 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWildRayZer: Self-supervised Large View Synthesis in Dynamic Environments
Jan 15, 2026We present WildRayZer, a self-supervised framework for novel view synthesis (NVS) in dynamic environments where both the camera and objects move. Dynamic content breaks the multi-view consistency that static NVS models rely on, leading to ghosting, hallucinated geometry, and unstable pose estimation. WildRayZer addresses this by performing an analysis-by-synthesis test: a camera-only static renderer explains rigid structure, and its residuals reveal transient regions. From these residuals, we construct pseudo motion masks, distill a motion estimator, and use it to mask input tokens and gate loss gradients so supervision focuses on cross-view background completion. To enable large-scale training and evaluation, we curate Dynamic RealEstate10K (D-RE10K), a real-world dataset of 15K casually captured dynamic sequences, and D-RE10K-iPhone, a paired transient and clean benchmark for sparse-view transient-aware NVS. Experiments show that WildRayZer consistently outperforms optimization-based and feed-forward baselines in both transient-region removal and full-frame NVS quality with a single feed-forward pass.
Next-Embedding Prediction Makes Strong Vision Learners
Dec 23, 2025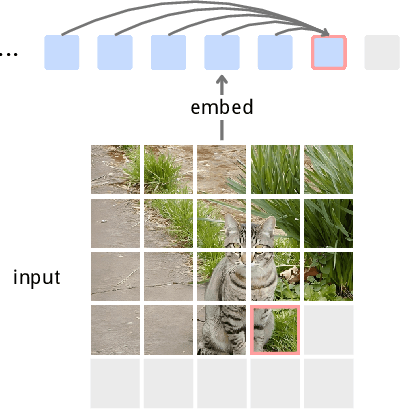
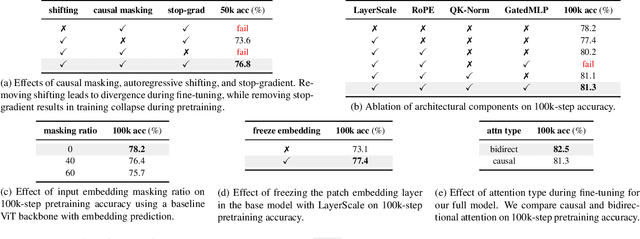
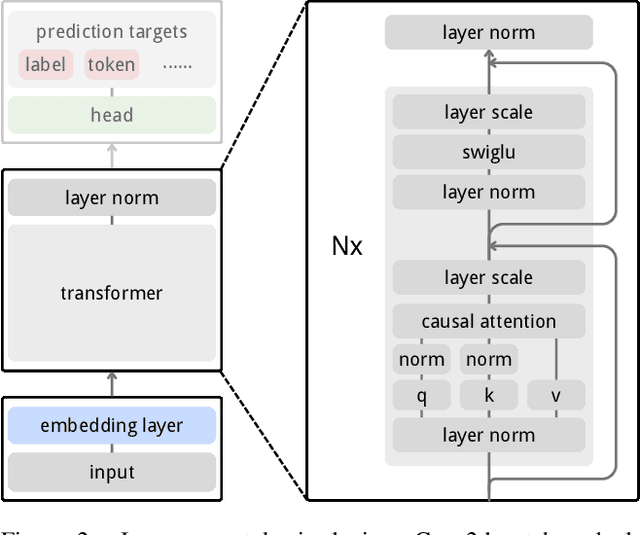
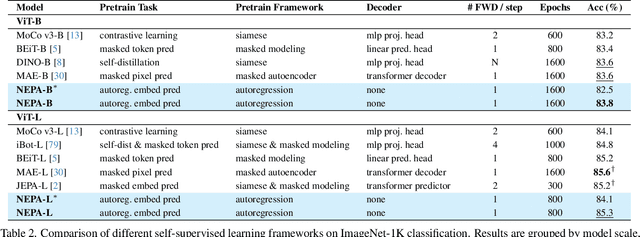
Inspired by the success of generative pretraining in natural language, we ask whether the same principles can yield strong self-supervised visual learners. Instead of training models to output features for downstream use, we train them to generate embeddings to perform predictive tasks directly. This work explores such a shift from learning representations to learning models. Specifically, models learn to predict future patch embeddings conditioned on past ones, using causal masking and stop gradient, which we refer to as Next-Embedding Predictive Autoregression (NEPA). We demonstrate that a simple Transformer pretrained on ImageNet-1k with next embedding prediction as its sole learning objective is effective - no pixel reconstruction, discrete tokens, contrastive loss, or task-specific heads. This formulation retains architectural simplicity and scalability, without requiring additional design complexity. NEPA achieves strong results across tasks, attaining 83.8% and 85.3% top-1 accuracy on ImageNet-1K with ViT-B and ViT-L backbones after fine-tuning, and transferring effectively to semantic segmentation on ADE20K. We believe generative pretraining from embeddings provides a simple, scalable, and potentially modality-agnostic alternative to visual self-supervised learning.
