 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSELM: Speech Enhancement Using Discrete Tokens and Language Models
Paper and Code
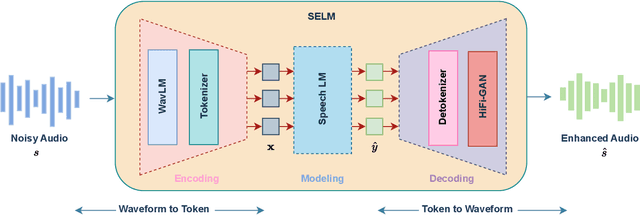
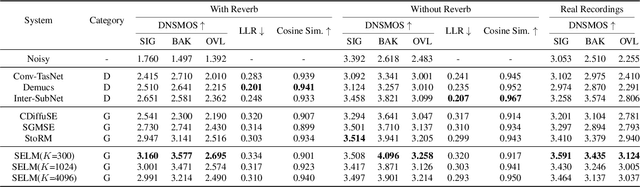
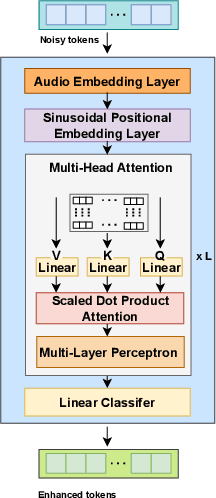
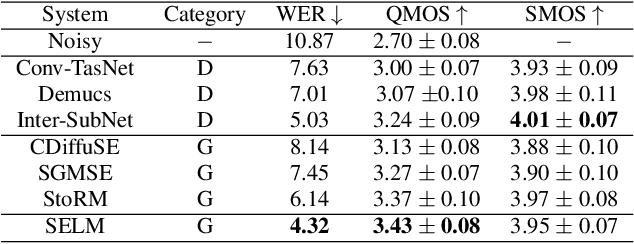
Language models (LMs) have shown superior performances in various speech generation tasks recently, demonstrating their powerful ability for semantic context modeling. Given the intrinsic similarity between speech generation and speech enhancement, harnessing semantic information holds potential advantages for speech enhancement tasks. In light of this, we propose SELM, a novel paradigm for speech enhancement, which integrates discrete tokens and leverages language models. SELM comprises three stages: encoding, modeling, and decoding. We transform continuous waveform signals into discrete tokens using pre-trained self-supervised learning (SSL) models and a k-means tokenizer. Language models then capture comprehensive contextual information within these tokens. Finally, a detokenizer and HiFi-GAN restore them into enhanced speech. Experimental results demonstrate that SELM achieves comparable performance in objective metrics alongside superior results in subjective perception. Our demos are available https://honee-w.github.io/SELM/.