 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniCtrl: Improving the Spatiotemporal Consistency of Text-to-Video Diffusion Models via Training-Free Unified Attention Control
Paper and Code



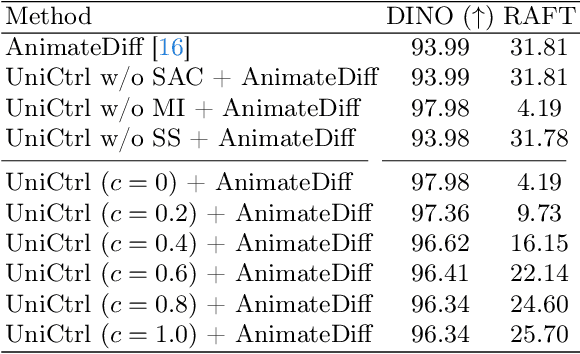
Video Diffusion Models have been developed for video generation, usually integrating text and image conditioning to enhance control over the generated content. Despite the progress, ensuring consistency across frames remains a challenge, particularly when using text prompts as control conditions. To address this problem, we introduce UniCtrl, a novel, plug-and-play method that is universally applicable to improve the spatiotemporal consistency and motion diversity of videos generated by text-to-video models without additional training. UniCtrl ensures semantic consistency across different frames through cross-frame self-attention control, and meanwhile, enhances the motion quality and spatiotemporal consistency through motion injection and spatiotemporal synchronization. Our experimental results demonstrate UniCtrl's efficacy in enhancing various text-to-video models, confirming its effectiveness and universality.