 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Immediate Activation: Temporally Decoupled Backdoor Attacks on Time Series Forecasting
Jan 06, 2026Existing backdoor attacks on multivariate time series (MTS) forecasting enforce strict temporal and dimensional coupling between triggers and target patterns, requiring synchronous activation at fixed positions across variables. However, realistic scenarios often demand delayed and variable-specific activation. We identify this critical unmet need and propose TDBA, a temporally decoupled backdoor attack framework for MTS forecasting. By injecting triggers that encode the expected location of the target pattern, TDBA enables the activation of the target pattern at any positions within the forecasted data, with the activation position flexibly varying across different variable dimensions. TDBA introduces two core modules: (1) a position-guided trigger generation mechanism that leverages smoothed Gaussian priors to generate triggers that are position-related to the predefined target pattern; and (2) a position-aware optimization module that assigns soft weights based on trigger completeness, pattern coverage, and temporal offset, facilitating targeted and stealthy attack optimization. Extensive experiments on real-world datasets show that TDBA consistently outperforms existing baselines in effectiveness while maintaining good stealthiness. Ablation studies confirm the controllability and robustness of its design.
Fusion of Multiscale Features Via Centralized Sparse-attention Network for EEG Decoding
Dec 23, 2025Electroencephalography (EEG) signal decoding is a key technology that translates brain activity into executable commands, laying the foundation for direct brain-machine interfacing and intelligent interaction. To address the inherent spatiotemporal heterogeneity of EEG signals, this paper proposes a multi-branch parallel architecture, where each temporal scale is equipped with an independent spatial feature extraction module. To further enhance multi-branch feature fusion, we propose a Fusion of Multiscale Features via Centralized Sparse-attention Network (EEG-CSANet), a centralized sparse-attention network. It employs a main-auxiliary branch architecture, where the main branch models