 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubFlow: Sub-mode Conditioned Flow Matching for Diverse One-Step Generation
Apr 14, 2026Flow matching has emerged as a powerful generative framework, with recent few-step methods achieving remarkable inference acceleration. However, we identify a critical yet overlooked limitation: these models suffer from severe diversity degradation, concentrating samples on dominant modes while neglecting rare but valid variations of the target distribution. We trace this degradation to averaging distortion: when trained with MSE objectives, class-conditional flows learn a frequency-weighted mean over intra-class sub-modes, causing the model to over-represent high-density modes while systematically neglecting low-density ones. To address this, we propose SubFlow, Sub-mode Conditioned Flow Matching, which eliminates averaging distortion by decomposing each class into fine-grained sub-modes via semantic clustering and conditioning the flow on sub-mode indices. Each conditioned sub-distribution is approximately unimodal, so the learned flow accurately targets individual modes with no averaging distortion, restoring full mode coverage in a single inference step. Crucially, SubFlow is entirely plug-and-play: it integrates seamlessly into existing one-step models such as MeanFlow and Shortcut Models without any architectural modifications. Extensive experiments on ImageNet-256 demonstrate that SubFlow yields substantial gains in generation diversity (Recall) while maintaining competitive image quality (FID), confirming its broad applicability across different one-step generation frameworks. Project page: https://yexionglin.github.io/subflow.
CloneShield: A Framework for Universal Perturbation Against Zero-Shot Voice Cloning
May 25, 2025Recent breakthroughs in text-to-speech (TTS) voice cloning have raised serious privacy concerns, allowing highly accurate vocal identity replication from just a few seconds of reference audio, while retaining the speaker's vocal authenticity. In this paper, we introduce CloneShield, a universal time-domain adversarial perturbation framework specifically designed to defend against zero-shot voice cloning. Our method provides protection that is robust across speakers and utterances, without requiring any prior knowledge of the synthesized text. We formulate perturbation generation as a multi-objective optimization problem, and propose Multi-Gradient Descent Algorithm (MGDA) to ensure the robust protection across diverse utterances. To preserve natural auditory perception for users, we decompose the adversarial perturbation via Mel-spectrogram representations and fine-tune it for each sample. This design ensures imperceptibility while maintaining strong degradation effects on zero-shot cloned outputs. Experiments on three state-of-the-art zero-shot TTS systems, five benchmark datasets and evaluations from 60 human listeners demonstrate that our method preserves near-original audio quality in protected inputs (PESQ = 3.90, SRS = 0.93) while substantially degrading both speaker similarity and speech quality in cloned samples (PESQ = 1.07, SRS = 0.08).
Joint Sparse Graph for Enhanced MIMO-AFDM Receiver Design
Mar 24, 2025Affine frequency division multiplexing (AFDM) is a promising chirp-assisted multicarrier waveform for future high-mobility communications. This paper is devoted to enhanced receiver design for multiple input and multiple output AFDM (MIMO-AFDM) systems. Firstly, we introduce a unified variational inference (VI) approach to approximate the target posterior distribution, under which the belief propagation (BP) and expectation propagation (EP)-based algorithms are derived. As both VI-based detection and low-density parity-check (LDPC) decoding can be expressed by bipartite graphs in MIMO-AFDM systems, we construct a joint sparse graph (JSG) by merging the graphs of these two for low-complexity receiver design. Then, based on this graph model, we present the detailed message propagation of the proposed JSG. Additionally, we propose an enhanced JSG (E-JSG) receiver based on the linear constellation encoding model. The proposed E-JSG eliminates the need for interleavers, de-interleavers, and log-likelihood ratio transformations, thus leading to concurrent detection and decoding over the integrated sparse graph. To further reduce detection complexity, we introduce a sparse channel method by approaximating multiple graph edges with insignificant channel coefficients into a single edge on the VI graph. Simulation results show the superiority of the proposed receivers in terms of computational complexity, detection and decoding latency, and error rate performance compared to the conventional ones.
