 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecursive Flow Matching
May 26, 2026Generative models have emerged as a powerful paradigm for solving physics systems and modeling complex spatiotemporal dynamics. However, achieving high physical accuracy without incurring high computational cost remains a fundamental challenge, as existing approaches face a critical speed-fidelity trade-off. In this work, we introduce Recursive Flow Matching (RecFM), a generative framework for forecasting complex spatiotemporal dynamics. RecFM enforces self-consistency to align trajectories across discretization scales, reducing discretization errors and improving performance across metrics for physics-based tasks. To our knowledge, this is the first method to achieve high-fidelity one- and few-step (2-4 step) dynamic generation for scientific systems with performance comparable to state-of-the-art multi-step solvers. Across challenging scientific benchmarks, RecFM achieves up to a 20$\times$ speedup over leading diffusion-based emulators while improving predictive accuracy. Furthermore, RecFM reduces mean squared error by over 15% compared to vanilla flow matching, offering a scalable and efficient solution for real-time scientific emulation.
Beyond Immediate Activation: Temporally Decoupled Backdoor Attacks on Time Series Forecasting
Jan 06, 2026Existing backdoor attacks on multivariate time series (MTS) forecasting enforce strict temporal and dimensional coupling between triggers and target patterns, requiring synchronous activation at fixed positions across variables. However, realistic scenarios often demand delayed and variable-specific activation. We identify this critical unmet need and propose TDBA, a temporally decoupled backdoor attack framework for MTS forecasting. By injecting triggers that encode the expected location of the target pattern, TDBA enables the activation of the target pattern at any positions within the forecasted data, with the activation position flexibly varying across different variable dimensions. TDBA introduces two core modules: (1) a position-guided trigger generation mechanism that leverages smoothed Gaussian priors to generate triggers that are position-related to the predefined target pattern; and (2) a position-aware optimization module that assigns soft weights based on trigger completeness, pattern coverage, and temporal offset, facilitating targeted and stealthy attack optimization. Extensive experiments on real-world datasets show that TDBA consistently outperforms existing baselines in effectiveness while maintaining good stealthiness. Ablation studies confirm the controllability and robustness of its design.
Next-Embedding Prediction Makes Strong Vision Learners
Dec 23, 2025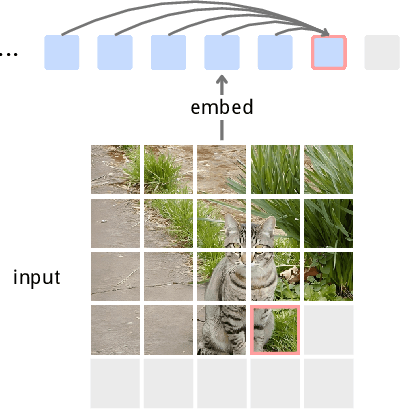
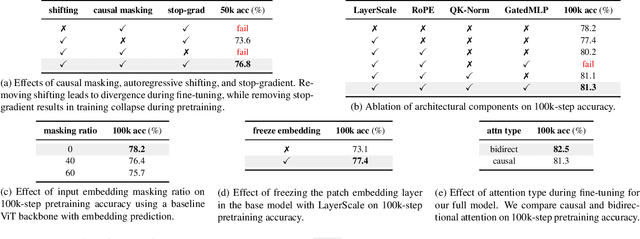
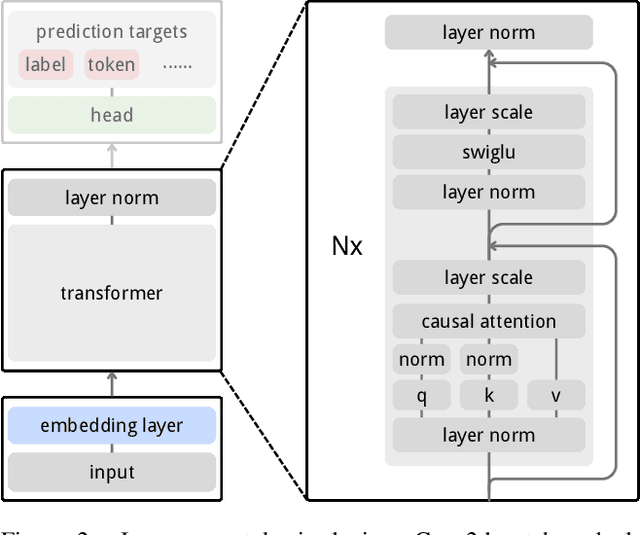
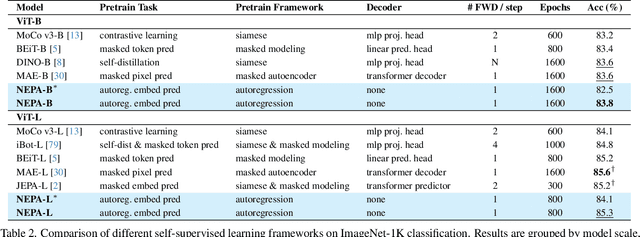