core spatiotemporal patterns via multiscale self-attention, and the auxiliary branch facilitates efficient local interactions through sparse cross-attention. Experimental results show that EEG-CSANet achieves state-of-the-art (SOTA) performance across five public datasets (BCIC-IV-2A, BCIC-IV-2B, HGD, SEED, and SEED-VIG), with accuracies of 88.54%, 91.09%, 99.43%, 96.03%, and 90.56%, respectively. Such performance demonstrates its strong adaptability and robustness across various EEG decoding tasks. Moreover, extensive ablation studies are conducted to enhance the interpretability of EEG-CSANet. In the future, we hope that EEG-CSANet could serve as a promising baseline model in the field of EEG signal decoding. The source code is publicly available at: https://github.com/Xiangrui-Cai/EEG-CSANet
Contrast then Memorize: Semantic Neighbor Retrieval-Enhanced Inductive Multimodal Knowledge Graph Completion
Jul 03, 2024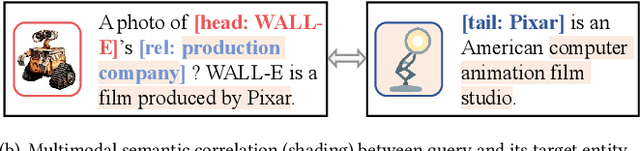
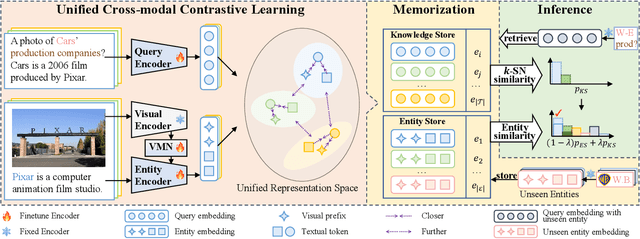
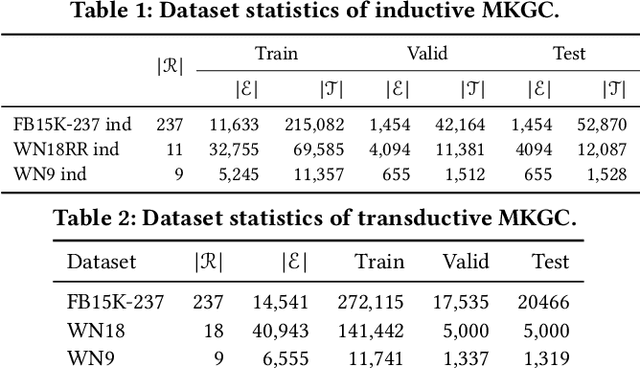
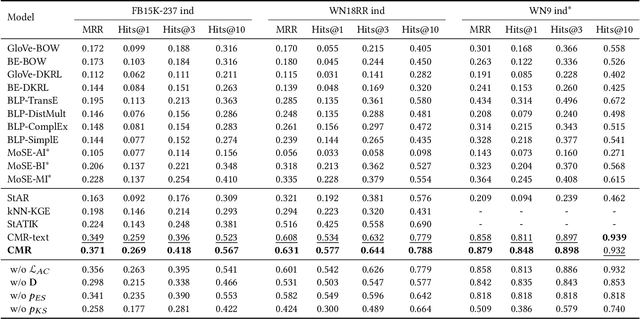
A large number of studies have emerged for Multimodal Knowledge Graph Completion (MKGC) to predict the missing links in MKGs. However, fewer studies have been proposed to study the inductive MKGC (IMKGC) involving emerging entities unseen during training. Existing inductive approaches focus on learning textual entity representations, which neglect rich semantic information in visual modality. Moreover, they focus on aggregating structural neighbors from existing KGs, which of emerging entities are usually limited. However, the semantic neighbors are decoupled from the topology linkage and usually imply the true target entity. In this paper, we propose the IMKGC task and a semantic neighbor retrieval-enhanced IMKGC framework CMR, where the contrast brings the helpful semantic neighbors close, and then the memorize supports semantic neighbor retrieval to enhance inference. Specifically, we first propose a unified cross-modal contrastive learning to simultaneously capture the textual-visual and textual-textual correlations of query-entity pairs in a unified representation space. The contrastive learning increases the similarity of positive query-entity pairs, therefore