 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRVLF: A Reinforcing Vision-Language Framework for Gloss-Free Sign Language Translation
Dec 08, 2025Gloss-free sign language translation (SLT) is hindered by two key challenges: **inadequate sign representation** that fails to capture nuanced visual cues, and **sentence-level semantic misalignment** in current LLM-based methods, which limits translation quality. To address these issues, we propose a three-stage **r**einforcing **v**ision-**l**anguage **f**ramework (**RVLF**). We build a large vision-language model (LVLM) specifically designed for sign language, and then combine it with reinforcement learning (RL) to adaptively enhance translation performance. First, for a sufficient representation of sign language, RVLF introduces an effective semantic representation learning mechanism that fuses skeleton-based motion cues with semantically rich visual features extracted via DINOv2, followed by instruction tuning to obtain a strong SLT-SFT baseline. Then, to improve sentence-level semantic misalignment, we introduce a GRPO-based optimization strategy that fine-tunes the SLT-SFT model with a reward function combining translation fidelity (BLEU) and sentence completeness (ROUGE), yielding the optimized model termed SLT-GRPO. Our conceptually simple framework yields substantial gains under the gloss-free SLT setting without pre-training on any external large-scale sign language datasets, improving BLEU-4 scores by +5.1, +1.11, +1.4, and +1.61 on the CSL-Daily, PHOENIX-2014T, How2Sign, and OpenASL datasets, respectively. To the best of our knowledge, this is the first work to incorporate GRPO into SLT. Extensive experiments and ablation studies validate the effectiveness of GRPO-based optimization in enhancing both translation quality and semantic consistency.
C${^2}$RL: Content and Context Representation Learning for Gloss-free Sign Language Translation and Retrieval
Aug 19, 2024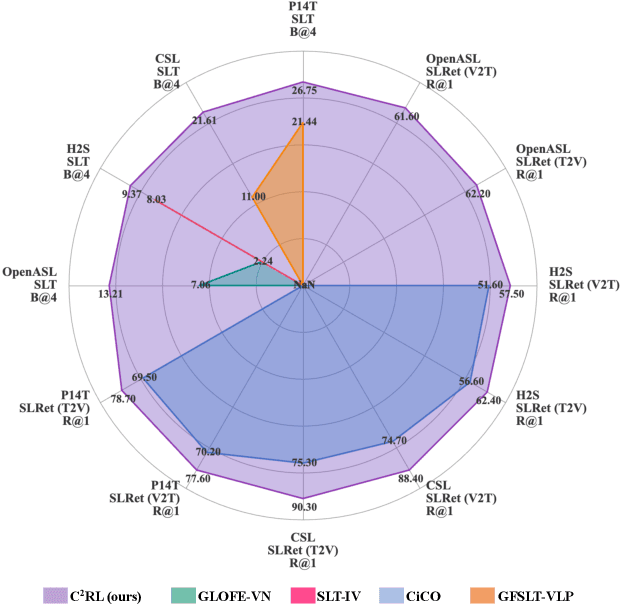
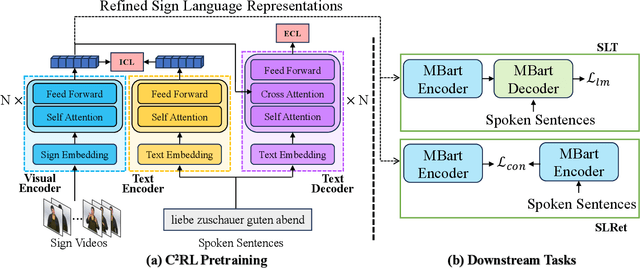
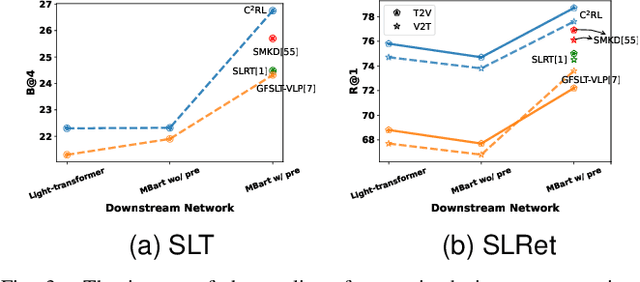
Sign Language Representation Learning (SLRL) is crucial for a range of sign language-related downstream tasks such as Sign Language Translation (SLT) and Sign Language Retrieval (SLRet). Recently, many gloss-based and gloss-free SLRL methods have been proposed, showing promising performance. Among them, the gloss-free approach shows promise for strong scalability without relying on gloss annotations. However, it currently faces suboptimal solutions due to challenges in encoding the intricate, context-sensitive characteristics of sign language videos, mainly struggling to discern essential sign features using a non-monotonic video-text alignment strategy. Therefore, we introduce an innovative pretraining paradigm for gloss-free SLRL, called C${^2}$RL, in this paper. Specifically, rather than merely incorporating a non-monotonic semantic alignment of video and text to learn language-oriented sign features, we emphasize two pivotal aspects of SLRL: Implicit Content Learning (ICL) and Explicit Context Learning (ECL). ICL delves into the content of communication, capturing the nuances, emphasis, timing, and rhythm of the signs. In contrast, ECL focuses on understanding the contextual meaning of signs and converting them into equivalent sentences. Despite its simplicity, extensive experiments confirm that the joint optimization of ICL and ECL results in robust sign language representation and significant performance gains in gloss-free SLT and SLRet tasks. Notably, C${^2}$RL improves the BLEU-4 score by +5.3 on P14T, +10.6 on CSL-daily, +6.2 on OpenASL, and +1.3 on How2Sign. It also boosts the R@1 score by +8.3 on P14T, +14.4 on CSL-daily, and +5.9 on How2Sign. Additionally, we set a new baseline for the OpenASL dataset in the SLRet task.
