 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYouZhi: Towards High-Concurrency Financial LLMs via Adaptive GQA-to-MLA Transition
Jun 04, 2026Large language models (LLMs) drive significant financial innovations, yet their high-concurrency deployment is severely bottlenecked by KV cache memory overhead, which inflates infrastructure costs and throttles scalability. To address this, we propose YouZhi-LLM, a highly efficient financial LLM empowered by a comprehensive structural transition and training pipeline natively built on the Huawei Ascend ecosystem. At its algorithmic core, YouZhi-LLM features a layer-adaptive GQA-to-MLA transition framework that dynamically assigns per-layer FreqFold sizes, maximizing KV-cache compression while minimizing perplexity degradation. To recover representation capacity and inject domain expertise, the Ascend-based training pipeline seamlessly integrates generalized knowledge distillation with financial-specific supervised fine-tuning. Evaluations demonstrate the superiority of this systematic approach, with the adaptive transition reducing perplexity degradation by up to 35% over uniform baselines. Crucially, when evaluated on Ascend NPUs via vLLM-Ascend, the massive KV-cache reduction translates directly into deployment efficiency. Compared to their respective base models, YouZhi-7B yields a 12.3% improvement in average financial benchmark score alongside a 2.69$\times$ increase in maximum concurrency; similarly, YouZhi-14B achieves a 7.0% accuracy gain and a 2.43$\times$ concurrency boost, establishing a new paradigm for cost-effective, high-throughput financial inference.
Hybrid Bit and Semantic Communications for UAV-Enabled Wireless Power Transfer Networks: A Decision-Assisted Deep Reinforcement Learning Approach
May 30, 2026Semantic communications which can significantly reduce spectrum consumption in wireless networks, have recently become a popular research area. When combined with wireless power transfer (WPT), semantic communications can help achieve high spectral efficiency for energy-limited devices in wireless communications. In energy-constrained and link budget-limited scenarios such as UAV networks, the integration of semantic communications and WPT enables highly energyefficient transmission mechanisms. In this paper, we investigate semantic communications in UAV-enabled WPT networks. To achieve adaptability to varying signal-to-noise ratio (SNR) and task requirements, we introduce a multi-layer hybrid bit and semantic communication framework. We adopt a semantic communication efficiency metric and aim to maximize it by jointly optimizing UAV trajectory, energy harvesting base station (EHBS) selection, user association, semantic mode selection, and energy harvesting time allocation. To address this complex longterm optimization problem, we introduce the distributional soft actor-critic (DSAC) algorithm and introduce a decision assistant to further enhance the convergence performance of DSAC. Simulation results validate the effectiveness of the proposed method and framework and demonstrate that our algorithm can achieve superior long-term optimization performance in dynamic network environments.
Joint Optimization of Flexible Antenna Array Shape and Beamforming for Secure Communication
Feb 27, 2026Flexible antenna arrays (FAAs) can physically reshape their geometry to add new spatial degrees of freedom, whereas transmit beamforming adjusts the complex element weights to electronically steer and shape the array's radiation pattern, thereby significantly improving communication performance. This paper is the first to explore the integration of FAA geometry control and beamforming for physical layer security enhancement, where a base station equipped with an FAA communicates with a legitimate user in the presence of passive eavesdroppers. To safeguard confidential transmissions, we formulate a new secrecy rate maximization problem that jointly optimizes the transmit beamforming vector and a continuous FAA shape control parameter. Due to the non convex nature of the problem, an alternating optimization algorithm is developed to decompose the joint design into tractable subproblems, which are solved iteratively to refine both the FAA geometry and beamforming strategy. Simulation results confirm that the proposed joint optimization framework significantly outperforms conventional fixed shape or beamforming only schemes, demonstrating the potential of FAA enabled reconfigurability for secure wireless communications.