making the representations of helpful semantic neighbors close. Then, we explicitly memorize the knowledge representations to support the semantic neighbor retrieval. At test time, we retrieve the nearest semantic neighbors and interpolate them to the query-entity similarity distribution to augment the final prediction. Extensive experiments validate the effectiveness of CMR on three inductive MKGC datasets. Codes are available at https://github.com/OreOZhao/CMR.
LAN: Learning Adaptive Neighbors for Real-Time Insider Threat Detection
Mar 17, 2024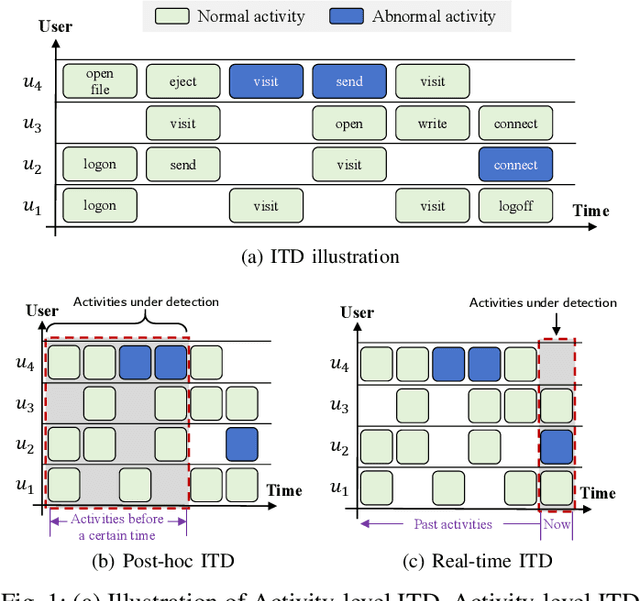
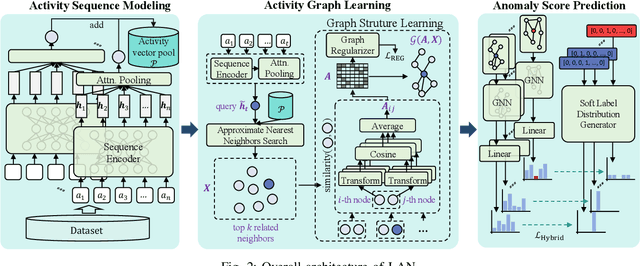
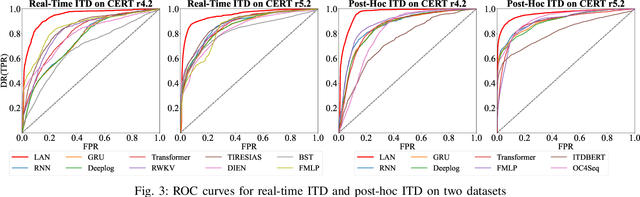
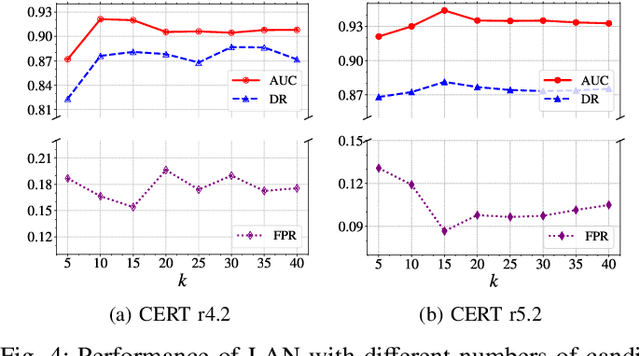
Enterprises and organizations are faced with potential threats from insider employees that may lead to serious consequences. Previous studies on insider threat detection (ITD) mainly focus on detecting abnormal users or abnormal time periods (e.g., a week or a day). However, a user may have hundreds of thousands of activities in the log, and even within a day there may exist thousands of activities for a user, requiring a high investigation budget to verify abnormal users or activities given the detection results. On the other hand, existing works are mainly post-hoc methods rather than real-time detection, which can not report insider threats in time before they cause loss. In this paper, we conduct the first study towards real-time ITD at activity level, and present a fine-grained and efficient framework LAN. Specifically, LAN simultaneously learns the temporal dependencies within an activity sequence and the relationships between activities across sequences with graph structure learning. Moreover, to mitigate the data imbalance problem in ITD, we propose a novel hybrid prediction loss, which integrates self-supervision signals from normal activities and supervision signals from abnormal activities into a unified loss for anomaly detection. We evaluate the performance of LAN on two widely used datasets, i.e., CERT r4.2 and CERT r5.2. Extensive and comparative experiments demonstrate the superiority of LAN, outperforming 9 state-of-the-art baselines by at least 9.92% and 6.35% in AUC for real-time ITD on CERT r4.2 and r5.2, respectively. Moreover, LAN