Factorized Learning Assisted with Large Language Model for Gloss-free Sign Language Translation
Mar 19, 2024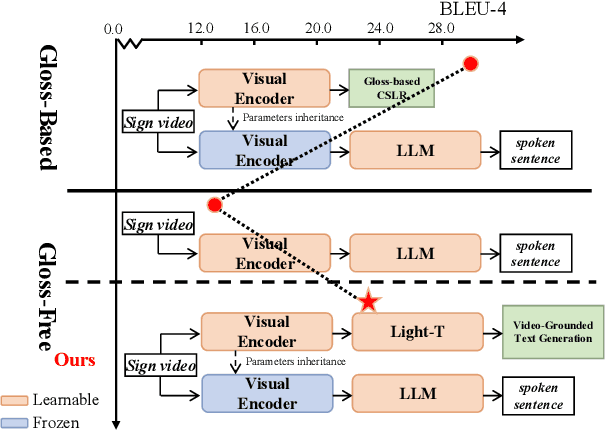
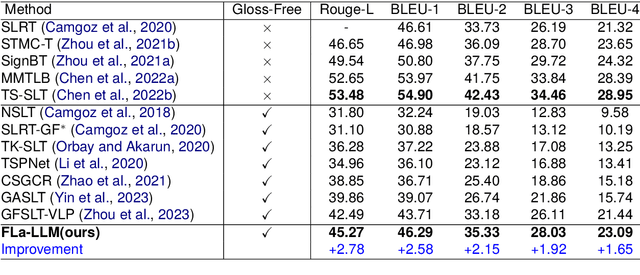
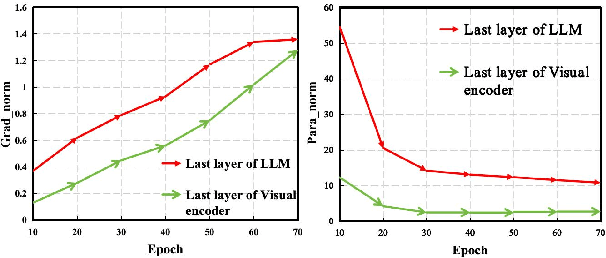
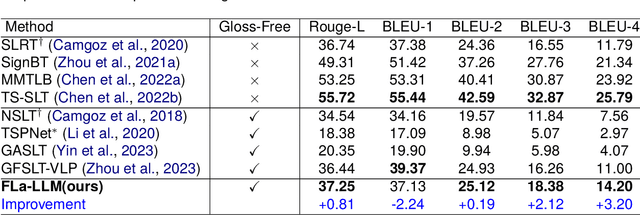
Previous Sign Language Translation (SLT) methods achieve superior performance by relying on gloss annotations. However, labeling high-quality glosses is a labor-intensive task, which limits the further development of SLT. Although some approaches work towards gloss-free SLT through jointly training the visual encoder and translation network, these efforts still suffer from poor performance and inefficient use of the powerful Large Language Model (LLM). Most seriously, we find that directly introducing LLM into SLT will lead to insufficient learning of visual representations as LLM dominates the learning curve. To address these problems, we propose Factorized Learning assisted with Large Language Model (FLa-LLM) for gloss-free SLT. Concretely, we factorize the training process into two stages. In the visual initialing stage, we employ a lightweight translation model after the visual encoder to pre-train the visual encoder. In the LLM fine-tuning stage, we freeze the acquired knowledge in the visual encoder and integrate it with a pre-trained LLM to inspire the LLM's translation potential. This factorized training strategy proves to be highly effective as evidenced by significant improvements achieved across three SLT datasets which are all conducted under the gloss-free setting.