FMMD: A multimodal open peer review dataset based on F1000Research
Feb 15, 2026Automated scholarly paper review (ASPR) has entered the coexistence phase with traditional peer review, where artificial intelligence (AI) systems are increasingly incorporated into real-world manuscript evaluation. In parallel, research on automated and AI-assisted peer review has proliferated. Despite this momentum, empirical progress remains constrained by several critical limitations in existing datasets. While reviewers routinely evaluate figures, tables, and complex layouts to assess scientific claims, most existing datasets remain overwhelmingly text-centric. This bias is reinforced by a narrow focus on data from computer science venues. Furthermore, these datasets lack precise alignment between reviewer comments and specific manuscript versions, obscuring the iterative relationship between peer review and manuscript evolution. In response, we introduce FMMD, a multimodal and multidisciplinary open peer review dataset curated from F1000Research. The dataset bridges the current gap by integrating manuscript-level visual and structural data with version-specific reviewer reports and editorial decisions. By providing explicit alignment between reviewer comments and the exact article iteration under review, FMMD enables fine-grained analysis of the peer review lifecycle across diverse scientific domains. FMMD supports tasks such as multimodal issue detection and multimodal review comment generation. It provides a comprehensive empirical resource for the development of peer review research.
Flexible Reconfigurable Intelligent Surface-Aided Covert Communications in UAV Networks
Dec 10, 2025



In recent years, unmanned aerial vehicles (UAVs) have become a key role in wireless communication networks due to their flexibility and dynamic adaptability. However, the openness of UAV-based communications leads to security and privacy concerns in wireless transmissions. This paper investigates a framework of UAV covert communications which introduces flexible reconfigurable intelligent surfaces (F-RIS) in UAV networks. Unlike traditional RIS, F-RIS provides advanced deployment flexibility by conforming to curved surfaces and dynamically reconfiguring its electromagnetic properties to enhance the covert communication performance. We establish an electromagnetic model for F-RIS and further develop a fitted model that describes the relationship between F-RIS reflection amplitude, reflection phase, and incident angle. To maximize the covert transmission rate among UAVs while meeting the covert constraint and public transmission constraint, we introduce a strategy of jointly optimizing UAV trajectories, F-RIS reflection vectors, F-RIS incident angles, and non-orthogonal multiple access (NOMA) power allocation. Considering this is a complicated non-convex optimization problem, we propose a deep reinforcement learning (DRL) algorithm-based optimization solution. Simulation results demonstrate that our proposed framework and optimization method significantly outperform traditional benchmarks, and highlight the advantages of F-RIS in enhancing covert communication performance within UAV networks.
LLM Optimization Unlocks Real-Time Pairwise Reranking
Nov 10, 2025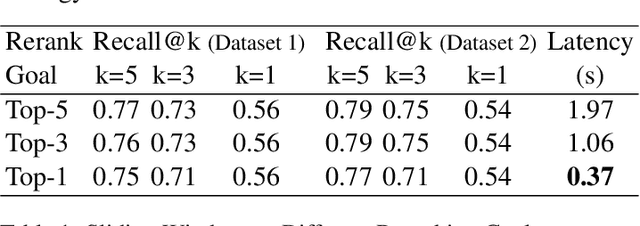



Efficiently reranking documents retrieved from information retrieval (IR) pipelines to enhance overall quality of Retrieval-Augmented Generation (RAG) system remains an important yet challenging problem. Recent studies have highlighted the importance of Large Language Models (LLMs) in reranking tasks. In particular, Pairwise Reranking Prompting (PRP) has emerged as a promising plug-and-play approach due to its usability and effectiveness. However, the inherent complexity of the algorithm, coupled with the high computational demands and latency incurred due to LLMs, raises concerns about its feasibility in real-time applications. To address these challenges, this paper presents a focused study on pairwise reranking, demonstrating that carefully applied optimization methods can significantly mitigate these issues. By implementing these methods, we achieve a remarkable latency reduction of up to 166 times, from 61.36 seconds to 0.37 seconds per query, with an insignificant drop in performance measured by Recall@k. Our study highlights the importance of design choices that were previously overlooked, such as using smaller models, limiting the reranked set, using lower precision, reducing positional bias with one-directional order inference, and restricting output tokens. These optimizations make LLM-based reranking substantially more efficient and feasible for latency-sensitive, real-world deployments.
