 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactorized Learning Assisted with Large Language Model for Gloss-free Sign Language Translation
Mar 19, 2024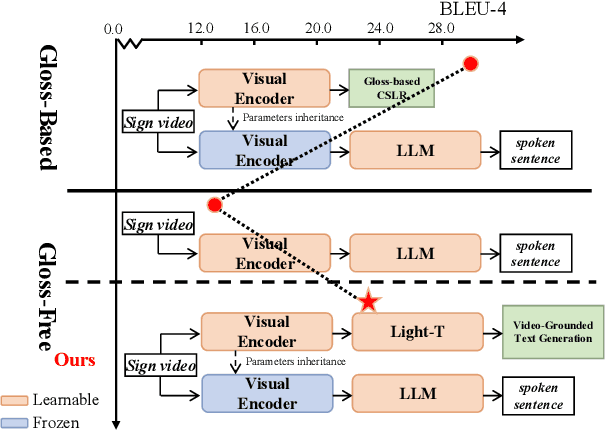
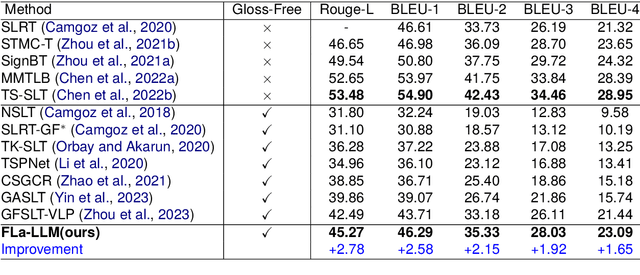
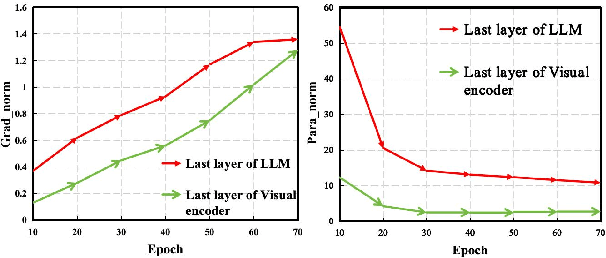
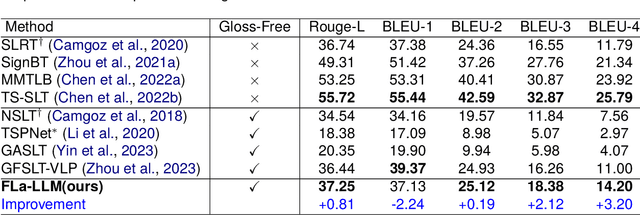
Previous Sign Language Translation (SLT) methods achieve superior performance by relying on gloss annotations. However, labeling high-quality glosses is a labor-intensive task, which limits the further development of SLT. Although some approaches work towards gloss-free SLT through jointly training the visual encoder and translation network, these efforts still suffer from poor performance and inefficient use of the powerful Large Language Model (LLM). Most seriously, we find that directly introducing LLM into SLT will lead to insufficient learning of visual representations as LLM dominates the learning curve. To address these problems, we propose Factorized Learning assisted with Large Language Model (FLa-LLM) for gloss-free SLT. Concretely, we factorize the training process into two stages. In the visual initialing stage, we employ a lightweight translation model after the visual encoder to pre-train the visual encoder. In the LLM fine-tuning stage, we freeze the acquired knowledge in the visual encoder and integrate it with a pre-trained LLM to inspire the LLM's translation potential. This factorized training strategy proves to be highly effective as evidenced by significant improvements achieved across three SLT datasets which are all conducted under the gloss-free setting.
