 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Layer Selection for Layer-Wise Token Pruning in LLM Inference
Jan 12, 2026Due to the prevalence of large language models (LLMs), key-value (KV) cache reduction for LLM inference has received remarkable attention. Among numerous works that have been proposed in recent years, layer-wise token pruning approaches, which select a subset of tokens at particular layers to retain in KV cache and prune others, are one of the most popular schemes. They primarily adopt a set of pre-defined layers, at which tokens are selected. Such design is inflexible in the sense that the accuracy significantly varies across tasks and deteriorates in harder tasks such as KV retrieval. In this paper, we propose ASL, a training-free method that adaptively chooses the selection layer for KV cache reduction, exploiting the variance of token ranks ordered by attention score. The proposed method balances the performance across different tasks while meeting the user-specified KV budget requirement. ASL operates during the prefilling stage and can be jointly used with existing KV cache reduction methods such as SnapKV to optimize the decoding stage. By evaluations on the InfiniteBench, RULER, and NIAH benchmarks, we show that equipped with one-shot token selection, where tokens are selected at a layer and propagated to deeper layers, ASL outperforms state-of-the-art layer-wise token selection methods in accuracy while maintaining decoding speed and KV cache reduction.
GraphCompliance: Aligning Policy and Context Graphs for LLM-Based Regulatory Compliance
Oct 30, 2025Compliance at web scale poses practical challenges: each request may require a regulatory assessment. Regulatory texts (e.g., the General Data Protection Regulation, GDPR) are cross-referential and normative, while runtime contexts are expressed in unstructured natural language. This setting motivates us to align semantic information in unstructured text with the structured, normative elements of regulations. To this end, we introduce GraphCompliance, a framework that represents regulatory texts as a Policy Graph and runtime contexts as a Context Graph, and aligns them. In this formulation, the policy graph encodes normative structure and cross-references, whereas the context graph formalizes events as subject-action-object (SAO) and entity-relation triples. This alignment anchors the reasoning of a judge large language model (LLM) in structured information and helps reduce the burden of regulatory interpretation and event parsing, enabling a focus on the core reasoning step. In experiments on 300 GDPR-derived real-world scenarios spanning five evaluation tasks, GraphCompliance yields 4.1-7.2 percentage points (pp) higher micro-F1 than LLM-only and RAG baselines, with fewer under- and over-predictions, resulting in higher recall and lower false positive rates. Ablation studies indicate contributions from each graph component, suggesting that structured representations and a judge LLM are complementary for normative reasoning.
Seven Security Challenges That Must be Solved in Cross-domain Multi-agent LLM Systems
May 28, 2025

Large language models (LLMs) are rapidly evolving into autonomous agents that cooperate across organizational boundaries, enabling joint disaster response, supply-chain optimization, and other tasks that demand decentralized expertise without surrendering data ownership. Yet, cross-domain collaboration shatters the unified trust assumptions behind current alignment and containment techniques. An agent benign in isolation may, when receiving messages from an untrusted peer, leak secrets or violate policy, producing risks driven by emergent multi-agent dynamics rather than classical software bugs. This position paper maps the security agenda for cross-domain multi-agent LLM systems. We introduce seven categories of novel security challenges, for each of which we also present plausible attacks, security evaluation metrics, and future research guidelines.
CKGAN: Training Generative Adversarial Networks Using Characteristic Kernel Integral Probability Metrics
Apr 08, 2025In this paper, we propose CKGAN, a novel generative adversarial network (GAN) variant based on an integral probability metrics framework with characteristic kernel (CKIPM). CKIPM, as a distance between two probability distributions, is designed to optimize the lowerbound of the maximum mean discrepancy (MMD) in a reproducing kernel Hilbert space, and thus can be used to train GANs. CKGAN mitigates the notorious problem of mode collapse by mapping the generated images back to random noise. To save the effort of selecting the kernel function manually, we propose a soft selection method to automatically learn a characteristic kernel function. The experimental evaluation conducted on a set of synthetic and real image benchmarks (MNIST, CelebA, etc.) demonstrates that CKGAN generally outperforms other MMD-based GANs. The results also show that at the cost of moderately more training time, the automatically selected kernel function delivers very close performance to the best of manually fine-tuned one on real image benchmarks and is able to improve the performances of other MMD-based GANs.