DISCO Balances the Scales: Adaptive Domain- and Difficulty-Aware Reinforcement Learning on Imbalanced Data
May 21, 2025Large Language Models (LLMs) are increasingly aligned with human preferences through Reinforcement Learning from Human Feedback (RLHF). Among RLHF methods, Group Relative Policy Optimization (GRPO) has gained attention for its simplicity and strong performance, notably eliminating the need for a learned value function. However, GRPO implicitly assumes a balanced domain distribution and uniform semantic alignment across groups - assumptions that rarely hold in real-world datasets. When applied to multi-domain, imbalanced data, GRPO disproportionately optimizes for dominant domains, neglecting underrepresented ones and resulting in poor generalization and fairness. We propose Domain-Informed Self-Consistency Policy Optimization (DISCO), a principled extension to GRPO that addresses inter-group imbalance with two key innovations. Domain-aware reward scaling counteracts frequency bias by reweighting optimization based on domain prevalence. Difficulty-aware reward scaling leverages prompt-level self-consistency to identify and prioritize uncertain prompts that offer greater learning value. Together, these strategies promote more equitable and effective policy learning across domains. Extensive experiments across multiple LLMs and skewed training distributions show that DISCO improves generalization, outperforms existing GRPO variants by 5% on Qwen3 models, and sets new state-of-the-art results on multi-domain alignment benchmarks.
Hybrid Beamforming for RIS-Assisted Multiuser Fluid Antenna Systems
Apr 12, 2025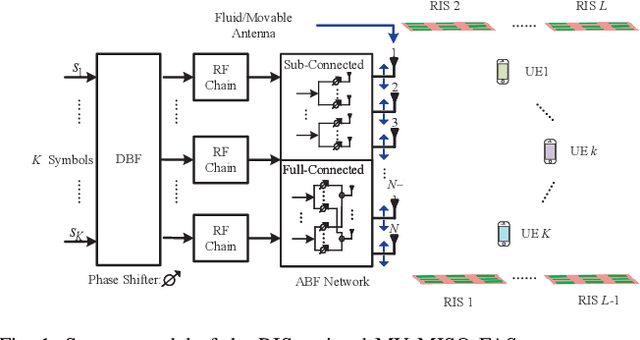
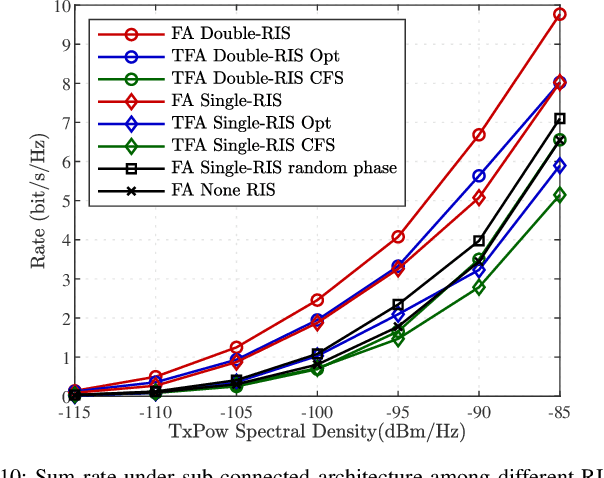
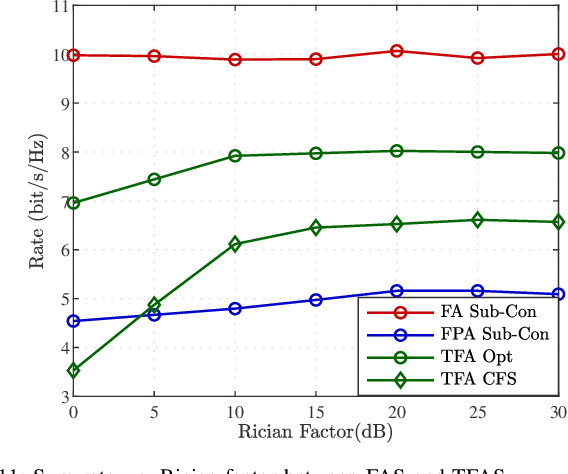
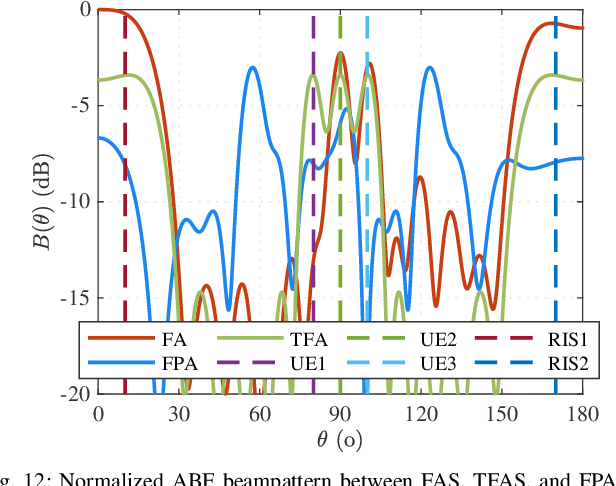
Recent advances in reconfigurable antennas have led to the new concept of the fluid antenna system (FAS) for shape and position flexibility, as another degree of freedom for wireless communication enhancement. This paper explores the integration of a transmit FAS array for hybrid beamforming (HBF) into a reconfigurable intelligent surface (RIS)-assisted communication architecture for multiuser communications in the downlink, corresponding to the downlink RIS-assisted multiuser multiple-input single-output (MISO) FAS model (Tx RIS-assisted-MISO-FAS). By considering Rician channel fading, we formulate a sum-rate maximization optimization problem to alternately optimize the HBF matrix, the RIS phase-shift matrix, and the FAS position. Due to the strong coupling of multiple optimization variables, the multi-fractional summation in the sum-rate expression, the modulus-1 limitation of analog phase shifters and RIS, and the antenna position variables appearing in the exponent, this problem is highly non-convex, which is addressed through the block coordinate descent (BCD) framework in conjunction with semidefinite relaxation (SDR) and majorization-minimization (MM) methods. To reduce the computational complexity, we then propose a low-complexity grating-lobe (GL)-based telescopic-FAS (TFA) with multiple delicately deployed RISs under the sub-connected