LCA-on-the-Line: Benchmarking Out-of-Distribution Generalization with Class Taxonomies
Jul 22, 2024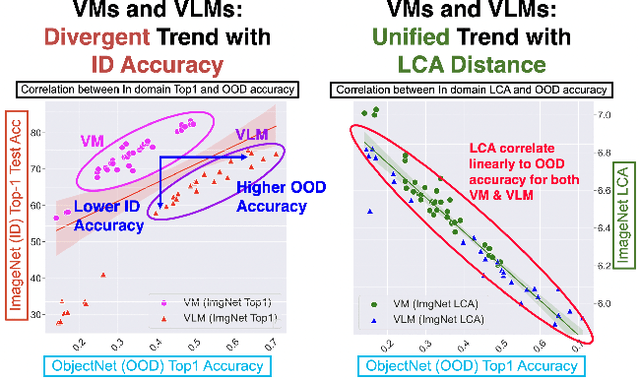
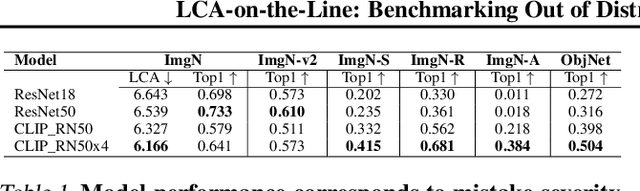
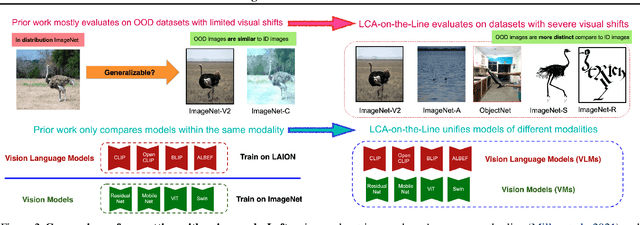
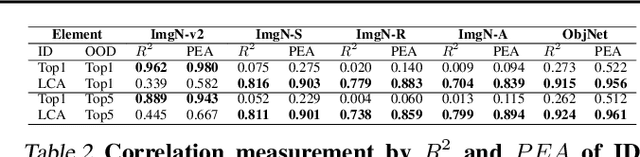
We tackle the challenge of predicting models' Out-of-Distribution (OOD) performance using in-distribution (ID) measurements without requiring OOD data. Existing evaluations with "Effective Robustness", which use ID accuracy as an indicator of OOD accuracy, encounter limitations when models are trained with diverse supervision and distributions, such as class labels (Vision Models, VMs, on ImageNet) and textual descriptions (Visual-Language Models, VLMs, on LAION). VLMs often generalize better to OOD data than VMs despite having similar or lower ID performance. To improve the prediction of models' OOD performance from ID measurements, we introduce the Lowest Common Ancestor (LCA)-on-the-Line framework. This approach revisits the established concept of LCA distance, which measures the hierarchical distance between labels and predictions within a predefined class hierarchy, such as WordNet. We assess 75 models using ImageNet as the ID dataset and five significantly shifted OOD variants, uncovering a strong linear correlation between ID LCA distance and OOD top-1 accuracy. Our method provides a compelling alternative for understanding why VLMs tend to generalize better. Additionally, we propose a technique to construct a taxonomic hierarchy on any dataset using K-means clustering, demonstrating that LCA distance is robust to the constructed taxonomic hierarchy. Moreover, we demonstrate that aligning model predictions with class taxonomies, through soft labels or prompt engineering, can enhance model generalization. Open source code in our Project Page: https://elvishelvis.github.io/papers/lca/.
