 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Speaker Expressive Speech Synthesis via Semi-supervised Contrastive Learning
Paper and Code
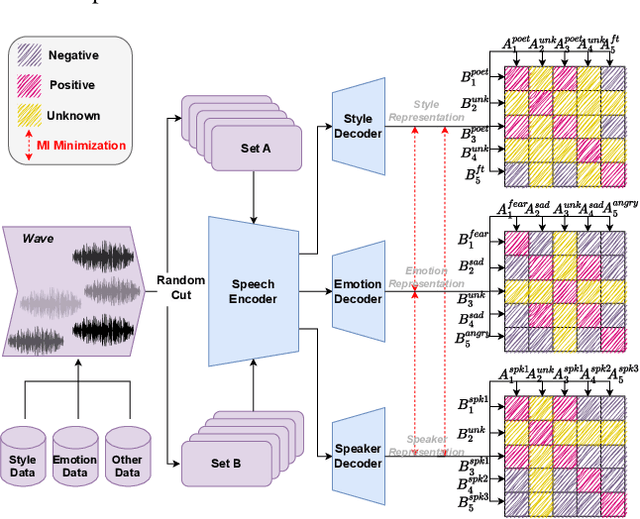

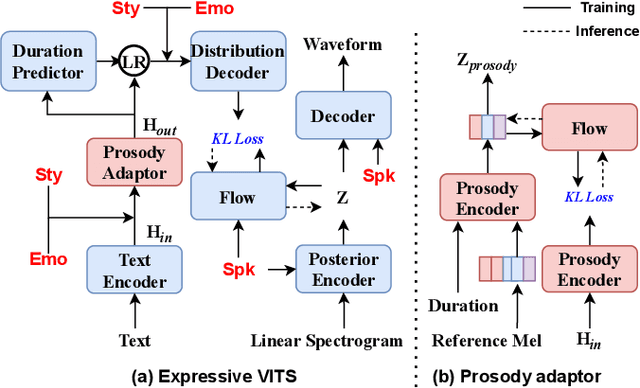
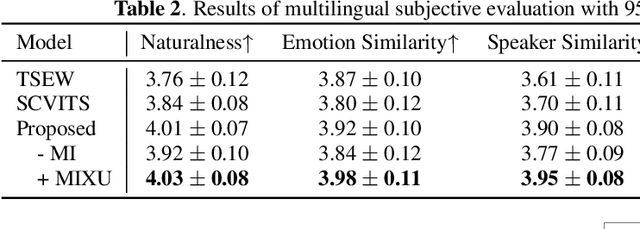
This paper aims to build an expressive TTS system for multi-speakers, synthesizing a target speaker's speech with multiple styles and emotions. To this end, we propose a novel contrastive learning-based TTS approach to transfer style and emotion across speakers. Specifically, we construct positive-negative sample pairs at both utterance and category (such as emotion-happy or style-poet or speaker A) levels and leverage contrastive learning to better extract disentangled style, emotion, and speaker representations from speech. Furthermore, we introduce a semi-supervised training strategy to the proposed approach to effectively leverage multi-domain data, including style-labeled data, emotion-labeled data, and unlabeled data. We integrate the learned representations into an improved VITS model, enabling it to synthesize expressive speech with diverse styles and emotions for a target speaker. Experiments on multi-domain data demonstrate the good design of our model.