can be also applied to post-hoc ITD, surpassing 8 competitive baselines by at least 7.70% and 4.03% in AUC on two datasets. Finally, the ablation study, parameter analysis, and compatibility analysis evaluate the impact of each module and hyper-parameter in LAN. The source code can be obtained from https://github.com/Li1Neo/LAN.
Learning Time Slot Preferences via Mobility Tree for Next POI Recommendation
Mar 17, 2024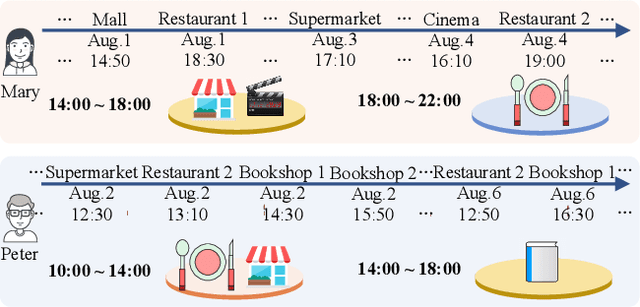
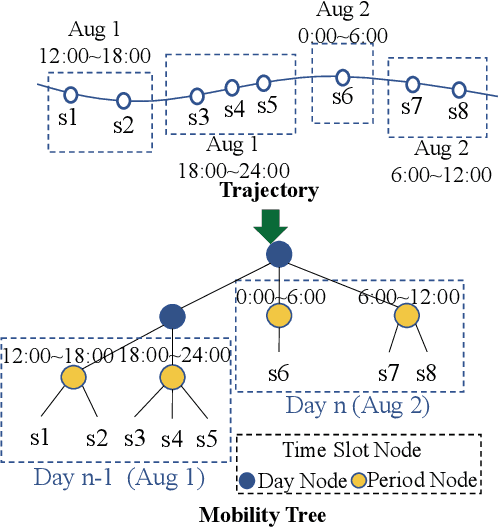
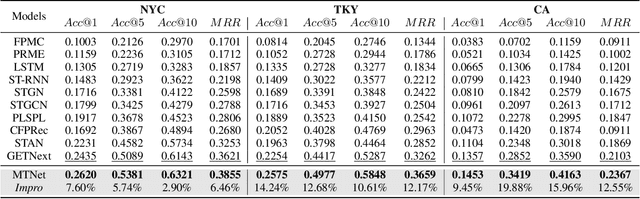
Next Point-of-Interests (POIs) recommendation task aims to provide a dynamic ranking of POIs based on users' current check-in trajectories. The recommendation performance of this task is contingent upon a comprehensive understanding of users' personalized behavioral patterns through Location-based Social Networks (LBSNs) data. While prior studies have adeptly captured sequential patterns and transitional relationships within users' check-in trajectories, a noticeable gap persists in devising a mechanism for discerning specialized behavioral patterns during distinct time slots, such as noon, afternoon, or evening. In this paper, we introduce an innovative data structure termed the ``Mobility Tree'', tailored for hierarchically describing users' check-in records. The Mobility Tree encompasses multi-granularity time slot nodes to learn user preferences across varying temporal periods. Meanwhile, we propose the Mobility Tree Network (MTNet), a multitask framework for personalized preference learning based on Mobility Trees. We develop a four-step node interaction operation to propagate feature information from the leaf nodes to the root node. Additionally, we adopt a multitask training strategy to push the model towards learning a robust representation. The comprehensive experimental results demonstrate the superiority of MTNet over ten state-of-the-art next POI recommendation models across three real-world LBSN datasets, substantiating the efficacy of time slot preference learning facilitated by Mobility Tree.
From Alignment to Entailment: A Unified Textual Entailment Framework for Entity Alignment
May 19, 2023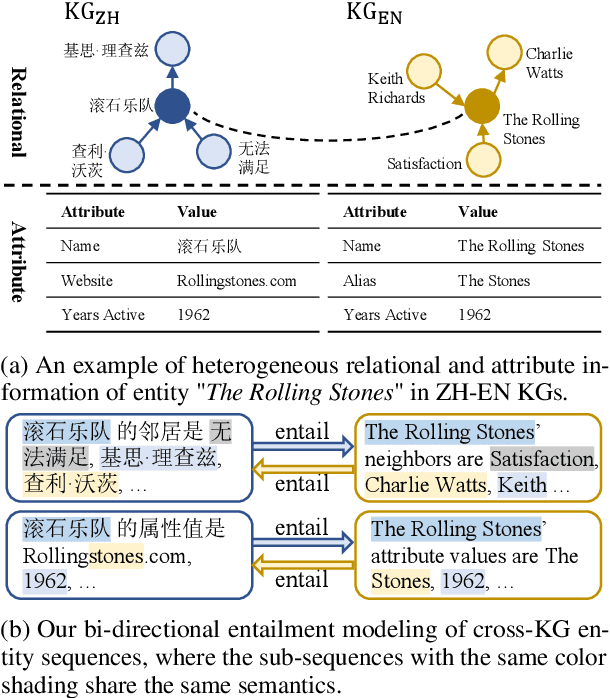
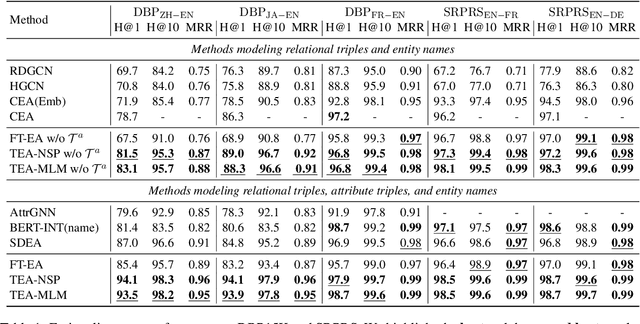