Inspired by the success of generative pretraining in natural language, we ask whether the same principles can yield strong self-supervised visual learners. Instead of training models to output features for downstream use, we train them to generate embeddings to perform predictive tasks directly. This work explores such a shift from learning representations to learning models. Specifically, models learn to predict future patch embeddings conditioned on past ones, using causal masking and stop gradient, which we refer to as Next-Embedding Predictive Autoregression (NEPA). We demonstrate that a simple Transformer pretrained on ImageNet-1k with next embedding prediction as its sole learning objective is effective - no pixel reconstruction, discrete tokens, contrastive loss, or task-specific heads. This formulation retains architectural simplicity and scalability, without requiring additional design complexity. NEPA achieves strong results across tasks, attaining 83.8% and 85.3% top-1 accuracy on ImageNet-1K with ViT-B and ViT-L backbones after fine-tuning, and transferring effectively to semantic segmentation on ADE20K. We believe generative pretraining from embeddings provides a simple, scalable, and potentially modality-agnostic alternative to visual self-supervised learning.
4D-LRM: Large Space-Time Reconstruction Model From and To Any View at Any Time
Jun 23, 2025Can we scale 4D pretraining to learn general space-time representations that reconstruct an object from a few views at some times to any view at any time? We provide an affirmative answer with 4D-LRM, the first large-scale 4D reconstruction model that takes input from unconstrained views and timestamps and renders arbitrary novel view-time combinations. Unlike prior 4D approaches, e.g., optimization-based, geometry-based, or generative, that struggle with efficiency, generalization, or faithfulness, 4D-LRM learns a unified space-time representation and directly predicts per-pixel 4D Gaussian primitives from posed image tokens across time, enabling fast, high-quality rendering at, in principle, infinite frame rate. Our results demonstrate that scaling spatiotemporal pretraining enables accurate and efficient 4D reconstruction. We show that 4D-LRM generalizes to novel objects, interpolates across time, and handles diverse camera setups. It reconstructs 24-frame sequences in one forward pass with less than 1.5 seconds on a single A100 GPU.
Vision-Language Models Are Not Pragmatically Competent in Referring Expression Generation
Apr 22, 2025
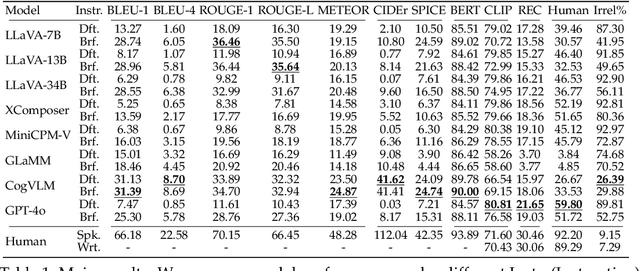

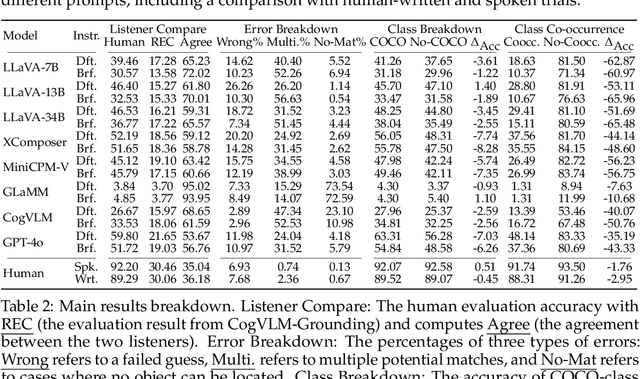
Referring Expression Generation (REG) is a core task for evaluating the pragmatic competence of vision-language systems, requiring not only accurate semantic grounding but also adherence to principles of cooperative communication (Grice, 1975). However, current evaluations of vision-language models (VLMs) often overlook the pragmatic dimension, reducing REG to a region-based captioning task and neglecting Gricean maxims. In this work, we revisit REG from a pragmatic perspective, introducing a new dataset (RefOI) of 1.5k images annotated with both written and spoken referring expressions. Through a systematic evaluation of state-of-the-art VLMs, we identify three key failures of pragmatic competence: (1) failure to uniquely identify the referent, (2) inclusion of excessive or irrelevant information, and (3) misalignment with human pragmatic preference, such as the underuse of minimal spatial cues. We also show that standard automatic evaluations fail to capture these pragmatic violations, reinforcing superficial cues rather than genuine referential success. Our findings call for a renewed focus on pragmatically informed models and evaluation frameworks that align with real human communication.