PMMTalk: Speech-Driven 3D Facial Animation from Complementary Pseudo Multi-modal Features
Dec 05, 2023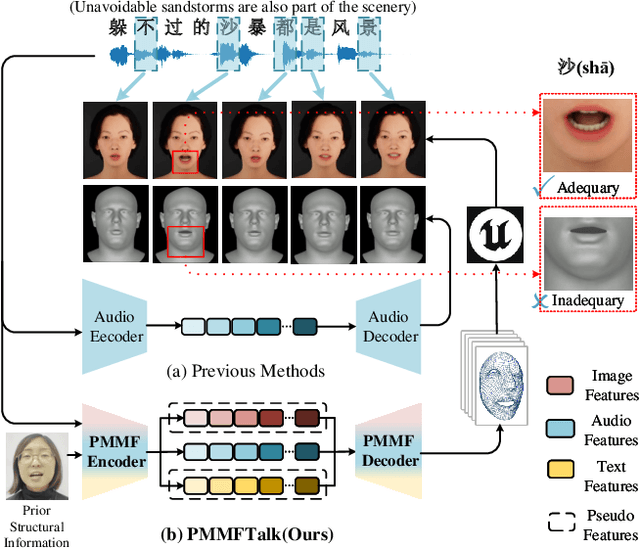
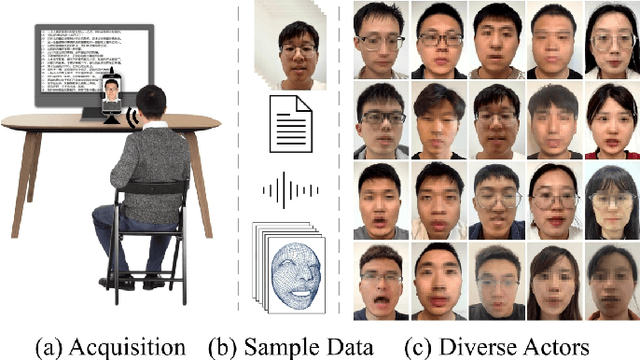
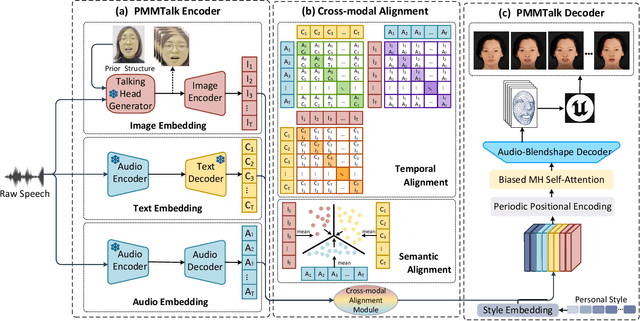
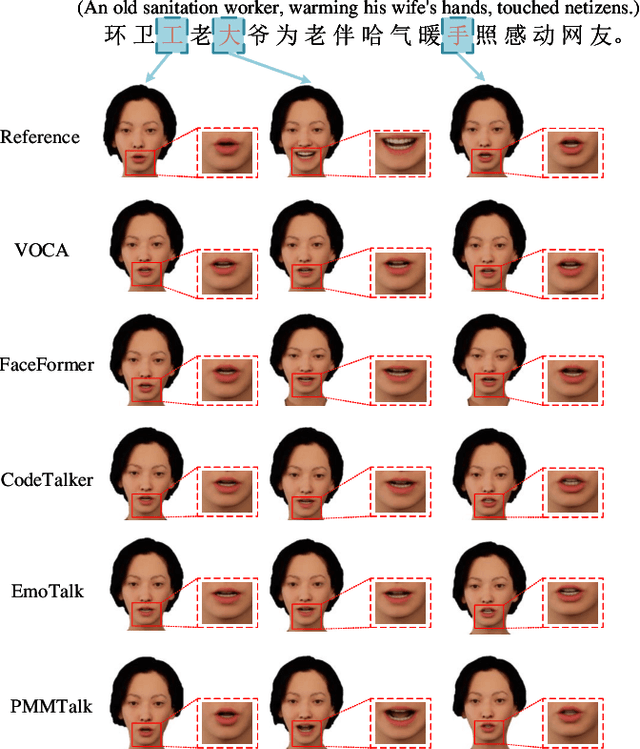
Speech-driven 3D facial animation has improved a lot recently while most related works only utilize acoustic modality and neglect the influence of visual and textual cues, leading to unsatisfactory results in terms of precision and coherence. We argue that visual and textual cues are not trivial information. Therefore, we present a novel framework, namely PMMTalk, using complementary Pseudo Multi-Modal features for improving the accuracy of facial animation. The framework entails three modules: PMMTalk encoder, cross-modal alignment module, and PMMTalk decoder. Specifically, the PMMTalk encoder employs the off-the-shelf talking head generation architecture and speech recognition technology to extract visual and textual information from speech, respectively. Subsequently, the cross-modal alignment module aligns the audio-image-text features at temporal and semantic levels. Then PMMTalk decoder is employed to predict lip-syncing facial blendshape coefficients. Contrary to prior methods, PMMTalk only requires an additional random reference face image but yields more accurate results. Additionally, it is artist-friendly as it seamlessly integrates into standard animation production workflows by introducing facial blendshape coefficients. Finally, given the scarcity of 3D talking face datasets, we introduce a large-scale 3D Chinese Audio-Visual Facial Animation (3D-CAVFA) dataset. Extensive experiments and user studies show that our approach outperforms the state of the art. We recommend watching the supplementary video.