Multi-level Domain Adaptation for Lane Detection
Jun 21, 2022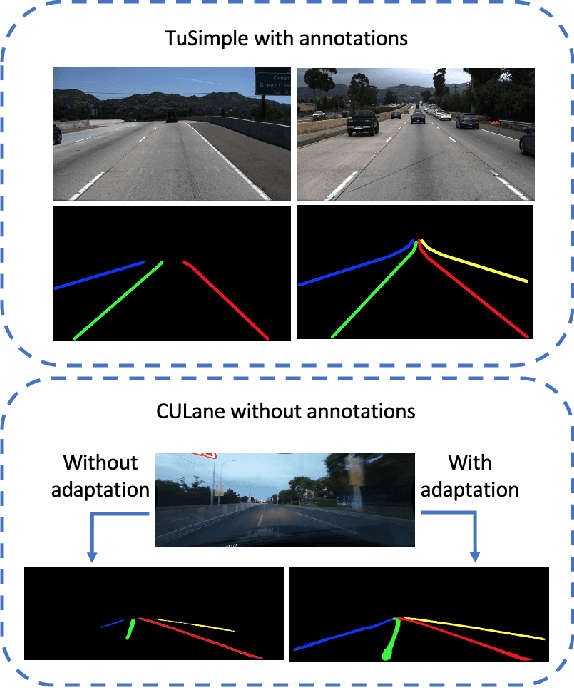

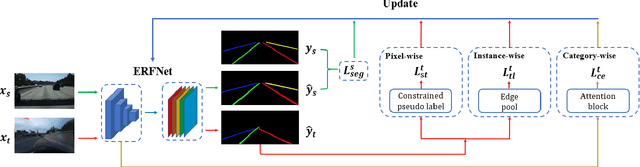
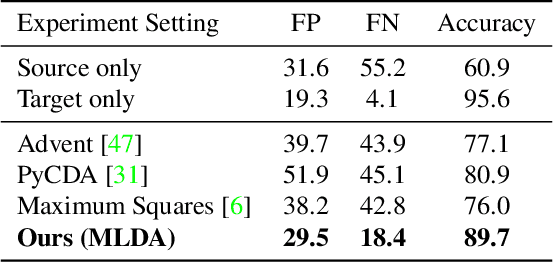
We focus on bridging domain discrepancy in lane detection among different scenarios to greatly reduce extra annotation and re-training costs for autonomous driving. Critical factors hinder the performance improvement of cross-domain lane detection that conventional methods only focus on pixel-wise loss while ignoring shape and position priors of lanes. To address the issue, we propose the Multi-level Domain Adaptation (MLDA) framework, a new perspective to handle cross-domain lane detection at three complementary semantic levels of pixel, instance and category. Specifically, at pixel level, we propose to apply cross-class confidence constraints in self-training to tackle the imbalanced confidence distribution of lane and background. At instance level, we go beyond pixels to treat segmented lanes as instances and facilitate discriminative features in target domain with triplet learning, which effectively rebuilds the semantic context of lanes and contributes to alleviating the feature confusion. At category level, we propose an adaptive inter-domain embedding module to utilize the position prior of lanes during adaptation. In two challenging datasets, ie TuSimple and CULane, our approach improves lane detection performance by a large margin with gains of 8.8% on accuracy and 7.4% on F1-score respectively, compared with state-of-the-art domain adaptation algorithms.