SELM: Speech Enhancement Using Discrete Tokens and Language Models
Dec 15, 2023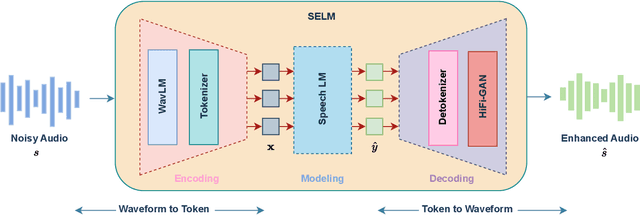
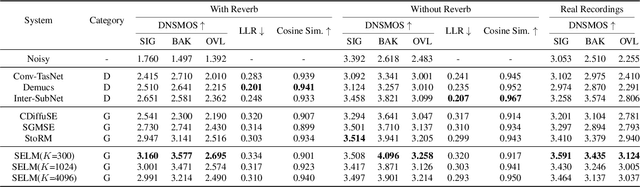
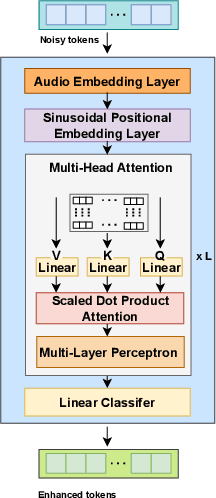
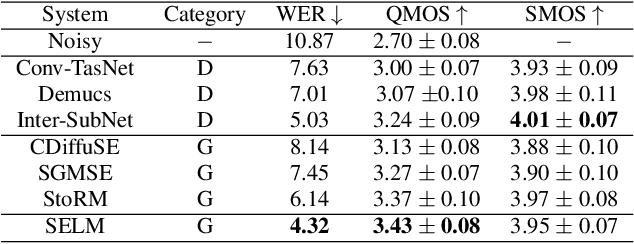
Language models (LMs) have shown superior performances in various speech generation tasks recently, demonstrating their powerful ability for semantic context modeling. Given the intrinsic similarity between speech generation and speech enhancement, harnessing semantic information holds potential advantages for speech enhancement tasks. In light of this, we propose SELM, a novel paradigm for speech enhancement, which integrates discrete tokens and leverages language models. SELM comprises three stages: encoding, modeling, and decoding. We transform continuous waveform signals into discrete tokens using pre-trained self-supervised learning (SSL) models and a k-means tokenizer. Language models then capture comprehensive contextual information within these tokens. Finally, a detokenizer and HiFi-GAN restore them into enhanced speech. Experimental results demonstrate that SELM achieves comparable performance in objective metrics alongside superior results in subjective perception. Our demos are available https://honee-w.github.io/SELM/.
Multi-Speaker Expressive Speech Synthesis via Semi-supervised Contrastive Learning
Oct 26, 2023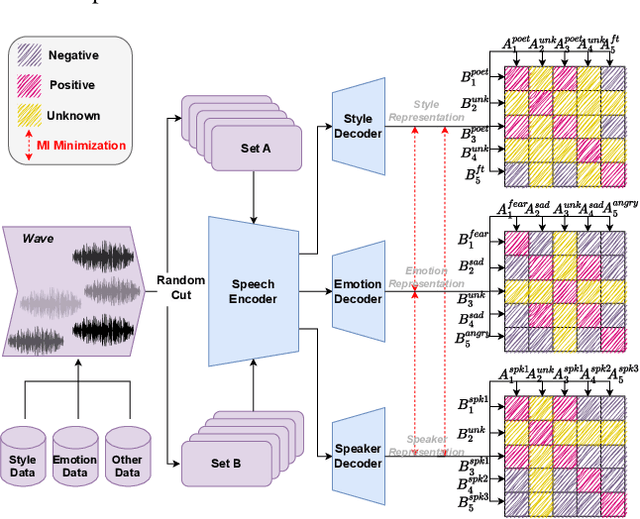

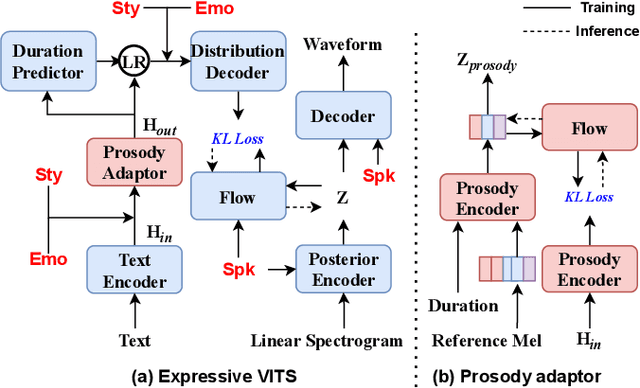
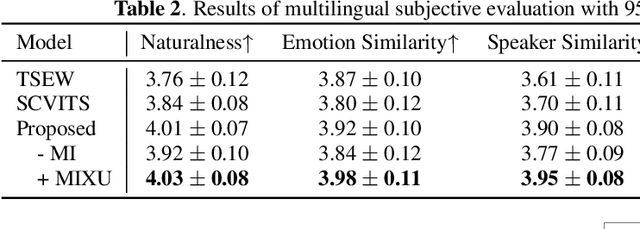
This paper aims to build an expressive TTS system for multi-speakers, synthesizing a target speaker's speech with multiple styles and emotions. To this end, we propose a novel contrastive learning-based TTS approach to transfer style and emotion across speakers. Specifically, we construct positive-negative sample pairs at both utterance and category (such as emotion-happy or style-poet or speaker A) levels and leverage contrastive learning to better extract disentangled style, emotion, and