Multi-Object Hallucination in Vision-Language Models
Jul 08, 2024



Large vision language models (LVLMs) often suffer from object hallucination, producing objects not present in the given images. While current benchmarks for object hallucination primarily concentrate on the presence of a single object class rather than individual entities, this work systematically investigates multi-object hallucination, examining how models misperceive (e.g., invent nonexistent objects or become distracted) when tasked with focusing on multiple objects simultaneously. We introduce Recognition-based Object Probing Evaluation (ROPE), an automated evaluation protocol that considers the distribution of object classes within a single image during testing and uses visual referring prompts to eliminate ambiguity. With comprehensive empirical studies and analysis of potential factors leading to multi-object hallucination, we found that (1) LVLMs suffer more hallucinations when focusing on multiple objects compared to a single object. (2) The tested object class distribution affects hallucination behaviors, indicating that LVLMs may follow shortcuts and spurious correlations.(3) Hallucinatory behaviors are influenced by data-specific factors, salience and frequency, and model intrinsic behaviors. We hope to enable LVLMs to recognize and reason about multiple objects that often occur in realistic visual scenes, provide insights, and quantify our progress towards mitigating the issues.
LAN: Learning Adaptive Neighbors for Real-Time Insider Threat Detection
Mar 17, 2024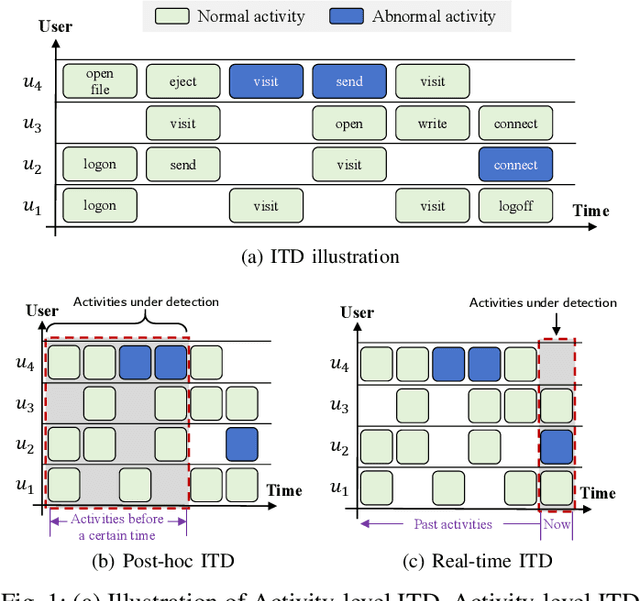
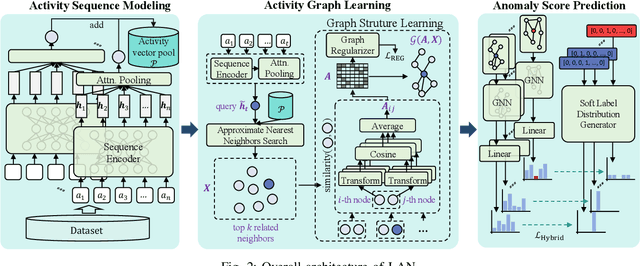
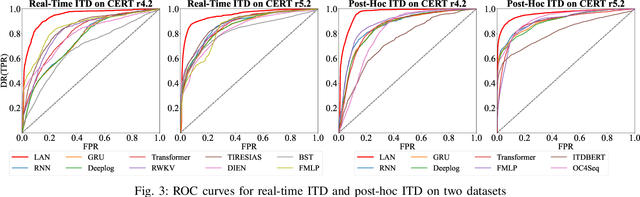
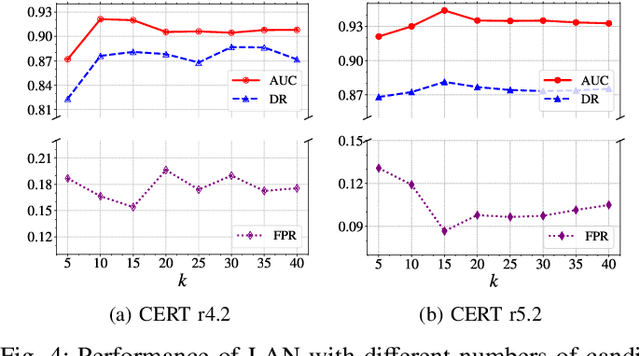
Enterprises and organizations are faced with potential threats from insider employees that may lead to serious consequences. Previous studies on insider threat detection (ITD) mainly focus on detecting abnormal users or abnormal time periods (e.g., a week or a day). However, a user may have hundreds of thousands of activities in the log, and even within a day there may exist thousands of activities for a user, requiring a high investigation budget to verify abnormal users or activities given the detection results. On the other hand, existing works are mainly post-hoc methods rather than real-time detection, which can not report insider