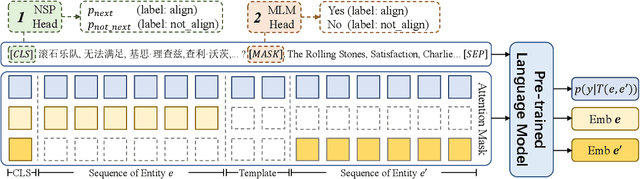
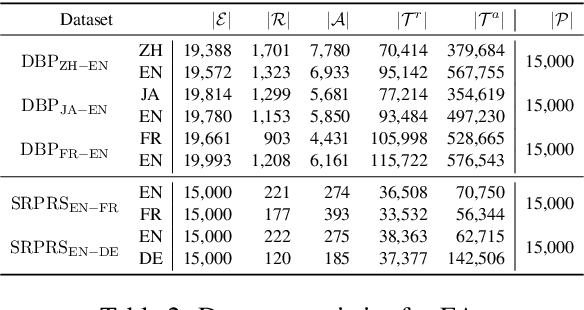
Entity Alignment (EA) aims to find the equivalent entities between two Knowledge Graphs (KGs). Existing methods usually encode the triples of entities as embeddings and learn to align the embeddings, which prevents the direct interaction between the original information of the cross-KG entities. Moreover, they encode the relational triples and attribute triples of an entity in heterogeneous embedding spaces, which prevents them from helping each other. In this paper, we transform both triples into unified textual sequences, and model the EA task as a bi-directional textual entailment task between the sequences of cross-KG entities. Specifically, we feed the sequences of two entities simultaneously into a pre-trained language model (PLM) and propose two kinds of PLM-based entity aligners that model the entailment probability between sequences as the similarity between entities. Our approach captures the unified correlation pattern of two kinds of information between entities, and explicitly models the fine-grained interaction between original entity information. The experiments on five cross-lingual EA datasets show that our approach outperforms the state-of-the-art EA methods and enables the mutual enhancement of the heterogeneous information. Codes are available at https://github.com/OreOZhao/TEA.
BadPrompt: Backdoor Attacks on Continuous Prompts
Nov 27, 2022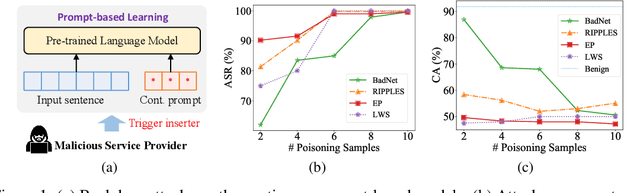
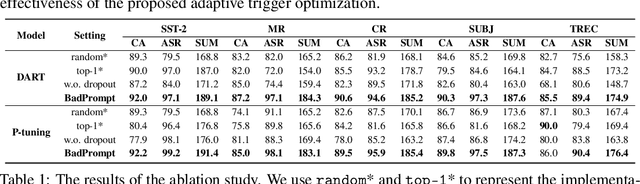
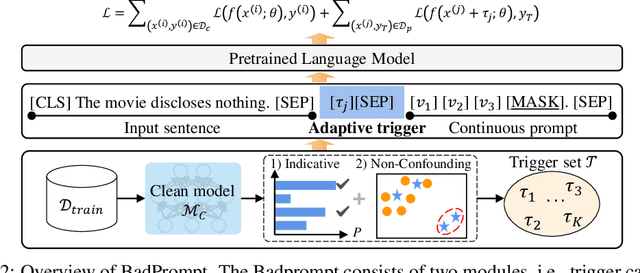
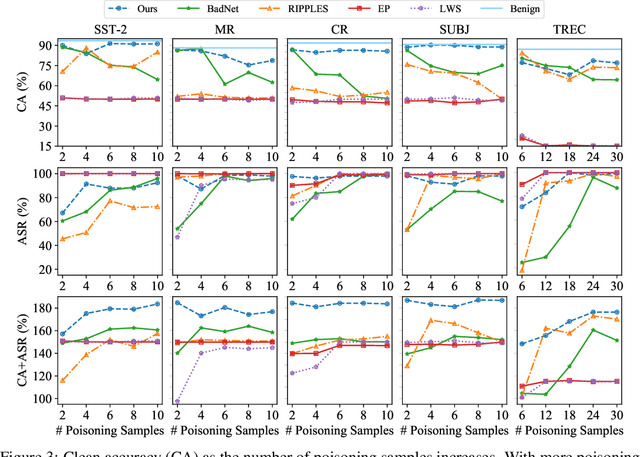
The prompt-based learning paradigm has gained much research attention recently. It has achieved state-of-the-art performance on several NLP tasks, especially in the few-shot scenarios. While steering the downstream tasks, few works have been reported to investigate the security problems of the prompt-based models. In this paper, we conduct the first study on the vulnerability of the continuous prompt learning algorithm to backdoor attacks. We observe that the few-shot scenarios have posed a great challenge to backdoor attacks on the prompt-based models, limiting the usability of existing NLP backdoor methods. To address this challenge, we propose