speaker representations from speech. Furthermore, we introduce a semi-supervised training strategy to the proposed approach to effectively leverage multi-domain data, including style-labeled data, emotion-labeled data, and unlabeled data. We integrate the learned representations into an improved VITS model, enabling it to synthesize expressive speech with diverse styles and emotions for a target speaker. Experiments on multi-domain data demonstrate the good design of our model.
Multi-objective Progressive Clustering for Semi-supervised Domain Adaptation in Speaker Verification
Oct 07, 2023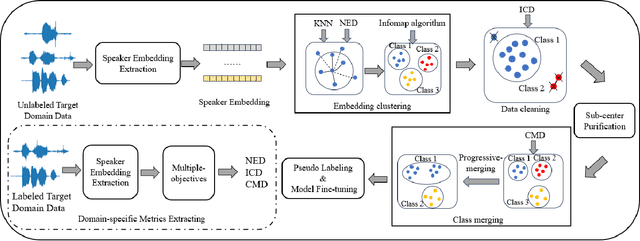
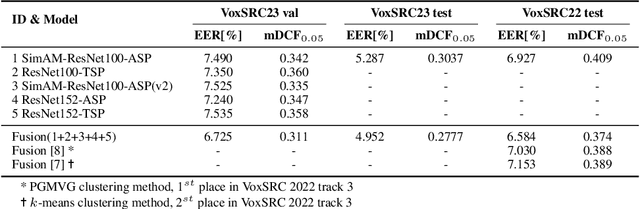
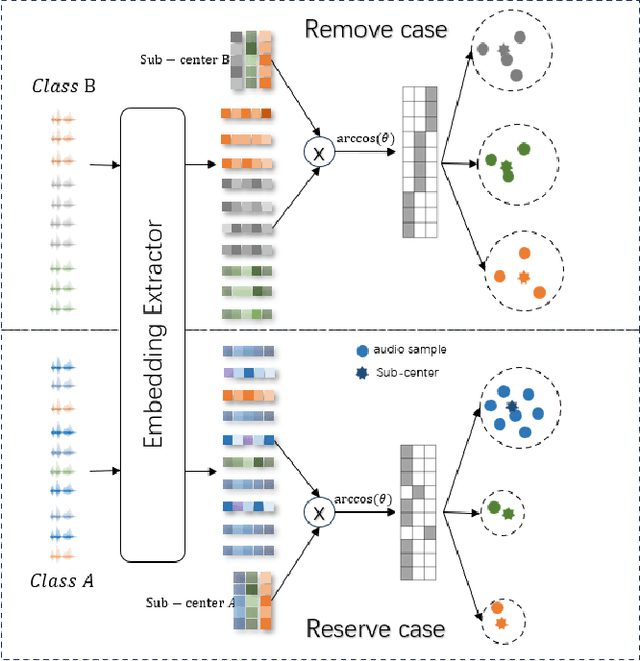
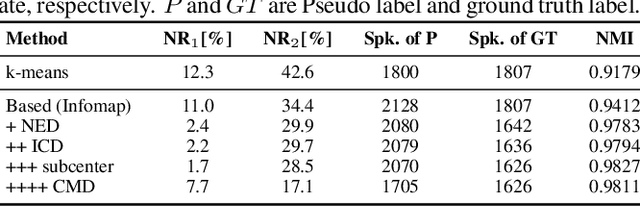
Utilizing the pseudo-labeling algorithm with large-scale unlabeled data becomes crucial for semi-supervised domain adaptation in speaker verification tasks. In this paper, we propose a novel pseudo-labeling method named Multi-objective Progressive Clustering (MoPC), specifically designed for semi-supervised domain adaptation. Firstly, we utilize limited labeled data from the target domain to derive domain-specific descriptors based on multiple distinct objectives, namely within-graph denoising, intra-class denoising and inter-class denoising. Then, the Infomap algorithm is adopted for embedding clustering, and the descriptors are leveraged to further refine the target domain's pseudo-labels. Moreover, to further improve the quality of pseudo labels, we introduce the subcenter-purification and progressive-merging strategy for label denoising. Our proposed MoPC method achieves 4.95% EER and ranked the 1$^{st}$ place on the evaluation set of VoxSRC 2023 track 3. We also conduct additional experiments on the FFSVC dataset and yield promising results.
Haha-Pod: An Attempt for Laughter-based Non-Verbal Speaker Verification
Sep 25, 2023