threats in time before they cause loss. In this paper, we conduct the first study towards real-time ITD at activity level, and present a fine-grained and efficient framework LAN. Specifically, LAN simultaneously learns the temporal dependencies within an activity sequence and the relationships between activities across sequences with graph structure learning. Moreover, to mitigate the data imbalance problem in ITD, we propose a novel hybrid prediction loss, which integrates self-supervision signals from normal activities and supervision signals from abnormal activities into a unified loss for anomaly detection. We evaluate the performance of LAN on two widely used datasets, i.e., CERT r4.2 and CERT r5.2. Extensive and comparative experiments demonstrate the superiority of LAN, outperforming 9 state-of-the-art baselines by at least 9.92% and 6.35% in AUC for real-time ITD on CERT r4.2 and r5.2, respectively. Moreover, LAN can be also applied to post-hoc ITD, surpassing 8 competitive baselines by at least 7.70% and 4.03% in AUC on two datasets. Finally, the ablation study, parameter analysis, and compatibility analysis evaluate the impact of each module and hyper-parameter in LAN. The source code can be obtained from https://github.com/Li1Neo/LAN.
UniCtrl: Improving the Spatiotemporal Consistency of Text-to-Video Diffusion Models via Training-Free Unified Attention Control
Mar 06, 2024


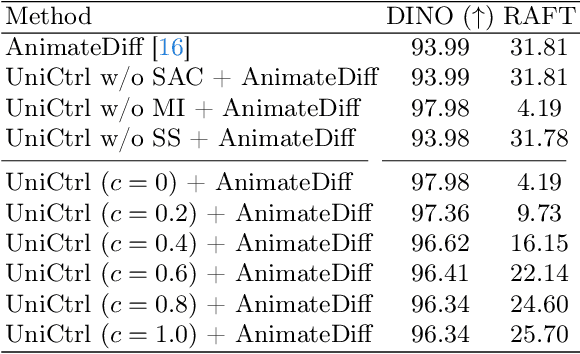
Video Diffusion Models have been developed for video generation, usually integrating text and image conditioning to enhance control over the generated content. Despite the progress, ensuring consistency across frames remains a challenge, particularly when using text prompts as control conditions. To address this problem, we introduce UniCtrl, a novel, plug-and-play method that is universally applicable to improve the spatiotemporal consistency and motion diversity of videos generated by text-to-video models without additional training. UniCtrl ensures semantic consistency across different frames through cross-frame self-attention control, and meanwhile, enhances the motion quality and spatiotemporal consistency through motion injection and spatiotemporal synchronization. Our experimental results demonstrate UniCtrl's efficacy in enhancing various text-to-video models, confirming its effectiveness and universality.
