 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEARNER: Learning Granular Labels from Coarse Labels using Contrastive Learning
Nov 02, 2024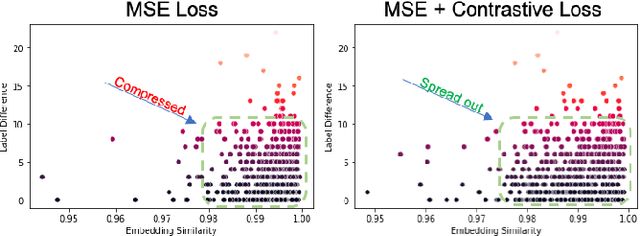

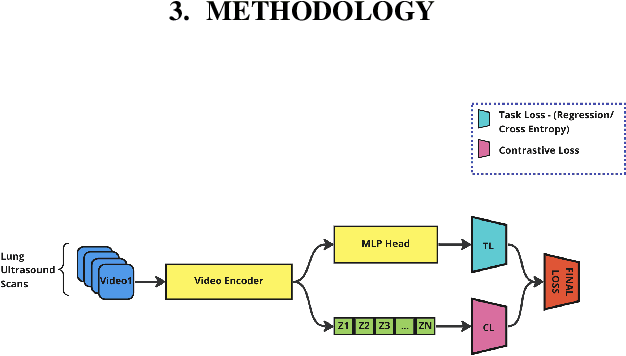
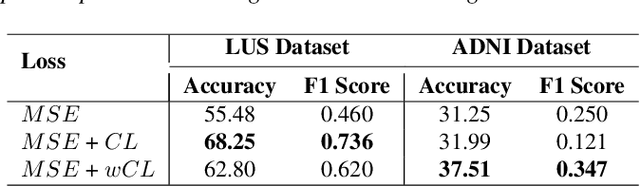
A crucial question in active patient care is determining if a treatment is having the desired effect, especially when changes are subtle over short periods. We propose using inter-patient data to train models that can learn to detect these fine-grained changes within a single patient. Specifically, can a model trained on multi-patient scans predict subtle changes in an individual patient's scans? Recent years have seen increasing use of deep learning (DL) in predicting diseases using biomedical imaging, such as predicting COVID-19 severity using lung ultrasound (LUS) data. While extensive literature exists on successful applications of DL systems when well-annotated large-scale datasets are available, it is quite difficult to collect a large corpus of personalized datasets for an individual. In this work, we investigate the ability of recent computer vision models to learn fine-grained differences while being trained on data showing larger differences. We evaluate on an in-house LUS dataset and a public ADNI brain MRI dataset. We find that models pre-trained on clips from multiple patients can better predict fine-grained differences in scans from a single patient by employing contrastive learning.
3D-GRAND: A Million-Scale Dataset for 3D-LLMs with Better Grounding and Less Hallucination
Jun 12, 2024



The integration of language and 3D perception is crucial for developing embodied agents and robots that comprehend and interact with the physical world. While large language models (LLMs) have demonstrated impressive language understanding and generation capabilities, their adaptation to 3D environments (3D-LLMs) remains in its early stages. A primary challenge is the absence of large-scale datasets that provide dense grounding between language and 3D scenes. In this paper, we introduce 3D-GRAND, a pioneering large-scale dataset comprising 40,087 household scenes paired with 6.2 million densely-grounded scene-language instructions. Our results show that instruction tuning with 3D-GRAND significantly enhances grounding capabilities and reduces hallucinations in 3D-LLMs. As part of our contributions, we propose a comprehensive benchmark 3D-POPE to systematically evaluate hallucination in 3D-LLMs, enabling fair comparisons among future models. Our experiments highlight a scaling effect between dataset size and 3D-LLM performance, emphasizing the critical role of large-scale 3D-text datasets in advancing embodied AI research. Notably, our results demonstrate early signals for effective sim-to-real transfer, indicating that models trained on large synthetic data can perform well on real-world 3D scans. Through 3D-GRAND and 3D-POPE, we aim to equip the embodied AI community with essential resources and insights, setting the stage for more reliable and better-grounded 3D-LLMs. Project website: https://3d-grand.github.io
3D-GRAND: Towards Better Grounding and Less Hallucination for 3D-LLMs
Jun 07, 2024The integration of language and 3D perception is crucial for developing embodied agents and robots that comprehend and interact with the physical world. While large language models (LLMs) have demonstrated impressive language understanding and generation capabilities, their adaptation to 3D environments (3D-LLMs) remains in its early stages. A primary challenge is the absence of large-scale datasets that provide dense grounding between language and 3D scenes. In this paper, we introduce 3D-GRAND, a pioneering large-scale dataset comprising 40,087 household scenes paired with 6.2 million densely-grounded scene-language instructions. Our results show that instruction tuning with 3D-GRAND significantly enhances grounding capabilities and reduces hallucinations in 3D-LLMs. As part of our contributions, we propose a comprehensive benchmark 3D-POPE to systematically evaluate hallucination in 3D-LLMs, enabling fair comparisons among future models. Our experiments highlight a scaling effect between dataset size and 3D-LLM performance, emphasizing the critical role of large-scale 3D-text datasets in advancing embodied AI research. Notably, our results demonstrate early signals for effective sim-to-real transfer, indicating that models trained on large synthetic data can perform well on real-world 3D scans. Through 3D-GRAND and 3D-POPE, we aim to equip the embodied AI community with essential resources and insights, setting the stage for more reliable and better-grounded 3D-LLMs. Project website: https://3d-grand.github.io
Adversarial Robustness Unhardening via Backdoor Attacks in Federated Learning
Oct 21, 2023