It is widely acknowledged that discriminative representation for speaker verification can be extracted from verbal speech. However, how much speaker information that non-verbal vocalization carries is still a puzzle. This paper explores speaker verification based on the most ubiquitous form of non-verbal voice, laughter. First, we use a semi-automatic pipeline to collect a new Haha-Pod dataset from open-source podcast media. The dataset contains over 240 speakers' laughter clips with corresponding high-quality verbal speech. Second, we propose a Two-Stage Teacher-Student (2S-TS) framework to minimize the within-speaker embedding distance between verbal and non-verbal (laughter) signals. Considering Haha-Pod as a test set, two trials (S2L-Eval) are designed to verify the speaker's identity through laugh sounds. Experimental results demonstrate that our method can significantly improve the performance of the S2L-Eval test set with only a minor degradation on the VoxCeleb1 test set. The Haha-Pod dataset is open to access on https://drive.google.com/file/d/1J-HBRTsm_yWrcbkXupy-tiWRt5gE2LzG/view?usp=drive_link.
VoxBlink: X-Large Speaker Verification Dataset on Camera
Aug 23, 2023



In this paper, we contribute a novel and extensive dataset for speaker verification, which contains noisy 38k identities/1.45M utterances (VoxBlink) and relatively cleaned 18k identities/1.02M (VoxBlink-Clean) utterances for training. Firstly, we accumulate a 60K+ users' list with their avatars and download their short videos on YouTube. We then established an automatic and scalable pipeline to extract relevant speech and video segments from these videos. To our knowledge, the VoxBlink dataset is one of the largest speaker recognition datasets available. Secondly, we conduct a series of experiments based on different backbones trained on a mix of the VoxCeleb2 and the VoxBlink-Clean. Our findings highlight a notable performance improvement, ranging from 13% to 30%, across different backbone architectures upon integrating our dataset for training. The dataset will be made publicly available shortly.