Inversion-Free Image Editing with Natural Language
Dec 07, 2023



Despite recent advances in inversion-based editing, text-guided image manipulation remains challenging for diffusion models. The primary bottlenecks include 1) the time-consuming nature of the inversion process; 2) the struggle to balance consistency with accuracy; 3) the lack of compatibility with efficient consistency sampling methods used in consistency models. To address the above issues, we start by asking ourselves if the inversion process can be eliminated for editing. We show that when the initial sample is known, a special variance schedule reduces the denoising step to the same form as the multi-step consistency sampling. We name this Denoising Diffusion Consistent Model (DDCM), and note that it implies a virtual inversion strategy without explicit inversion in sampling. We further unify the attention control mechanisms in a tuning-free framework for text-guided editing. Combining them, we present inversion-free editing (InfEdit), which allows for consistent and faithful editing for both rigid and non-rigid semantic changes, catering to intricate modifications without compromising on the image's integrity and explicit inversion. Through extensive experiments, InfEdit shows strong performance in various editing tasks and also maintains a seamless workflow (less than 3 seconds on one single A40), demonstrating the potential for real-time applications. Project Page: https://sled-group.github.io/InfEdit/
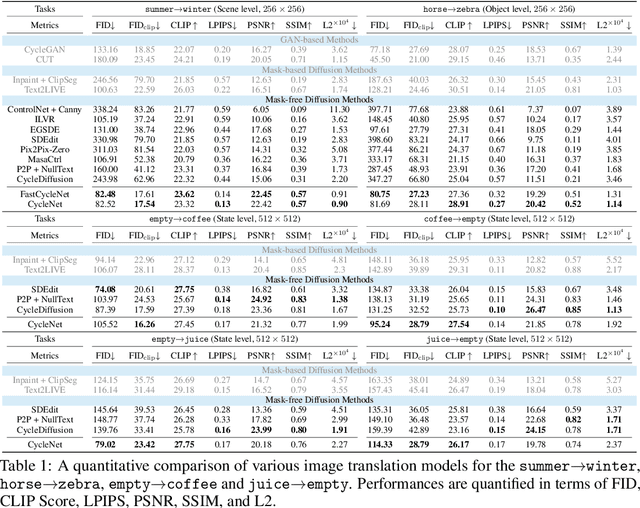
CycleNet: Rethinking Cycle Consistency in Text-Guided Diffusion for Image Manipulation
Oct 19, 2023
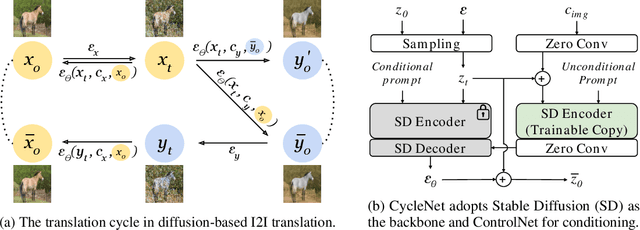

Diffusion models (DMs) have enabled breakthroughs in image synthesis tasks but lack an intuitive interface for consistent image-to-image (I2I) translation. Various methods have been explored to address this issue, including mask-based methods, attention-based methods, and image-conditioning. However, it remains a critical challenge to enable unpaired I2I translation with pre-trained DMs while maintaining satisfying consistency. This paper introduces Cyclenet, a novel but simple method that incorporates cycle consistency into DMs to regularize image manipulation. We validate Cyclenet on unpaired I2I tasks of different granularities. Besides the scene and object level translation, we additionally contribute a multi-domain I2I translation dataset to study the physical state changes of objects. Our empirical studies show that Cyclenet is superior in translation consistency and quality, and can generate high-quality images for out-of-domain distributions with a simple change of the textual prompt. Cyclenet is a practical framework, which is robust even with very limited training data (around 2k) and requires minimal computational resources (1 GPU) to train. Project homepage: https://cyclenetweb.github.io/