HBF architecture and the line-of-sight (LoS)-dominant channel condition, to allow closed-form solutions for the HBF and TFA position. Our simulation results illustrate that the former optimization scheme significantly enhances the achievable rate of the proposed system, while the GL-based TFA scheme also provides a considerable gain over conventional fixed-position antenna (FPA) systems, requiring statistical channel state information (CSI) only and with low computational complexity.
Beyond Unimodal Boundaries: Generative Recommendation with Multimodal Semantics
Mar 30, 2025Generative recommendation (GR) has become a powerful paradigm in recommendation systems that implicitly links modality and semantics to item representation, in contrast to previous methods that relied on non-semantic item identifiers in autoregressive models. However, previous research has predominantly treated modalities in isolation, typically assuming item content is unimodal (usually text). We argue that this is a significant limitation given the rich, multimodal nature of real-world data and the potential sensitivity of GR models to modality choices and usage. Our work aims to explore the critical problem of Multimodal Generative Recommendation (MGR), highlighting the importance of modality choices in GR nframeworks. We reveal that GR models are particularly sensitive to different modalities and examine the challenges in achieving effective GR when multiple modalities are available. By evaluating design strategies for effectively leveraging multiple modalities, we identify key challenges and introduce MGR-LF++, an enhanced late fusion framework that employs contrastive modality alignment and special tokens to denote different modalities, achieving a performance improvement of over 20% compared to single-modality alternatives.
Amplitude-Domain Reflection Modulation for Active RIS-Assisted Wireless Communications
Mar 27, 2025In this paper, we propose a novel active reconfigurable intelligent surface (RIS)-assisted amplitude-domain reflection modulation (ADRM) transmission scheme, termed as ARIS-ADRM. This innovative approach leverages the additional degree of freedom (DoF) provided by the amplitude domain of the active RIS to perform index modulation (IM), thereby enhancing spectral efficiency (SE) without increasing the costs associated with additional radio frequency (RF) chains. Specifically, the ARIS-ADRM scheme transmits information bits through both the modulation symbol and the index of active RIS amplitude allocation patterns (AAPs). To evaluate the performance of the proposed ARIS-ADRM scheme, we provide an achievable rate analysis and derive a closed-form expression for the upper bound on the average bit error probability (ABEP). Furthermore, we formulate an optimization problem to construct the AAP codebook, aiming to minimize the ABEP. Simulation results demonstrate that the proposed scheme significantly improves error performance under the same SE conditions compared to its benchmarks. This improvement is due to its ability to flexibly adapt the transmission rate by fully exploiting the amplitude domain DoF provided by the active RIS.