 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Rich Emotions in 3D Avatars: A Text-to-3D Avatar Generation Benchmark
Dec 03, 2024



Producing emotionally dynamic 3D facial avatars with text derived from spoken words (Emo3D) has been a pivotal research topic in 3D avatar generation. While progress has been made in general-purpose 3D avatar generation, the exploration of generating emotional 3D avatars remains scarce, primarily due to the complexities of identifying and rendering rich emotions from spoken words. This paper reexamines Emo3D generation and draws inspiration from human processes, breaking down Emo3D into two cascading steps: Text-to-3D Expression Mapping (T3DEM) and 3D Avatar Rendering (3DAR). T3DEM is the most crucial step in determining the quality of Emo3D generation and encompasses three key challenges: Expression Diversity, Emotion-Content Consistency, and Expression Fluidity. To address these challenges, we introduce a novel benchmark to advance research in Emo3D generation. First, we present EmoAva, a large-scale, high-quality dataset for T3DEM, comprising 15,000 text-to-3D expression mappings that characterize the aforementioned three challenges in Emo3D generation. Furthermore, we develop various metrics to effectively evaluate models against these identified challenges. Next, to effectively model the consistency, diversity, and fluidity of human expressions in the T3DEM step, we propose the Continuous Text-to-Expression Generator, which employs an autoregressive Conditional Variational Autoencoder for expression code generation, enhanced with Latent Temporal Attention and Expression-wise Attention mechanisms. Finally, to further enhance the 3DAR step on rendering higher-quality subtle expressions, we present the Globally-informed Gaussian Avatar (GiGA) model. GiGA incorporates a global information mechanism into 3D Gaussian representations, enabling the capture of subtle micro-expressions and seamless transitions between emotional states.
BadPrompt: Backdoor Attacks on Continuous Prompts
Nov 27, 2022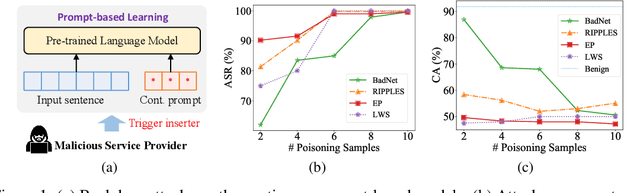
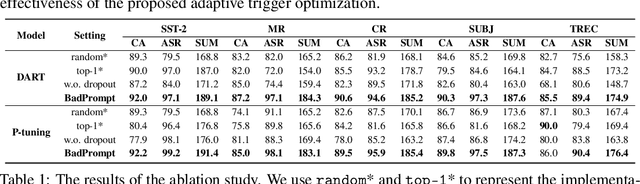
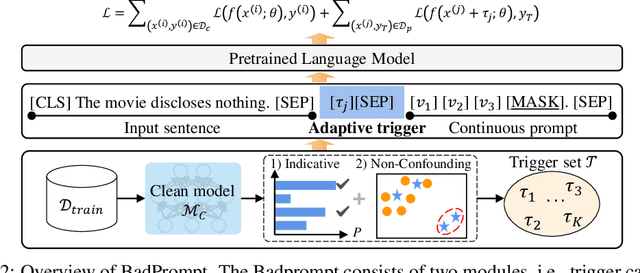
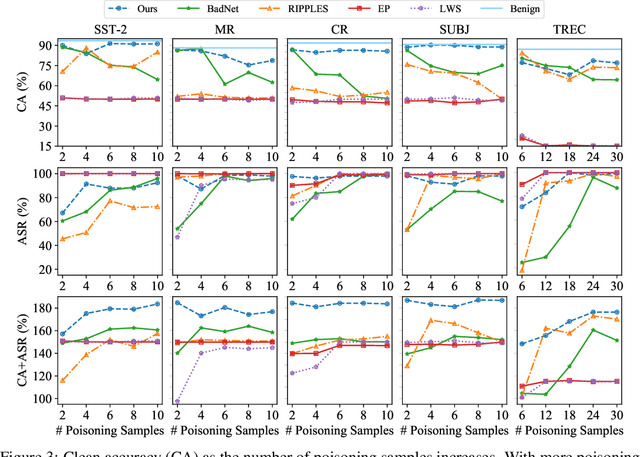
The prompt-based learning paradigm has gained much research attention recently. It has achieved state-of-the-art performance on several NLP tasks, especially in the few-shot scenarios. While steering the downstream tasks, few works have been reported to investigate the security problems of the prompt-based models. In this paper, we conduct the first study on the vulnerability of the continuous prompt learning algorithm to backdoor attacks. We observe that the few-shot scenarios have posed a great challenge to backdoor attacks on the prompt-based models, limiting the usability of existing NLP backdoor methods. To address this challenge, we propose BadPrompt, a lightweight and task-adaptive algorithm, to backdoor attack continuous prompts. Specially, BadPrompt first generates candidate triggers which are indicative for predicting the targeted label and dissimilar to the samples of the non-targeted labels. Then, it automatically selects the most effective and invisible trigger for each sample with an adaptive trigger optimization algorithm. We evaluate the performance of BadPrompt on five datasets and two continuous prompt models. The results exhibit the abilities of BadPrompt to effectively attack continuous prompts while maintaining high performance on the clean test sets, outperforming the baseline models by a large margin. The source code of BadPrompt is publicly available at https://github.com/papersPapers/BadPrompt.