The DKU-MSXF Speaker Verification System for the VoxCeleb Speaker Recognition Challenge 2023
Aug 17, 2023

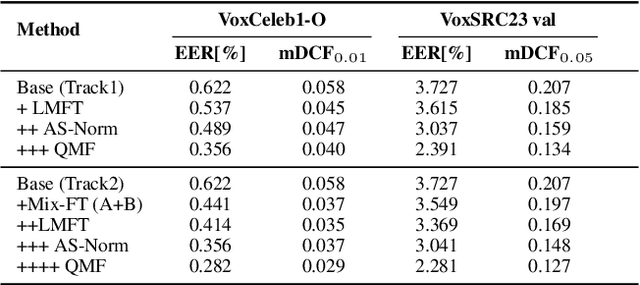
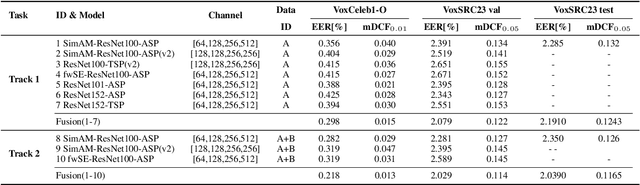
This paper is the system description of the DKU-MSXF System for the track1, track2 and track3 of the VoxCeleb Speaker Recognition Challenge 2023 (VoxSRC-23). For Track 1, we utilize a network structure based on ResNet for training. By constructing a cross-age QMF training set, we achieve a substantial improvement in system performance. For Track 2, we inherite the pre-trained model from Track 1 and conducte mixed training by incorporating the VoxBlink-clean dataset. In comparison to Track 1, the models incorporating VoxBlink-clean data exhibit a performance improvement by more than 10% relatively. For Track3, the semi-supervised domain adaptation task, a novel pseudo-labeling method based on triple thresholds and sub-center purification is adopted to make domain adaptation. The final submission achieves mDCF of 0.1243 in task1, mDCF of 0.1165 in Track 2 and EER of 4.952% in Track 3.
The DKU-MSXF Diarization System for the VoxCeleb Speaker Recognition Challenge 2023
Aug 17, 2023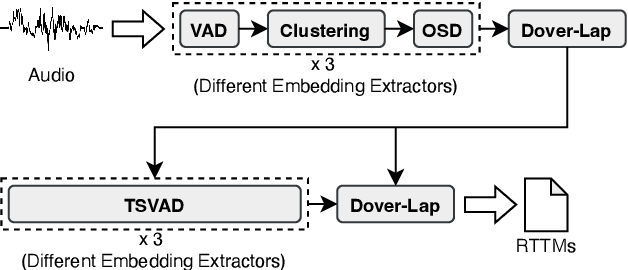
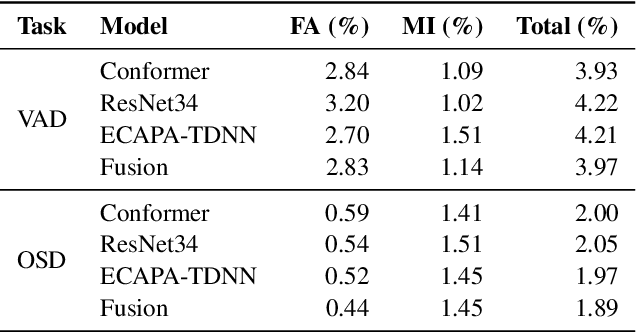

This paper describes the DKU-MSXF submission to track 4 of the VoxCeleb Speaker Recognition Challenge 2023 (VoxSRC-23). Our system pipeline contains voice activity detection, clustering-based diarization, overlapped speech detection, and target-speaker voice activity detection, where each procedure has a fused output from 3 sub-models. Finally, we fuse different clustering-based and TSVAD-based diarization systems using DOVER-Lap and achieve the 4.30% diarization error rate (DER), which ranks first place on track 4 of the challenge leaderboard.