BadPrompt, a lightweight and task-adaptive algorithm, to backdoor attack continuous prompts. Specially, BadPrompt first generates candidate triggers which are indicative for predicting the targeted label and dissimilar to the samples of the non-targeted labels. Then, it automatically selects the most effective and invisible trigger for each sample with an adaptive trigger optimization algorithm. We evaluate the performance of BadPrompt on five datasets and two continuous prompt models. The results exhibit the abilities of BadPrompt to effectively attack continuous prompts while maintaining high performance on the clean test sets, outperforming the baseline models by a large margin. The source code of BadPrompt is publicly available at https://github.com/papersPapers/BadPrompt.
MoSE: Modality Split and Ensemble for Multimodal Knowledge Graph Completion
Oct 17, 2022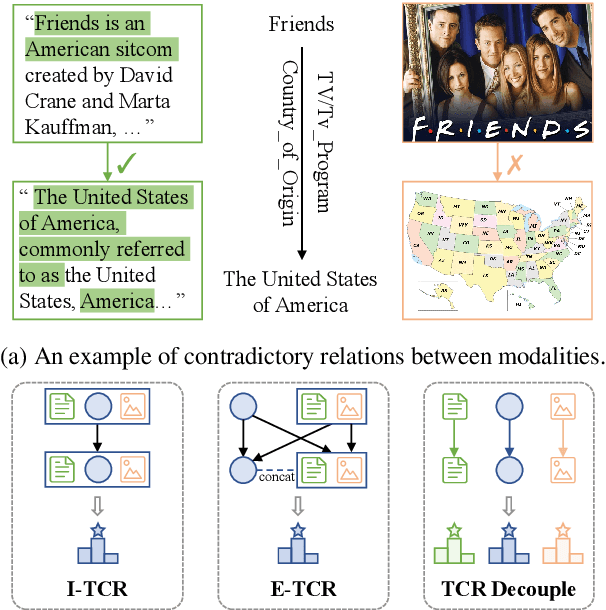
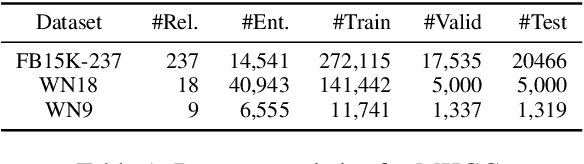
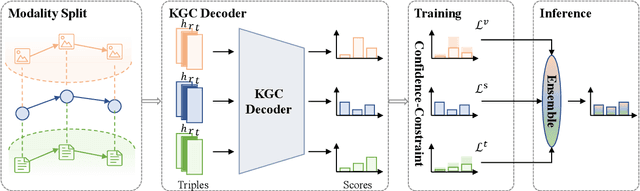
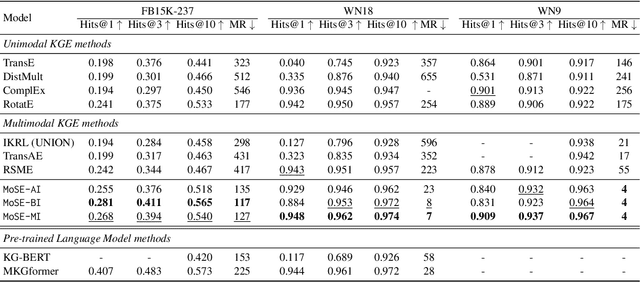
Multimodal knowledge graph completion (MKGC) aims to predict missing entities in MKGs. Previous works usually share relation representation across modalities. This results in mutual interference between modalities during training, since for a pair of entities, the relation from one modality probably contradicts that from another modality. Furthermore, making a unified prediction based on the shared relation representation treats the input in different modalities equally, while their importance to the MKGC task should be different. In this paper, we propose MoSE, a Modality Split representation learning and Ensemble inference framework for MKGC. Specifically, in the training phase, we learn modality-split relation embeddings for each modality instead of a single modality-shared one, which alleviates the modality interference. Based on these embeddings, in the inference phase, we first make modality-split predictions and then exploit various ensemble methods to combine the predictions with different weights, which models the modality importance dynamically. Experimental results on three KG datasets show that MoSE outperforms state-of-the-art MKGC methods. Codes are available at https://github.com/OreOZhao/MoSE4MKGC.