In today's data-driven landscape, the delicate equilibrium between safeguarding user privacy and unleashing data potential stands as a paramount concern. Federated learning, which enables collaborative model training without necessitating data sharing, has emerged as a privacy-centric solution. This decentralized approach brings forth security challenges, notably poisoning and backdoor attacks where malicious entities inject corrupted data. Our research, initially spurred by test-time evasion attacks, investigates the intersection of adversarial training and backdoor attacks within federated learning, introducing Adversarial Robustness Unhardening (ARU). ARU is employed by a subset of adversaries to intentionally undermine model robustness during decentralized training, rendering models susceptible to a broader range of evasion attacks. We present extensive empirical experiments evaluating ARU's impact on adversarial training and existing robust aggregation defenses against poisoning and backdoor attacks. Our findings inform strategies for enhancing ARU to counter current defensive measures and highlight the limitations of existing defenses, offering insights into bolstering defenses against ARU.
LLM-Grounder: Open-Vocabulary 3D Visual Grounding with Large Language Model as an Agent
Sep 21, 2023



3D visual grounding is a critical skill for household robots, enabling them to navigate, manipulate objects, and answer questions based on their environment. While existing approaches often rely on extensive labeled data or exhibit limitations in handling complex language queries, we propose LLM-Grounder, a novel zero-shot, open-vocabulary, Large Language Model (LLM)-based 3D visual grounding pipeline. LLM-Grounder utilizes an LLM to decompose complex natural language queries into semantic constituents and employs a visual grounding tool, such as OpenScene or LERF, to identify objects in a 3D scene. The LLM then evaluates the spatial and commonsense relations among the proposed objects to make a final grounding decision. Our method does not require any labeled training data and can generalize to novel 3D scenes and arbitrary text queries. We evaluate LLM-Grounder on the ScanRefer benchmark and demonstrate state-of-the-art zero-shot grounding accuracy. Our findings indicate that LLMs significantly improve the grounding capability, especially for complex language queries, making LLM-Grounder an effective approach for 3D vision-language tasks in robotics. Videos and interactive demos can be found on the project website https://chat-with-nerf.github.io/ .
pFedDef: Defending Grey-Box Attacks for Personalized Federated Learning
Sep 17, 2022
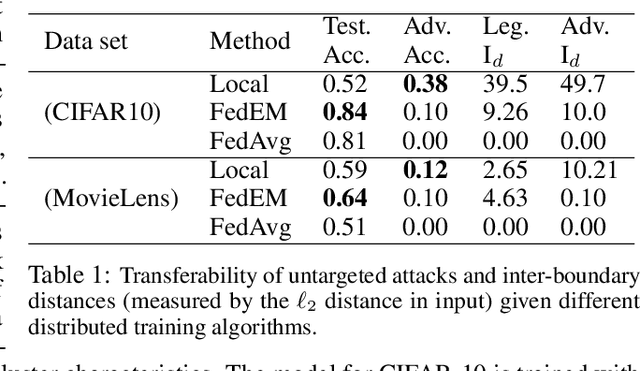
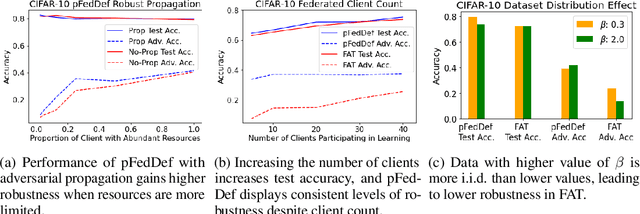

Personalized federated learning allows for clients in a distributed system to train a neural network tailored to their unique local data while leveraging information at other clients. However, clients' models are vulnerable to attacks during both the training and testing phases. In this paper we address the issue of adversarial clients crafting evasion attacks at test time to deceive other clients. For example, adversaries may aim to deceive spam filters and recommendation systems trained with personalized federated learning for monetary gain. The adversarial clients have varying degrees of personalization based on the method of distributed learning, leading to a "grey-box" situation. We are the first to characterize the transferability of such internal evasion attacks for different learning methods and analyze the trade-off between model accuracy and robustness depending on the degree of personalization and similarities in client data. We introduce a defense mechanism, pFedDef, that performs personalized federated adversarial training while respecting resource limitations at clients that inhibit adversarial training. Overall, pFedDef increases relative grey-box adversarial robustness by 62% compared to federated adversarial training and performs well even under limited system resources.