Empowering Dynamic Urban Navigation with Stereo and Mid-Level Vision
Dec 11, 2025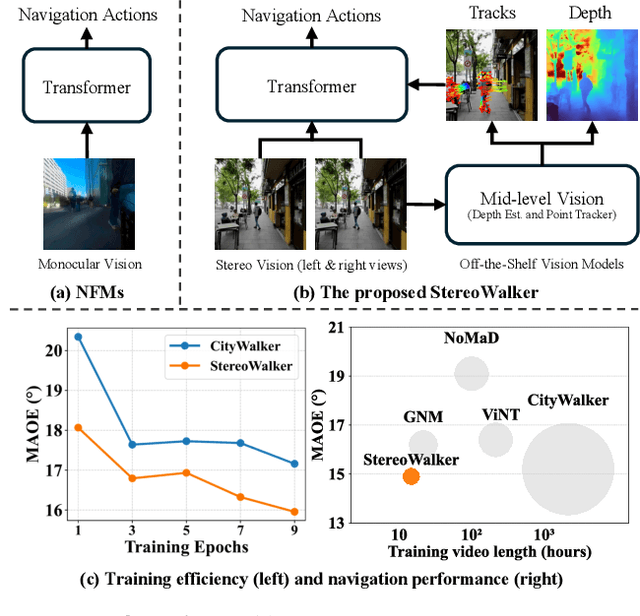
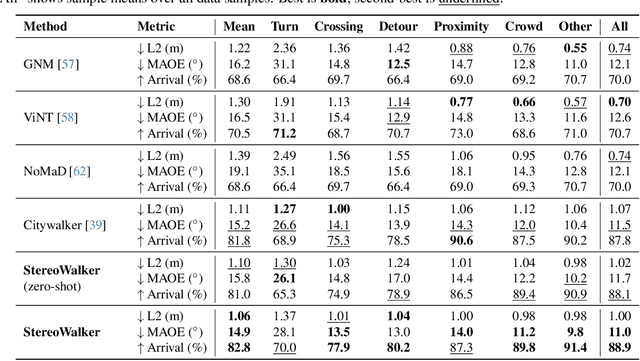
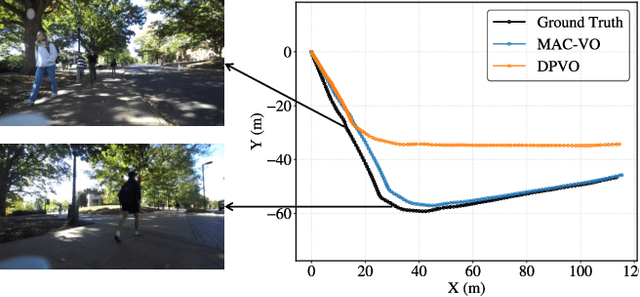
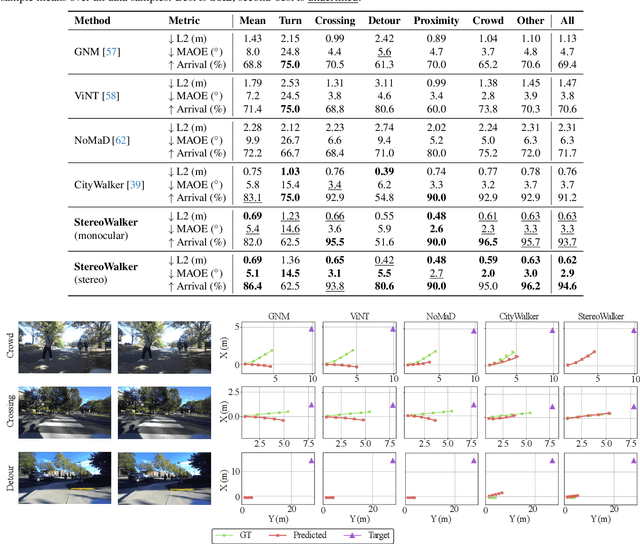
The success of foundation models in language and vision motivated research in fully end-to-end robot navigation foundation models (NFMs). NFMs directly map monocular visual input to control actions and ignore mid-level vision modules (tracking, depth estimation, etc) entirely. While the assumption that vision capabilities will emerge implicitly is compelling, it requires large amounts of pixel-to-action supervision that are difficult to obtain. The challenge is especially pronounced in dynamic and unstructured settings, where robust navigation requires precise geometric and dynamic understanding, while the depth-scale ambiguity in monocular views further limits accurate spatial reasoning. In this paper, we show that relying on monocular vision and ignoring mid-level vision priors is inefficient. We present StereoWalker, which augments NFMs with stereo inputs and explicit mid-level vision such as depth estimation and dense pixel tracking. Our intuition is straightforward: stereo inputs resolve the depth-scale ambiguity, and modern mid-level vision models provide reliable geometric and motion structure in dynamic scenes. We also curate a large stereo navigation dataset with automatic action annotation from Internet stereo videos to support training of StereoWalker and to facilitate future research. Through our experiments, we find that mid-level vision enables StereoWalker to achieve a comparable performance as the state-of-the-art using only 1.5% of the training data, and surpasses the state-of-the-art using the full data. We also observe that stereo vision yields higher navigation performance than monocular input.
4D-LRM: Large Space-Time Reconstruction Model From and To Any View at Any Time