Multi-stage Factorized Spatio-Temporal Representation for RGB-D Action and Gesture Recognition
Sep 11, 2023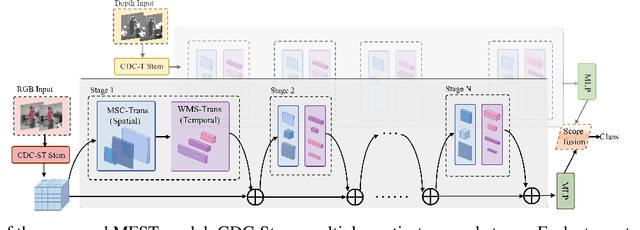
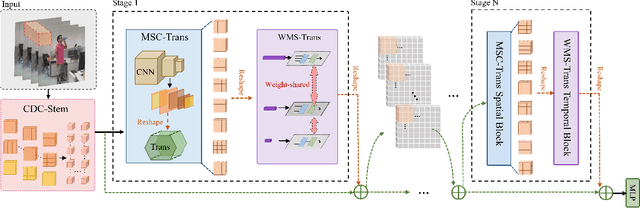
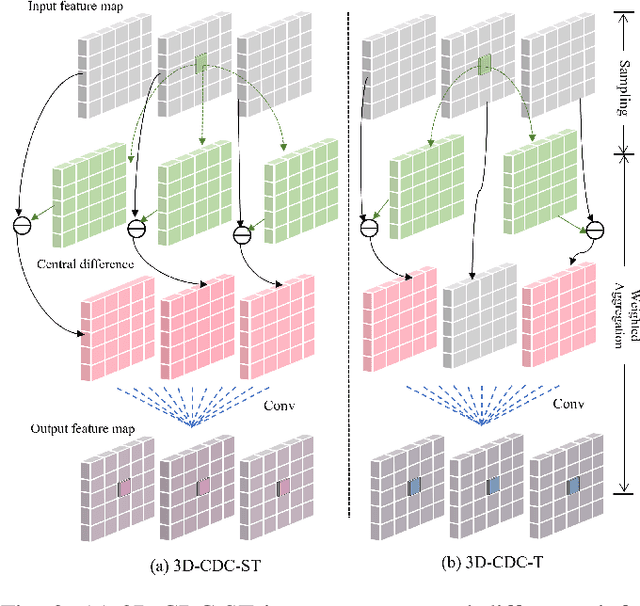
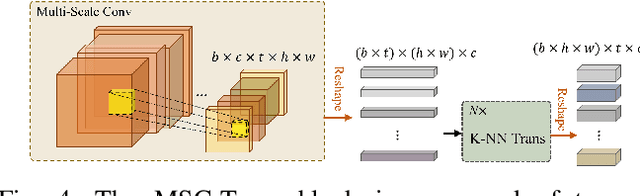
RGB-D action and gesture recognition remain an interesting topic in human-centered scene understanding, primarily due to the multiple granularities and large variation in human motion. Although many RGB-D based action and gesture recognition approaches have demonstrated remarkable results by utilizing highly integrated spatio-temporal representations across multiple modalities (i.e., RGB and depth data), they still encounter several challenges. Firstly, vanilla 3D convolution makes it hard to capture fine-grained motion differences between local clips under different modalities. Secondly, the intricate nature of highly integrated spatio-temporal modeling can lead to optimization difficulties. Thirdly, duplicate and unnecessary information can add complexity and complicate entangled spatio-temporal modeling. To address the above issues, we propose an innovative heuristic architecture called Multi-stage Factorized Spatio-Temporal (MFST) for RGB-D action and gesture recognition. The proposed MFST model comprises a 3D Central Difference Convolution Stem (CDC-Stem) module and multiple factorized spatio-temporal stages. The CDC-Stem enriches fine-grained temporal perception, and the multiple hierarchical spatio-temporal stages construct dimension-independent higher-order semantic primitives. Specifically, the CDC-Stem module captures bottom-level spatio-temporal features and passes them successively to the following spatio-temporal factored stages to capture the hierarchical spatial and temporal features through the Multi- Scale Convolution and Transformer (MSC-Trans) hybrid block and Weight-shared Multi-Scale Transformer (WMS-Trans) block. The seamless integration of these innovative designs results in a robust spatio-temporal representation that outperforms state-of-the-art approaches on RGB-D action and gesture recognition datasets.
