selection, which is a task to select a subset of relevant features in unlabeled data. Existing methods usually require many instances for feature selection. However, sufficient instances are often unavailable in practice. The proposed method can select a subset of relevant features in a target task given a few unlabeled target instances by training with unlabeled instances in multiple source tasks. Our model consists of a feature selector and decoder. The feature selector outputs a subset of relevant features taking a few unlabeled instances as input such that the decoder can reconstruct the original features of unseen instances from the selected ones. The feature selector uses the Concrete random variables to select features via gradient descent. To encode task-specific properties from a few unlabeled instances to the model, the Concrete random variables and decoder are modeled using permutation-invariant neural networks that take a few unlabeled instances as input. Our model is trained by minimizing the expected test reconstruction error given a few unlabeled instances that is calculated with datasets in source tasks. We experimentally demonstrate that the proposed method outperforms existing feature selection methods.
Meta-Learning for Relative Density-Ratio Estimation
Jul 02, 2021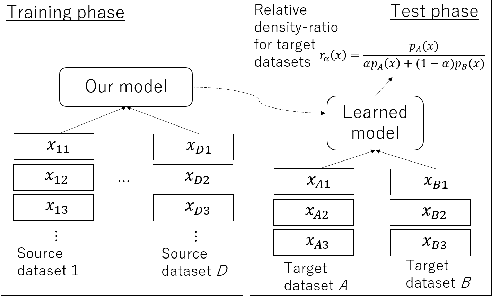
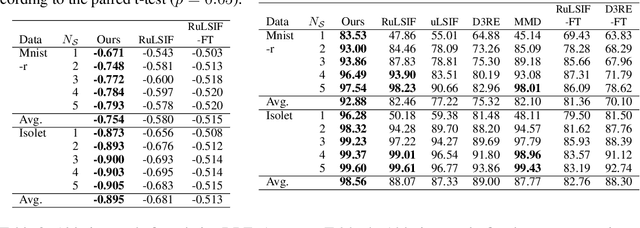

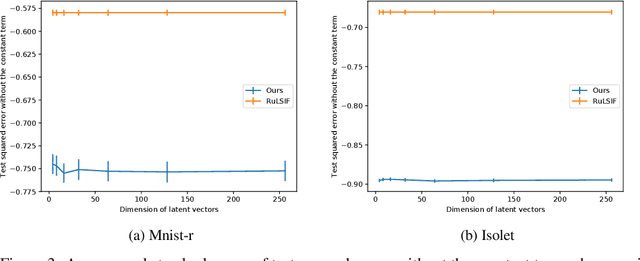
The ratio of two probability densities, called a density-ratio, is a vital quantity in machine learning. In particular, a relative density-ratio, which is a bounded extension of the density-ratio, has received much attention due to its stability and has been used in various applications such as outlier detection and dataset comparison. Existing methods for (relative) density-ratio estimation (DRE) require many instances from both densities. However, sufficient instances are often unavailable in practice. In this paper, we propose a meta-learning method for relative DRE, which estimates the relative density-ratio from a few instances by using knowledge in related datasets. Specifically, given two datasets that consist of a few instances, our model extracts the datasets' information by using neural networks and uses it to obtain instance embeddings appropriate for the relative DRE. We model the relative density-ratio by a linear model on the embedded space, whose global optimum solution can be obtained as a closed-form solution. The closed-form solution enables fast and effective adaptation to a few instances, and its differentiability enables us to train our model such that the expected test error for relative DRE can be explicitly minimized after adapting to a few instances. We empirically demonstrate the effectiveness of the proposed method by using three problems: relative DRE, dataset comparison, and outlier detection.