Jun 23, 2025Can we scale 4D pretraining to learn general space-time representations that reconstruct an object from a few views at some times to any view at any time? We provide an affirmative answer with 4D-LRM, the first large-scale 4D reconstruction model that takes input from unconstrained views and timestamps and renders arbitrary novel view-time combinations. Unlike prior 4D approaches, e.g., optimization-based, geometry-based, or generative, that struggle with efficiency, generalization, or faithfulness, 4D-LRM learns a unified space-time representation and directly predicts per-pixel 4D Gaussian primitives from posed image tokens across time, enabling fast, high-quality rendering at, in principle, infinite frame rate. Our results demonstrate that scaling spatiotemporal pretraining enables accurate and efficient 4D reconstruction. We show that 4D-LRM generalizes to novel objects, interpolates across time, and handles diverse camera setups. It reconstructs 24-frame sequences in one forward pass with less than 1.5 seconds on a single A100 GPU.
Point-MoE: Towards Cross-Domain Generalization in 3D Semantic Segmentation via Mixture-of-Experts
May 29, 2025While scaling laws have transformed natural language processing and computer vision, 3D point cloud understanding has yet to reach that stage. This can be attributed to both the comparatively smaller scale of 3D datasets, as well as the disparate sources of the data itself. Point clouds are captured by diverse sensors (e.g., depth cameras, LiDAR) across varied domains (e.g., indoor, outdoor), each introducing unique scanning patterns, sampling densities, and semantic biases. Such domain heterogeneity poses a major barrier towards training unified models at scale, especially under the realistic constraint that domain labels are typically inaccessible at inference time. In this work, we propose Point-MoE, a Mixture-of-Experts architecture designed to enable large-scale, cross-domain generalization in 3D perception. We show that standard point cloud backbones degrade significantly in performance when trained on mixed-domain data, whereas Point-MoE with a simple top-k routing strategy can automatically specialize experts, even without access to domain labels. Our experiments demonstrate that Point-MoE not only outperforms strong multi-domain baselines but also generalizes better to unseen domains. This work highlights a scalable path forward for 3D understanding: letting the model discover structure in diverse 3D data, rather than imposing it via manual curation or domain supervision.