Legal Fact Prediction: Task Definition and Dataset Construction
Sep 11, 2024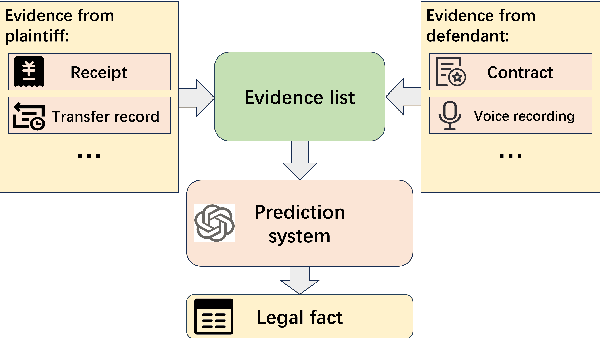

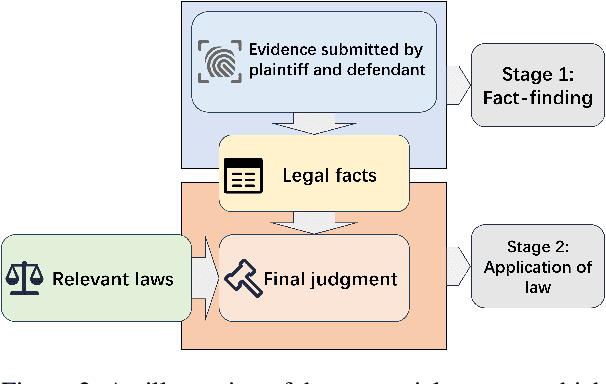
Legal facts refer to the facts that can be proven by acknowledged evidence in a trial. They form the basis for the determination of court judgments. This paper introduces a novel NLP task: legal fact prediction, which aims to predict the legal fact based on a list of evidence. The predicted facts can instruct the parties and their lawyers involved in a trial to strengthen their submissions and optimize their strategies during the trial. Moreover, since real legal facts are difficult to obtain before the final judgment, the predicted facts also serve as an important basis for legal judgment prediction. We construct a benchmark dataset consisting of evidence lists and ground-truth legal facts for real civil loan cases, LFPLoan. Our experiments on this dataset show that this task is non-trivial and requires further considerable research efforts.
Large Language Models as Urban Residents: An LLM Agent Framework for Personal Mobility Generation
Feb 22, 2024This paper introduces a novel approach using Large Language Models (LLMs) integrated into an agent framework for flexible and efficient personal mobility generation. LLMs overcome the limitations of previous models by efficiently processing semantic data and offering versatility in modeling various tasks. Our approach addresses the critical need to align LLMs with real-world urban mobility data, focusing on three research questions: aligning LLMs with rich activity data, developing reliable activity generation strategies, and exploring LLM applications in urban mobility. The key technical contribution is a novel LLM agent framework that accounts for individual activity patterns and motivations, including a self-consistency approach to align LLMs with real-world activity data and a retrieval-augmented strategy for interpretable activity generation. In experimental studies, comprehensive validation is performed using real-world data. This research marks the pioneering work of designing an LLM agent framework for activity generation based on real-world human activity data, offering a promising tool for urban mobility analysis.
Shall We Talk: Exploring Spontaneous Collaborations of Competing LLM Agents
Feb 19, 2024



Recent advancements have shown that agents powered by large language models (LLMs) possess capabilities to simulate human behaviors and societal dynamics. However, the potential for LLM agents to spontaneously establish collaborative relationships in the absence of explicit instructions has not been studied. To address this gap, we conduct three case studies, revealing that LLM agents are capable of spontaneously forming collaborations even within competitive settings. This finding not only demonstrates the capacity of LLM agents to mimic competition and cooperation in human societies but also validates a promising vision of computational social science. Specifically, it suggests that LLM agents could be utilized to model human social interactions, including those with spontaneous collaborations, thus offering insights into social phenomena. The source codes for this study are available at https://github.com/wuzengqing001225/SABM_ShallWeTalk .
BClean: A Bayesian Data Cleaning System
Nov 11, 2023There is a considerable body of work on data cleaning which employs various principles to rectify erroneous data and transform a dirty dataset into a cleaner one. One of prevalent approaches is probabilistic methods, including Bayesian methods. However, existing probabilistic methods often assume a simplistic distribution (e.g., Gaussian distribution), which is frequently underfitted in practice, or they necessitate experts to provide a complex prior distribution (e.g., via a programming language). This requirement is both labor-intensive and costly, rendering these methods less suitable for real-world applications. In this paper, we propose BClean, a Bayesian Cleaning system that features automatic Bayesian network construction and user interaction. We recast the data cleaning problem as a Bayesian inference that fully exploits the relationships between attributes in the observed dataset and any prior information provided by users. To this end, we present an automatic Bayesian network construction method that extends a structure learning-based functional dependency discovery method with similarity functions to capture the relationships between attributes. Furthermore, our system allows users to modify the generated Bayesian network in order to specify prior information or correct inaccuracies identified by the automatic generation process. We also design an effective scoring model (called the compensative scoring model) necessary for the Bayesian inference. To enhance the efficiency of data cleaning, we propose several approximation strategies for the Bayesian inference, including graph partitioning, domain pruning, and pre-detection. By evaluating on both real-world and synthetic datasets, we demonstrate that BClean is capable of achieving an F-measure of up to 0.9 in data cleaning, outperforming existing Bayesian methods by 2% and other data cleaning methods by 15%.