Medical Concept Embedding with Time-Aware Attention
Jun 06, 2018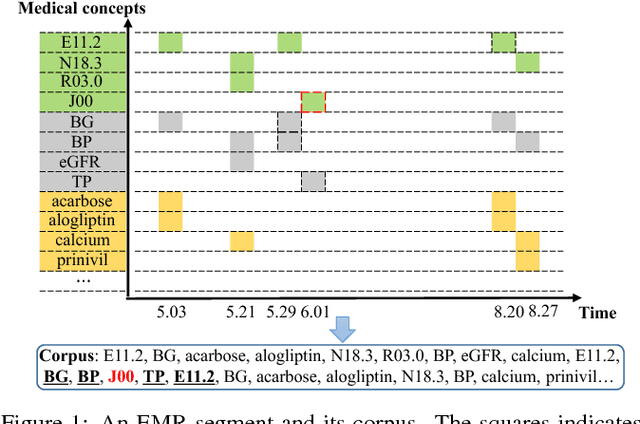

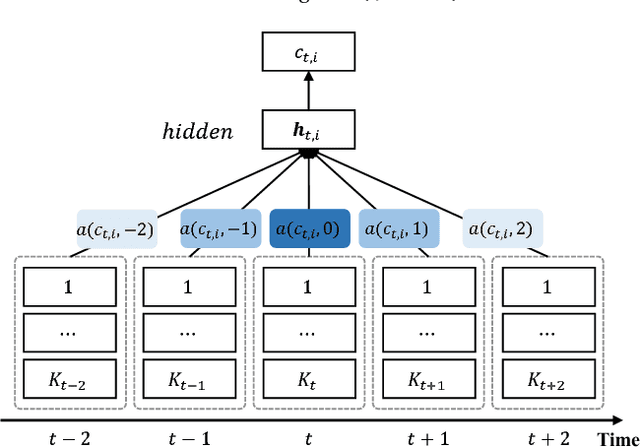
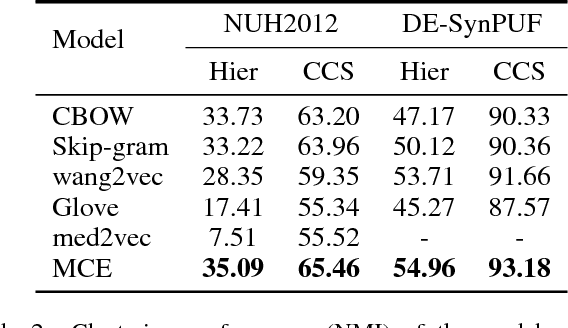
Embeddings of medical concepts such as medication, procedure and diagnosis codes in Electronic Medical Records (EMRs) are central to healthcare analytics. Previous work on medical concept embedding takes medical concepts and EMRs as words and documents respectively. Nevertheless, such models miss out the temporal nature of EMR data. On the one hand, two consecutive medical concepts do not indicate they are temporally close, but the correlations between them can be revealed by the time gap. On the other hand, the temporal scopes of medical concepts often vary greatly (e.g., \textit{common cold} and \textit{diabetes}). In this paper, we propose to incorporate the temporal information to embed medical codes. Based on the Continuous Bag-of-Words model, we employ the attention mechanism to learn a "soft" time-aware context window for each medical concept. Experiments on public and proprietary datasets through clustering and nearest neighbour search tasks demonstrate the effectiveness of our model, showing that it outperforms five state-of-the-art baselines.