Gloss-free Sign Language Translation: Improving from Visual-Language Pretraining
Jul 27, 2023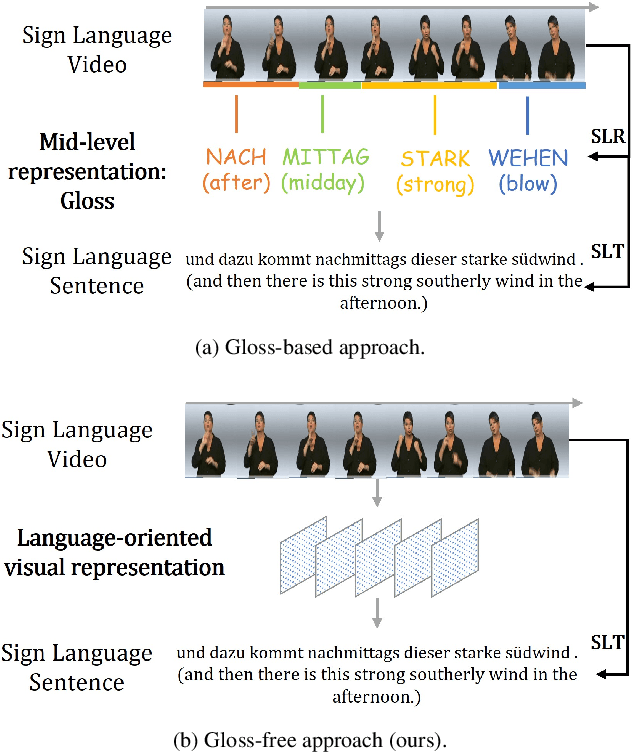
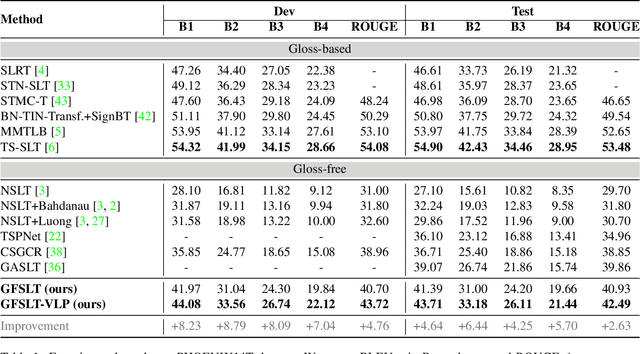
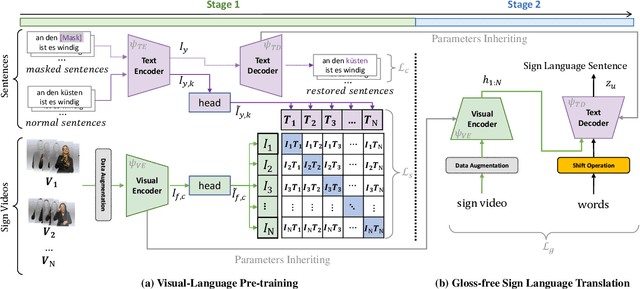

Sign Language Translation (SLT) is a challenging task due to its cross-domain nature, involving the translation of visual-gestural language to text. Many previous methods employ an intermediate representation, i.e., gloss sequences, to facilitate SLT, thus transforming it into a two-stage task of sign language recognition (SLR) followed by sign language translation (SLT). However, the scarcity of gloss-annotated sign language data, combined with the information bottleneck in the mid-level gloss representation, has hindered the further development of the SLT task. To address this challenge, we propose a novel Gloss-Free SLT based on Visual-Language Pretraining (GFSLT-VLP), which improves SLT by inheriting language-oriented prior knowledge from pre-trained models, without any gloss annotation assistance. Our approach involves two stages: (i) integrating Contrastive Language-Image Pre-training (CLIP) with masked self-supervised learning to create pre-tasks that bridge the semantic gap between visual and textual representations and restore masked sentences, and (ii) constructing an end-to-end architecture with an encoder-decoder-like structure that inherits the parameters of the pre-trained Visual Encoder and Text Decoder from the first stage. The seamless combination of these novel designs forms a robust sign language representation and significantly improves gloss-free sign language translation. In particular, we have achieved unprecedented improvements in terms of BLEU-4 score on the PHOENIX14T dataset (>+5) and the CSL-Daily dataset (>+3) compared to state-of-the-art gloss-free SLT methods. Furthermore, our approach also achieves competitive results on the PHOENIX14T dataset when compared with most of the gloss-based methods. Our code is available at https://github.com/zhoubenjia/GFSLT-VLP.