Reconstruct from Top View: A 3D Lane Detection Approach based on Geometry Structure Prior
Jun 21, 2022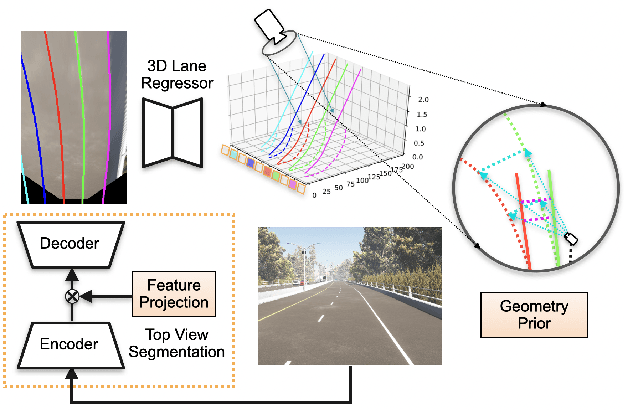
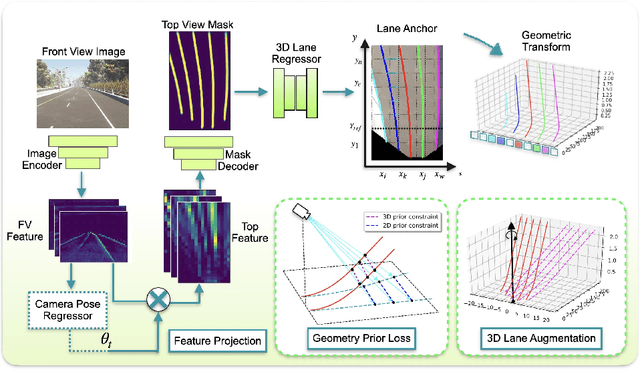
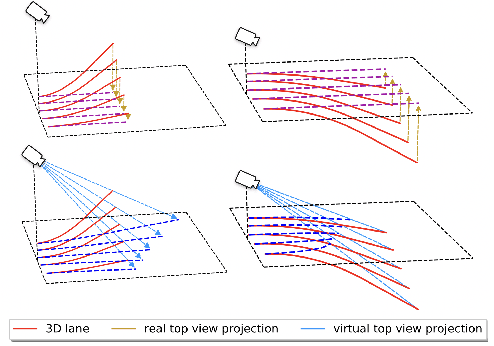

In this paper, we propose an advanced approach in targeting the problem of monocular 3D lane detection by leveraging geometry structure underneath the process of 2D to 3D lane reconstruction. Inspired by previous methods, we first analyze the geometry heuristic between the 3D lane and its 2D representation on the ground and propose to impose explicit supervision based on the structure prior, which makes it achievable to build inter-lane and intra-lane relationships to facilitate the reconstruction of 3D lanes from local to global. Second, to reduce the structure loss in 2D lane representation, we directly extract top view lane information from front view images, which tremendously eases the confusion of distant lane features in previous methods. Furthermore, we propose a novel task-specific data augmentation method by synthesizing new training data for both segmentation and reconstruction tasks in our pipeline, to counter the imbalanced data distribution of camera pose and ground slope to improve generalization on unseen data. Our work marks the first attempt to employ the geometry prior information into DNN-based 3D lane detection and makes it achievable for detecting lanes in an extra-long distance, doubling the original detection range. The proposed method can be smoothly adopted by other frameworks without extra costs. Experimental results show that our work outperforms state-of-the-art approaches by 3.8% F-Score on Apollo 3D synthetic dataset at real-time speed of 82 FPS without introducing extra parameters.