Learned spatial data partitioning
Jun 19, 2023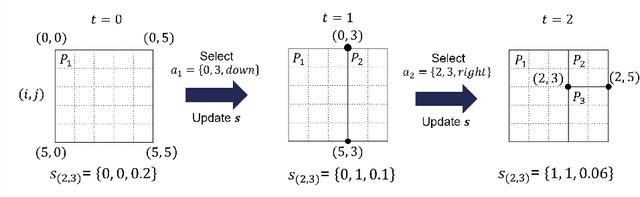
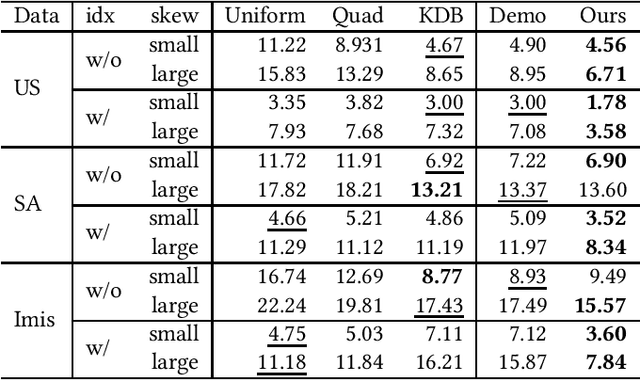
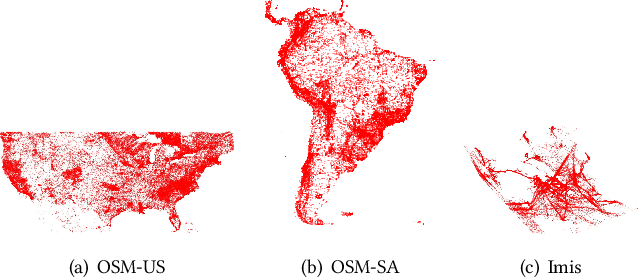
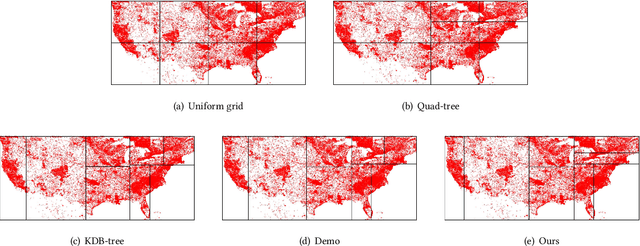
Due to the significant increase in the size of spatial data, it is essential to use distributed parallel processing systems to efficiently analyze spatial data. In this paper, we first study learned spatial data partitioning, which effectively assigns groups of big spatial data to computers based on locations of data by using machine learning techniques. We formalize spatial data partitioning in the context of reinforcement learning and develop a novel deep reinforcement learning algorithm. Our learning algorithm leverages features of spatial data partitioning and prunes ineffective learning processes to find optimal partitions efficiently. Our experimental study, which uses Apache Sedona and real-world spatial data, demonstrates that our method efficiently finds partitions for accelerating distance join queries and reduces the workload run time by up to 59.4%.
Why Using Either Aggregated Features or Adjacency Lists in Directed or Undirected Graph? Empirical Study and Simple Classification Method
Jun 14, 2023Node classification is one of the hottest tasks in graph analysis. In this paper, we focus on the choices of node representations (aggregated features vs. adjacency lists) and the edge direction of an input graph (directed vs. undirected), which have a large influence on classification results. We address the first empirical study to benchmark the performance of various GNNs that use either combination of node representations and edge directions. Our experiments demonstrate that no single combination stably achieves state-of-the-art results across datasets, which indicates that we need to select appropriate combinations depending on the characteristics of datasets. In response, we propose a simple yet holistic classification method A2DUG which leverages all combinations of node representation variants in directed and undirected graphs. We demonstrate that A2DUG stably performs well on various datasets. Surprisingly, it largely outperforms the current state-of-the-art methods in several datasets. This result validates the importance of the adaptive effect control on the combinations of node representations and edge directions.