A Unified Multimodal De- and Re-coupling Framework for RGB-D Motion Recognition
Nov 16, 2022Motion recognition is a promising direction in computer vision, but the training of video classification models is much harder than images due to insufficient data and considerable parameters. To get around this, some works strive to explore multimodal cues from RGB-D data. Although improving motion recognition to some extent, these methods still face sub-optimal situations in the following aspects: (i) Data augmentation, i.e., the scale of the RGB-D datasets is still limited, and few efforts have been made to explore novel data augmentation strategies for videos; (ii) Optimization mechanism, i.e., the tightly space-time-entangled network structure brings more challenges to spatiotemporal information modeling; And (iii) cross-modal knowledge fusion, i.e., the high similarity between multimodal representations caused to insufficient late fusion. To alleviate these drawbacks, we propose to improve RGB-D-based motion recognition both from data and algorithm perspectives in this paper. In more detail, firstly, we introduce a novel video data augmentation method dubbed ShuffleMix, which acts as a supplement to MixUp, to provide additional temporal regularization for motion recognition. Secondly, a Unified Multimodal De-coupling and multi-stage Re-coupling framework, termed UMDR, is proposed for video representation learning. Finally, a novel cross-modal Complement Feature Catcher (CFCer) is explored to mine potential commonalities features in multimodal information as the auxiliary fusion stream, to improve the late fusion results. The seamless combination of these novel designs forms a robust spatiotemporal representation and achieves better performance than state-of-the-art methods on four public motion datasets. Specifically, UMDR achieves unprecedented improvements of +4.5% on the Chalearn IsoGD dataset.Our code is available at https://github.com/zhoubenjia/MotionRGBD-PAMI.
Effective Vision Transformer Training: A Data-Centric Perspective
Sep 29, 2022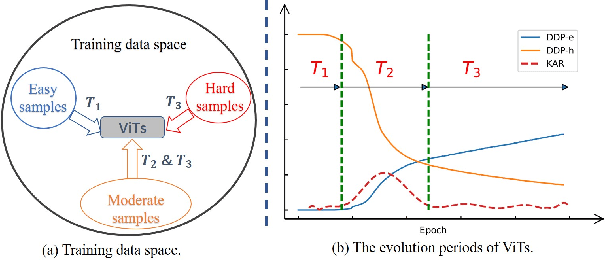
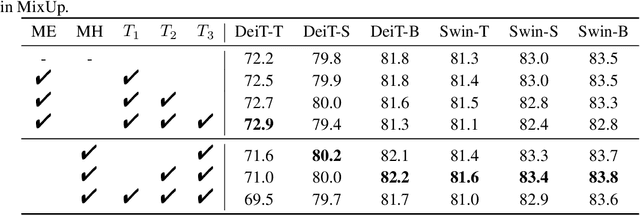
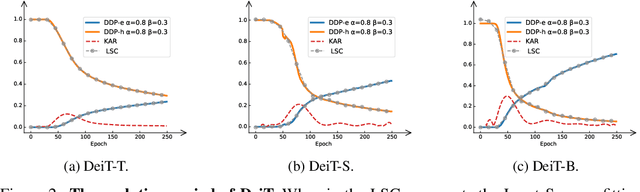
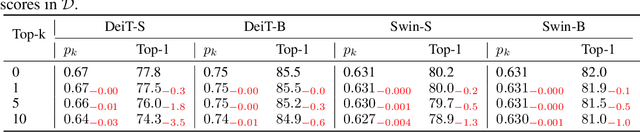
Vision Transformers (ViTs) have shown promising performance compared with Convolutional Neural Networks (CNNs), but the training of ViTs is much harder than CNNs. In this paper, we define several metrics, including Dynamic Data Proportion (DDP) and Knowledge Assimilation Rate (KAR), to investigate the training process, and divide it into three periods accordingly: formation, growth and exploration. In particular, at the last stage of training, we observe that only a tiny portion of training examples is used to optimize the model. Given the data-hungry nature of ViTs, we thus ask a simple but important question: is it possible to provide abundant ``effective'' training examples at EVERY stage of training? To address this issue, we need to address two critical questions, \ie, how to measure the ``effectiveness'' of individual training examples, and how to systematically generate enough number of ``effective'' examples when they are running out. To answer the first question, we find that the ``difficulty'' of training samples can be adopted as an indicator to measure the ``effectiveness'' of training samples. To cope with the second question, we propose to dynamically adjust the ``difficulty'' distribution of the training data in these evolution stages. To achieve these two purposes, we propose a novel data-centric ViT training framework to dynamically measure the ``difficulty'' of training samples and generate ``effective'' samples for models at different training stages. Furthermore, to further enlarge the number of ``effective'' samples and alleviate the overfitting problem in the late training stage of ViTs, we propose a patch-level erasing strategy dubbed PatchErasing. Extensive experiments demonstrate the effectiveness of the proposed data-centric ViT training framework and techniques.