Physically-Based Editing of Indoor Scene Lighting from a Single Image
May 19, 2022
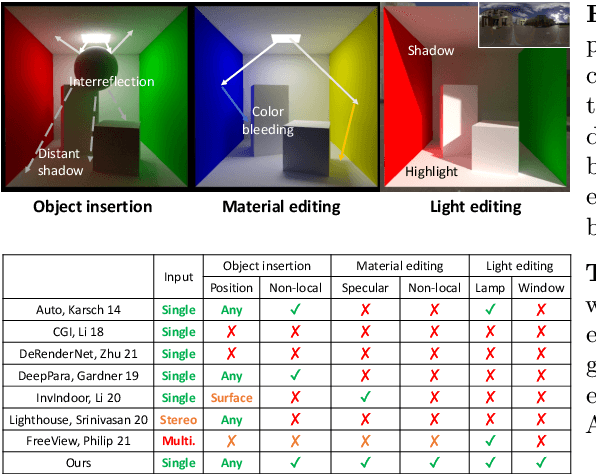
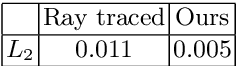
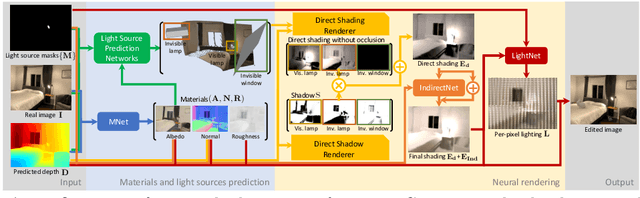
We present a method to edit complex indoor lighting from a single image with its predicted depth and light source segmentation masks. This is an extremely challenging problem that requires modeling complex light transport, and disentangling HDR lighting from material and geometry with only a partial LDR observation of the scene. We tackle this problem using two novel components: 1) a holistic scene reconstruction method that estimates scene reflectance and parametric 3D lighting, and 2) a neural rendering framework that re-renders the scene from our predictions. We use physically-based indoor light representations that allow for intuitive editing, and infer both visible and invisible light sources. Our neural rendering framework combines physically-based direct illumination and shadow rendering with deep networks to approximate global illumination. It can capture challenging lighting effects, such as soft shadows, directional lighting, specular materials, and interreflections. Previous single image inverse rendering methods usually entangle scene lighting and geometry and only support applications like object insertion. Instead, by combining parametric 3D lighting estimation with neural scene rendering, we demonstrate the first automatic method to achieve full scene relighting, including light source insertion, removal, and replacement, from a single image. All source code and data will be publicly released.
The CLEAR Benchmark: Continual LEArning on Real-World Imagery
Jan 17, 2022
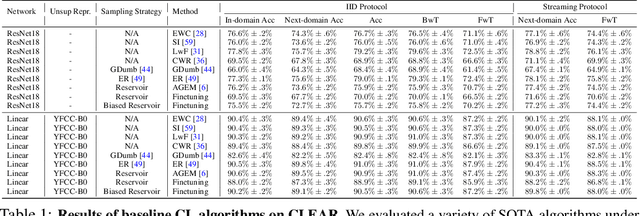
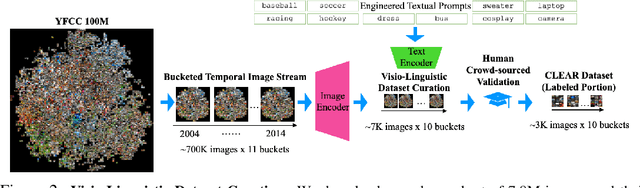
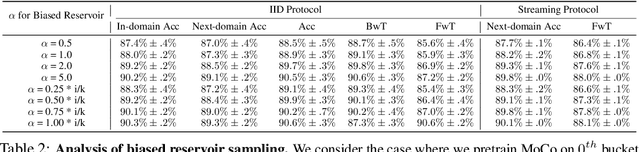
Continual learning (CL) is widely regarded as crucial challenge for lifelong AI. However, existing CL benchmarks, e.g. Permuted-MNIST and Split-CIFAR, make use of artificial temporal variation and do not align with or generalize to the real-world. In this paper, we introduce CLEAR, the first continual image classification benchmark dataset with a natural temporal evolution of visual concepts in the real world that spans a decade (2004-2014). We build CLEAR from existing large-scale image collections (YFCC100M) through a novel and scalable low-cost approach to visio-linguistic dataset curation. Our pipeline makes use of pretrained vision-language models (e.g. CLIP) to interactively build labeled datasets, which are further validated with crowd-sourcing to remove errors and even inappropriate images (hidden in original YFCC100M). The major strength of CLEAR over prior CL benchmarks is the smooth temporal evolution of visual concepts with real-world imagery, including both high-quality labeled data along with abundant unlabeled samples per time period for continual semi-supervised learning. We find that a simple unsupervised pre-training step can already boost state-of-the-art CL algorithms that only utilize fully-supervised data. Our analysis also reveals that mainstream CL evaluation protocols that train and test on iid data artificially inflate performance of CL system. To address this, we propose novel "streaming" protocols for CL that always test on the (near) future. Interestingly, streaming protocols (a) can simplify dataset curation since today's testset can be repurposed for tomorrow's trainset and (b) can produce more generalizable models with more accurate estimates of performance since all labeled data from each time-period is used for both training and testing (unlike classic iid train-test splits).
