 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Real-World Datasets Contain Natural Experiments? An Empirical Study Using Causal Feature Selection
Jun 02, 2026In nature, events that affect some individuals or groups but not others constitute an implicit intervention and are known as natural experiments. For example, the COVID-19 pandemic was an intervention by the coronavirus on the sub-population infected with COVID. We ask, do natural experiments occur in existing real-world datasets? If yes, how should we treat them? To detect natural experiments in data, we use causal discovery to recover the underlying causal graph and perform feature selection based on causal links. If downstream performance improves by treating the data as interventional rather than observational, we argue that this suggests the dataset contains natural experiments. We first validate this hypothesis by simulating datasets with and without natural experiments using synthetic graphs. We then perform a systematic empirical evaluation on a large suite of real-world datasets. Our results indicate that real-world datasets do contain natural experiments and we can take advantage of those natural experiments to improve model performance using causal inference. Our work represents the initial foray into this area, offering a preliminary exploration within a limited scope.
LEARNER: Learning Granular Labels from Coarse Labels using Contrastive Learning
Nov 02, 2024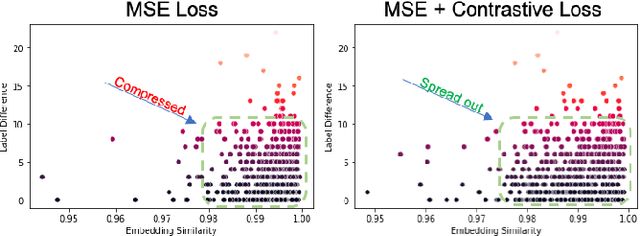

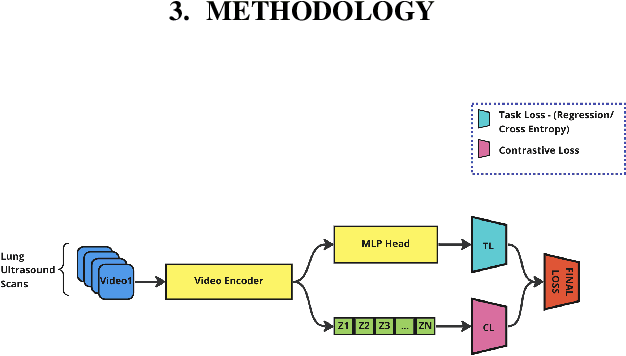
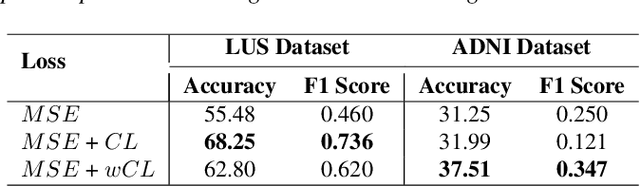
A crucial question in active patient care is determining if a treatment is having the desired effect, especially when changes are subtle over short periods. We propose using inter-patient data to train models that can learn to detect these fine-grained changes within a single patient. Specifically, can a model trained on multi-patient scans predict subtle changes in an individual patient's scans? Recent years have seen increasing use of deep learning (DL) in predicting diseases using biomedical imaging, such as predicting COVID-19 severity using lung ultrasound (LUS) data. While extensive literature exists on successful applications of DL systems when well-annotated large-scale datasets are available, it is quite difficult to collect a large corpus of personalized datasets for an individual. In this work, we investigate the ability of recent computer vision models to learn fine-grained differences while being trained on data showing larger differences. We evaluate on an in-house LUS dataset and a public ADNI brain MRI dataset. We find that models pre-trained on clips from multiple patients can better predict fine-grained differences in scans from a single patient by employing contrastive learning.
LCA-on-the-Line: Benchmarking Out-of-Distribution Generalization with Class Taxonomies
Jul 22, 2024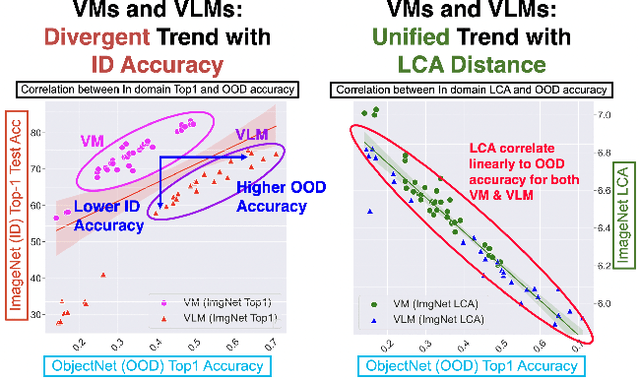
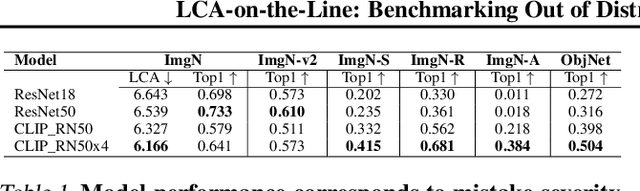
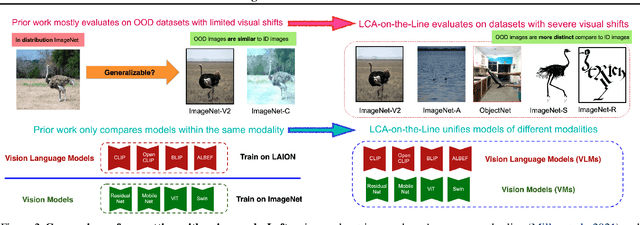
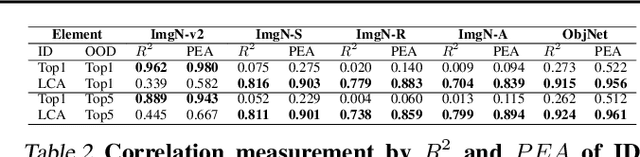
We tackle the challenge of predicting models' Out-of-Distribution (OOD) performance using in-distribution (ID) measurements without requiring OOD data. Existing evaluations with "Effective Robustness", which use ID accuracy as an indicator of OOD accuracy, encounter limitations when models are trained with diverse supervision and distributions, such as class labels (Vision Models, VMs, on ImageNet) and textual descriptions (Visual-Language Models, VLMs, on LAION). VLMs often generalize better to OOD data than VMs despite having similar or lower ID performance. To improve the prediction of models' OOD performance from ID measurements, we introduce the Lowest Common Ancestor (LCA)-on-the-Line framework. This approach revisits the established concept of LCA distance, which measures the hierarchical distance between labels and predictions within a predefined class hierarchy, such as WordNet. We assess 75 models using ImageNet as the ID dataset and five significantly shifted OOD variants, uncovering a strong linear correlation between ID LCA distance and OOD top-1 accuracy. Our method provides a compelling alternative for understanding why VLMs tend to generalize better. Additionally, we propose a technique to construct a taxonomic hierarchy on any dataset using K-means clustering, demonstrating that LCA distance is robust to the constructed taxonomic hierarchy. Moreover, we demonstrate that aligning model predictions with class taxonomies, through soft labels or prompt engineering, can enhance model generalization. Open source code in our Project Page: https://elvishelvis.github.io/papers/lca/.