Decoupling and Recoupling Spatiotemporal Representation for RGB-D-based Motion Recognition
Dec 16, 2021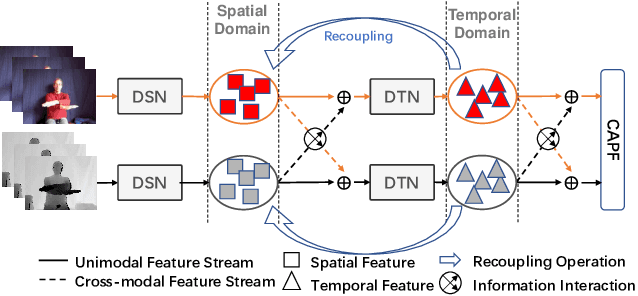
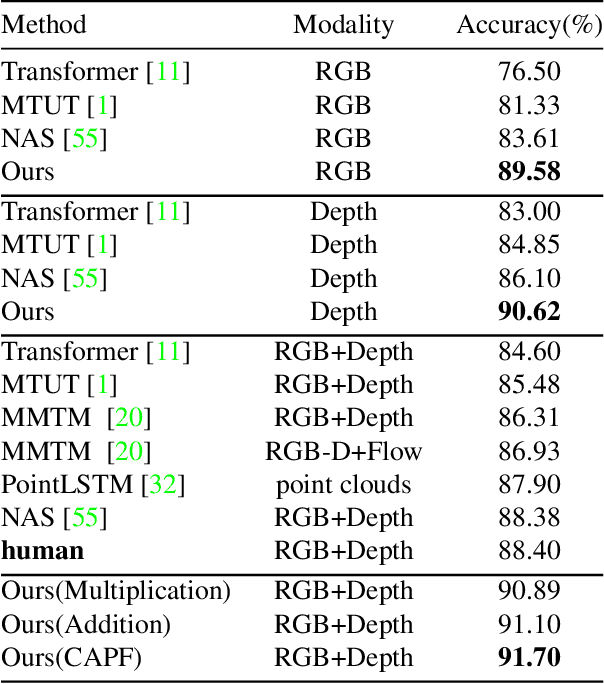
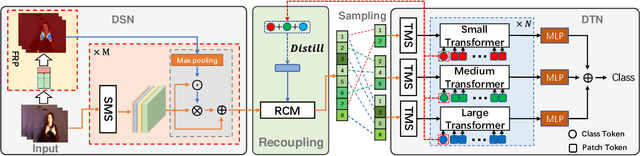
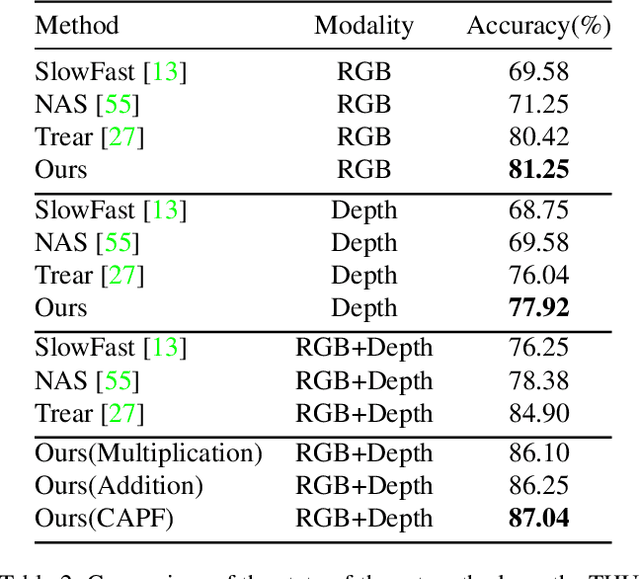
Decoupling spatiotemporal representation refers to decomposing the spatial and temporal features into dimension-independent factors. Although previous RGB-D-based motion recognition methods have achieved promising performance through the tightly coupled multi-modal spatiotemporal representation, they still suffer from (i) optimization difficulty under small data setting due to the tightly spatiotemporal-entangled modeling;(ii) information redundancy as it usually contains lots of marginal information that is weakly relevant to classification; and (iii) low interaction between multi-modal spatiotemporal information caused by insufficient late fusion. To alleviate these drawbacks, we propose to decouple and recouple spatiotemporal representation for RGB-D-based motion recognition. Specifically, we disentangle the task of learning spatiotemporal representation into 3 sub-tasks: (1) Learning high-quality and dimension independent features through a decoupled spatial and temporal modeling network. (2) Recoupling the decoupled representation to establish stronger space-time dependency. (3) Introducing a Cross-modal Adaptive Posterior Fusion (CAPF) mechanism to capture cross-modal spatiotemporal information from RGB-D data. Seamless combination of these novel designs forms a robust spatialtemporal representation and achieves better performance than state-of-the-art methods on four public motion datasets. Our code is available at https://github.com/damo-cv/MotionRGBD.