Covert Beamforming Design for Intelligent Reflecting Surface Assisted IoT Networks
Sep 01, 2021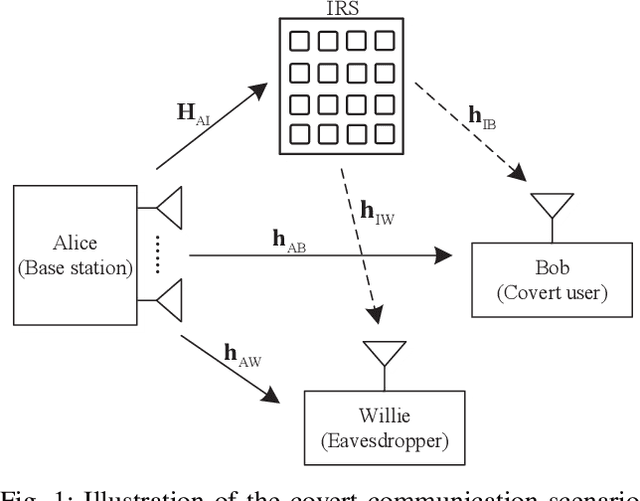
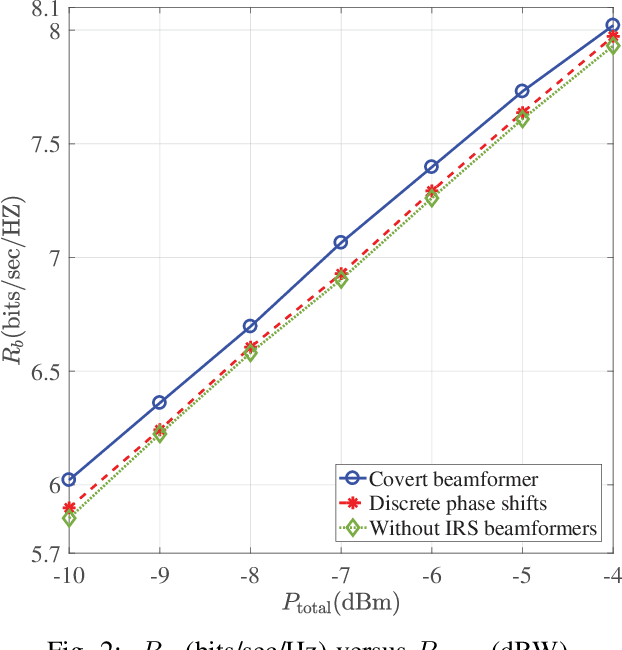
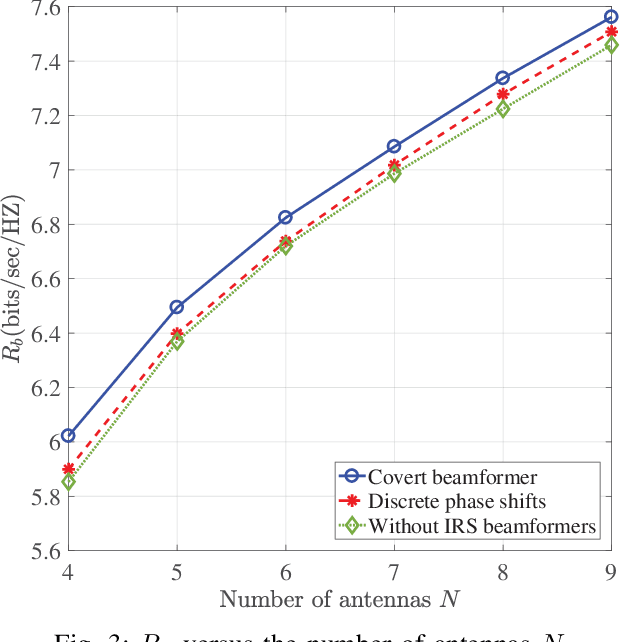
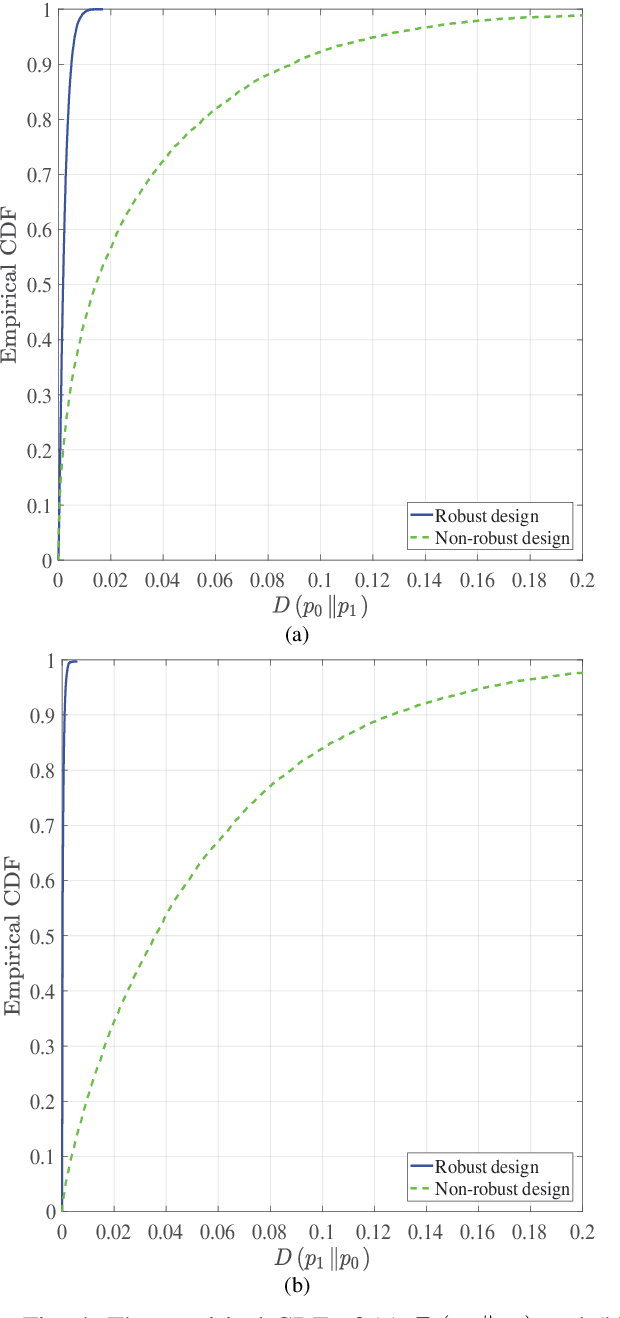
In this paper, we consider covert beamforming design for intelligent reflecting surface (IRS) assisted Internet of Things (IoT) networks, where Alice utilizes IRS to covertly transmit a message to Bob without being recognized by Willie. We investigate the joint beamformer design of Alice and IRS to maximize the covert rate of Bob when the knowledge about Willie's channel state information (WCSI) is perfect and imperfect at Alice, respectively. For the former case, we develop a covert beamformer under the perfect covert constraint by applying semidefinite relaxation. For the later case, the optimal decision threshold of Willie is derived, and we analyze the false alarm and the missed detection probabilities. Furthermore, we utilize the property of Kullback-Leibler divergence to develop the robust beamformer based on a relaxation, S-Lemma and alternate iteration approach. Finally, the numerical experiments evaluate the performance of the proposed covert beamformer design and robust beamformer design.