The NPU-MSXF Speech-to-Speech Translation System for IWSLT 2023 Speech-to-Speech Translation Task
Jul 10, 2023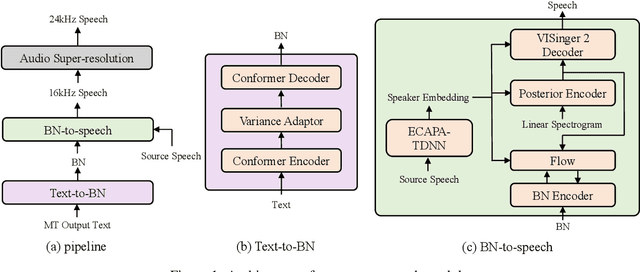
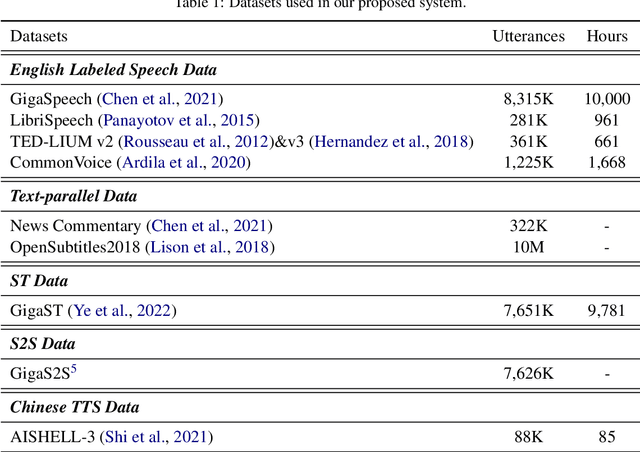


This paper describes the NPU-MSXF system for the IWSLT 2023 speech-to-speech translation (S2ST) task which aims to translate from English speech of multi-source to Chinese speech. The system is built in a cascaded manner consisting of automatic speech recognition (ASR), machine translation (MT), and text-to-speech (TTS). We make tremendous efforts to handle the challenging multi-source input. Specifically, to improve the robustness to multi-source speech input, we adopt various data augmentation strategies and a ROVER-based score fusion on multiple ASR model outputs. To better handle the noisy ASR transcripts, we introduce a three-stage fine-tuning strategy to improve translation accuracy. Finally, we build a TTS model with high naturalness and sound quality, which leverages a two-stage framework, using network bottleneck features as a robust intermediate representation for speaker timbre and linguistic content disentanglement. Based on the two-stage framework, pre-trained speaker embedding is leveraged as a condition to transfer the speaker timbre in the source English speech to the translated Chinese speech. Experimental results show that our system has high translation accuracy, speech naturalness, sound quality, and speaker similarity. Moreover, it shows good robustness to multi-source data.
TreeMAN: Tree-enhanced Multimodal Attention Network for ICD Coding
May 29, 2023



ICD coding is designed to assign the disease codes to electronic health records (EHRs) upon discharge, which is crucial for billing and clinical statistics. In an attempt to improve the effectiveness and efficiency of manual coding, many methods have been proposed to automatically predict ICD codes from clinical notes. However, most previous works ignore the decisive information contained in structured medical data in EHRs, which is hard to be captured from the noisy clinical notes. In this paper, we propose a Tree-enhanced Multimodal Attention Network (TreeMAN) to fuse tabular features and textual features into multimodal representations by enhancing the text representations with tree-based features via the attention mechanism. Tree-based features are constructed according to decision trees learned from structured multimodal medical data, which capture the decisive information about ICD coding. We can apply the same multi-label classifier from previous text models to the multimodal representations to predict ICD codes. Experiments on two MIMIC datasets show that our method outperforms prior state-of-the-art ICD coding approaches. The code is available at https://github.com/liu-zichen/TreeMAN.