Regional Attention with Architecture-Rebuilt 3D Network for RGB-D Gesture Recognition
Mar 09, 2021
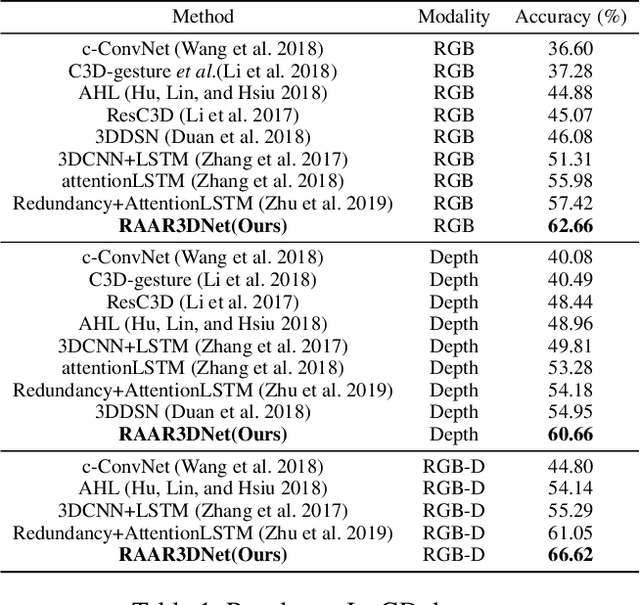

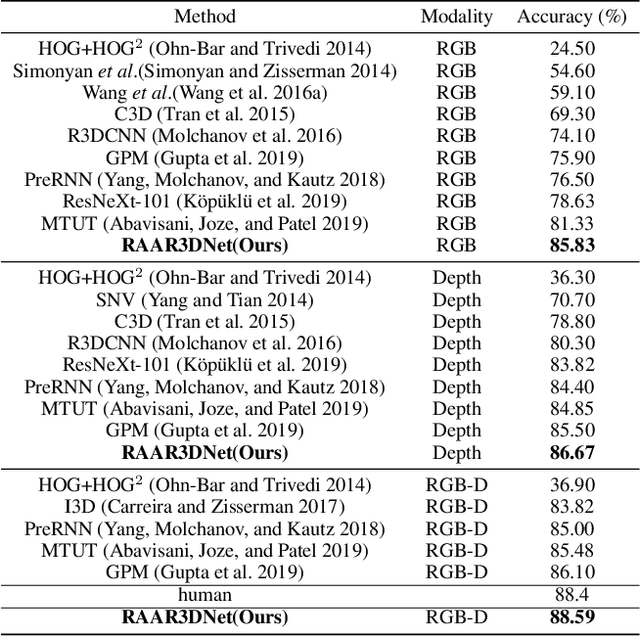
Human gesture recognition has drawn much attention in the area of computer vision. However, the performance of gesture recognition is always influenced by some gesture-irrelevant factors like the background and the clothes of performers. Therefore, focusing on the regions of hand/arm is important to the gesture recognition. Meanwhile, a more adaptive architecture-searched network structure can also perform better than the block-fixed ones like Resnet since it increases the diversity of features in different stages of the network better. In this paper, we propose a regional attention with architecture-rebuilt 3D network (RAAR3DNet) for gesture recognition. We replace the fixed Inception modules with the automatically rebuilt structure through the network via Neural Architecture Search (NAS), owing to the different shape and representation ability of features in the early, middle, and late stage of the network. It enables the network to capture different levels of feature representations at different layers more adaptively. Meanwhile, we also design a stackable regional attention module called dynamic-static Attention (DSA), which derives a Gaussian guidance heatmap and dynamic motion map to highlight the hand/arm regions and the motion information in the spatial and temporal domains, respectively. Extensive experiments on two recent large-scale RGB-D gesture datasets validate the effectiveness of the proposed method and show it outperforms state-of-the-art methods. The codes of our method are available at: https://github.com/zhoubenjia/RAAR3DNet.