Semi-supervised Anomaly Detection on Attributed Graphs
Feb 27, 2020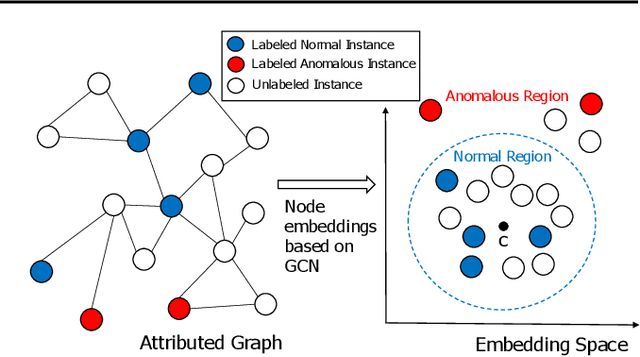
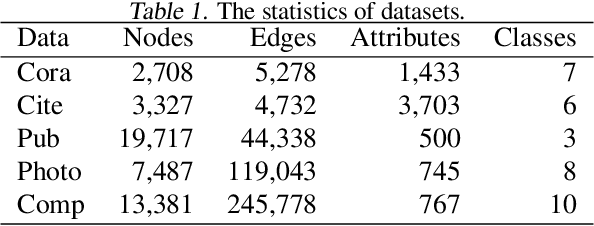

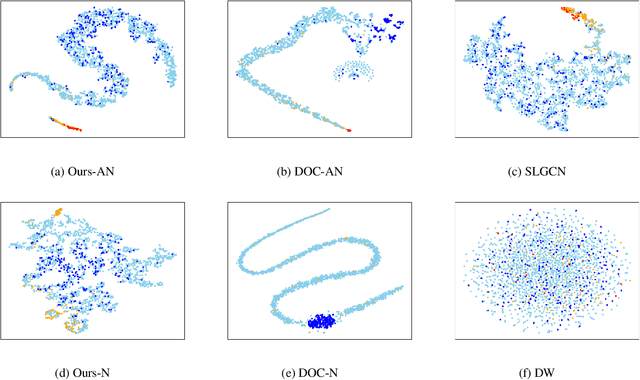
We propose a simple yet effective method for detecting anomalous instances on an attribute graph with label information of a small number of instances. Although with standard anomaly detection methods it is usually assumed that instances are independent and identically distributed, in many real-world applications, instances are often explicitly connected with each other, resulting in so-called attributed graphs. The proposed method embeds nodes (instances) on the attributed graph in the latent space by taking into account their attributes as well as the graph structure based on graph convolutional networks (GCNs). To learn node embeddings specialized for anomaly detection, in which there is a class imbalance due to the rarity of anomalies, the parameters of a GCN are trained to minimize the volume of a hypersphere that encloses the node embeddings of normal instances while embedding anomalous ones outside the hypersphere. This enables us to detect anomalies by simply calculating the distances between the node embeddings and hypersphere center. The proposed method can effectively propagate label information on a small amount of nodes to unlabeled ones by taking into account the node's attributes, graph structure, and class imbalance. In experiments with five real-world attributed graph datasets, we demonstrate that the proposed method achieves better performance than various existing anomaly detection methods.
Absum: Simple Regularization Method for Reducing Structural Sensitivity of Convolutional Neural Networks
Sep 19, 2019

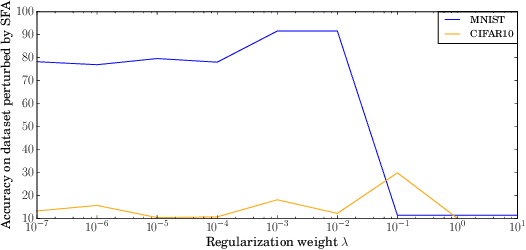
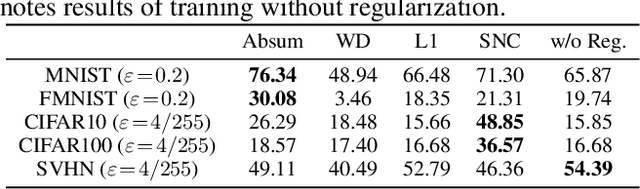
We propose Absum, which is a regularization method for improving adversarial robustness of convolutional neural networks (CNNs). Although CNNs can accurately recognize images, recent studies have shown that the convolution operations in CNNs commonly have structural sensitivity to specific noise composed of Fourier basis functions. By exploiting this sensitivity, they proposed a simple black-box adversarial attack: Single Fourier attack. To reduce structural sensitivity, we can use regularization of convolution filter weights since the sensitivity of linear transform can be assessed by the norm of the weights. However, standard regularization methods can prevent minimization of the loss function because they impose a tight constraint for obtaining high robustness. To solve this problem, Absum imposes a loose constraint; it penalizes the absolute values of the summation of the parameters in the convolution layers. Absum can improve robustness against single Fourier attack while being as simple and efficient as standard regularization methods (e.g., weight decay and L1 regularization). Our experiments demonstrate that Absum improves robustness against single Fourier attack more than standard regularization methods. Furthermore, we reveal that robust CNNs with Absum are more robust against transferred attacks due to decreasing the common sensitivity and against high-frequency noise than standard regularization methods. We also reveal that Absum can improve robustness against gradient-based attacks (projected gradient descent) when used with adversarial training.