Frame In-N-Out: Unbounded Controllable Image-to-Video Generation
May 27, 2025Controllability, temporal coherence, and detail synthesis remain the most critical challenges in video generation. In this paper, we focus on a commonly used yet underexplored cinematic technique known as Frame In and Frame Out. Specifically, starting from image-to-video generation, users can control the objects in the image to naturally leave the scene or provide breaking new identity references to enter the scene, guided by user-specified motion trajectory. To support this task, we introduce a new dataset curated semi-automatically, a comprehensive evaluation protocol targeting this setting, and an efficient identity-preserving motion-controllable video Diffusion Transformer architecture. Our evaluation shows that our proposed approach significantly outperforms existing baselines.
Probing the Mid-level Vision Capabilities of Self-Supervised Learning
Nov 25, 2024



Mid-level vision capabilities - such as generic object localization and 3D geometric understanding - are not only fundamental to human vision but are also crucial for many real-world applications of computer vision. These abilities emerge with minimal supervision during the early stages of human visual development. Despite their significance, current self-supervised learning (SSL) approaches are primarily designed and evaluated for high-level recognition tasks, leaving their mid-level vision capabilities largely unexamined. In this study, we introduce a suite of benchmark protocols to systematically assess mid-level vision capabilities and present a comprehensive, controlled evaluation of 22 prominent SSL models across 8 mid-level vision tasks. Our experiments reveal a weak correlation between mid-level and high-level task performance. We also identify several SSL methods with highly imbalanced performance across mid-level and high-level capabilities, as well as some that excel in both. Additionally, we investigate key factors contributing to mid-level vision performance, such as pretraining objectives and network architectures. Our study provides a holistic and timely view of what SSL models have learned, complementing existing research that primarily focuses on high-level vision tasks. We hope our findings guide future SSL research to benchmark models not only on high-level vision tasks but on mid-level as well.
Learning 3D Representations from Procedural 3D Programs
Nov 25, 2024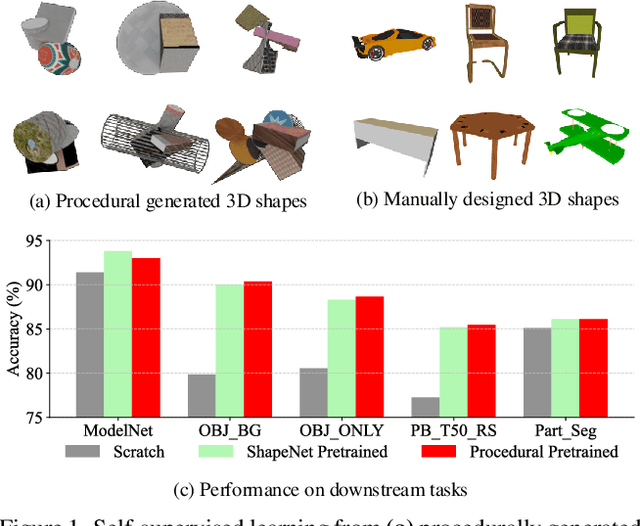
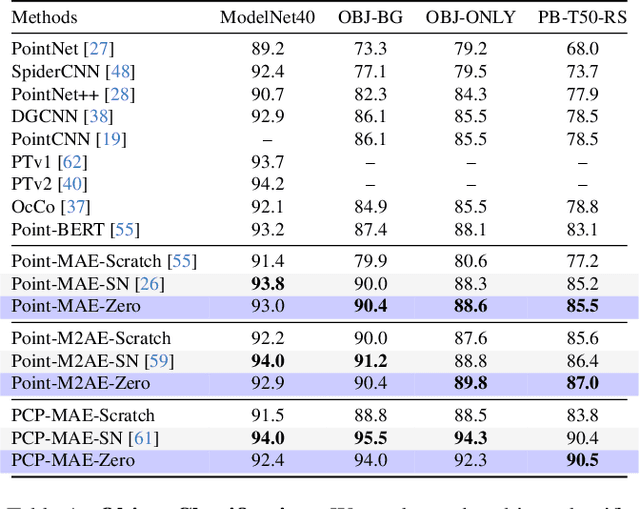
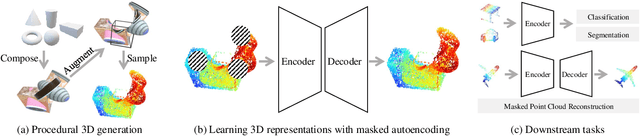
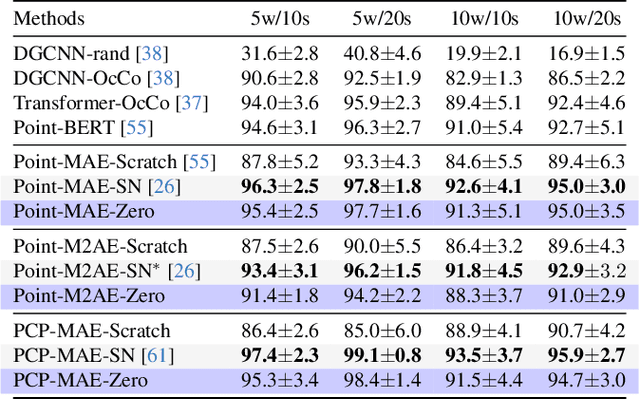
Self-supervised learning has emerged as a promising approach for acquiring transferable 3D representations from unlabeled 3D point clouds. Unlike 2D images, which are widely accessible, acquiring 3D assets requires specialized expertise or professional 3D scanning equipment, making it difficult to scale and raising copyright concerns. To address these challenges, we propose learning 3D representations from procedural 3D programs that automatically generate 3D shapes using simple primitives and augmentations. Remarkably, despite lacking semantic content, the 3D representations learned from this synthesized dataset perform on par with state-of-the-art representations learned from semantically recognizable 3D models (e.g., airplanes) across various downstream 3D tasks, including shape classification, part segmentation, and masked point cloud completion. Our analysis further suggests that current self-supervised learning methods primarily capture geometric structures rather than high-level semantics.
Open Vocabulary Monocular 3D Object Detection
Nov 25, 2024In this work, we pioneer the study of open-vocabulary monocular 3D object detection, a novel task that aims to detect and localize objects in 3D space from a single RGB image without limiting detection to a predefined set of categories. We formalize this problem, establish baseline methods, and introduce a class-agnostic approach that leverages open-vocabulary 2D detectors and lifts 2D bounding boxes into 3D space. Our approach decouples the recognition and localization of objects in 2D from the task of estimating 3D bounding boxes, enabling generalization across unseen categories. Additionally, we propose a target-aware evaluation protocol to address inconsistencies in existing datasets, improving the reliability of model performance assessment. Extensive experiments on the Omni3D dataset demonstrate the effectiveness of the proposed method in zero-shot 3D detection for novel object categories, validating its robust generalization capabilities. Our method and evaluation protocols contribute towards the development of open-vocabulary object detection models that can effectively operate in real-world, category-diverse environments.
Multi-Object Hallucination in Vision-Language Models
Jul 08, 2024



Large vision language models (LVLMs) often suffer from object hallucination, producing objects not present in the given images. While current benchmarks for object hallucination primarily concentrate on the presence of a single object class rather than individual entities, this work systematically investigates multi-object hallucination, examining how models misperceive (e.g., invent nonexistent objects or become distracted) when tasked with focusing on multiple objects simultaneously. We introduce Recognition-based Object Probing Evaluation (ROPE), an automated evaluation protocol that considers the distribution of object classes within a single image during testing and uses visual referring prompts to eliminate ambiguity. With comprehensive empirical studies and analysis of potential factors leading to multi-object hallucination, we found that (1) LVLMs suffer more hallucinations when focusing on multiple objects compared to a single object. (2) The tested object class distribution affects hallucination behaviors, indicating that LVLMs may follow shortcuts and spurious correlations.(3) Hallucinatory behaviors are influenced by data-specific factors, salience and frequency, and model intrinsic behaviors. We hope to enable LVLMs to recognize and reason about multiple objects that often occur in realistic visual scenes, provide insights, and quantify our progress towards mitigating the issues.