Network Implosion: Effective Model Compression for ResNets via Static Layer Pruning and Retraining
Jun 10, 2019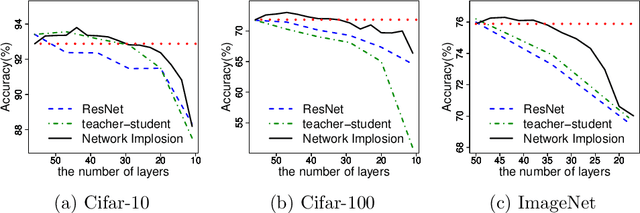
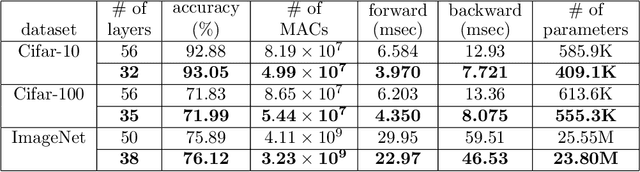
Residual Networks with convolutional layers are widely used in the field of machine learning. Since they effectively extract features from input data by stacking multiple layers, they can achieve high accuracy in many applications. However, the stacking of many layers raises their computation costs. To address this problem, we propose Network Implosion, it erases multiple layers from Residual Networks without degrading accuracy. Our key idea is to introduce a priority term that identifies the importance of a layer; we can select unimportant layers according to the priority and erase them after the training. In addition, we retrain the networks to avoid critical drops in accuracy after layer erasure. A theoretical assessment reveals that our erasure and retraining scheme can erase layers without accuracy drop, and achieve higher accuracy than is possible with training from scratch. Our experiments show that Network Implosion can, for classification on Cifar-10/100 and ImageNet, reduce the number of layers by 24.00 to 42.86 percent without any drop in accuracy.
Sigsoftmax: Reanalysis of the Softmax Bottleneck
May 28, 2018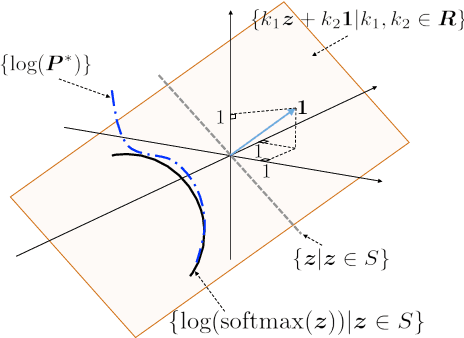



Softmax is an output activation function for modeling categorical probability distributions in many applications of deep learning. However, a recent study revealed that softmax can be a bottleneck of representational capacity of neural networks in language modeling (the softmax bottleneck). In this paper, we propose an output activation function for breaking the softmax bottleneck without additional parameters. We re-analyze the softmax bottleneck from the perspective of the output set of log-softmax and identify the cause of the softmax bottleneck. On the basis of this analysis, we propose sigsoftmax, which is composed of a multiplication of an exponential function and sigmoid function. Sigsoftmax can break the softmax bottleneck. The experiments on language modeling demonstrate that sigsoftmax and mixture of sigsoftmax outperform softmax and mixture of softmax, respectively.