 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePMMTalk: Speech-Driven 3D Facial Animation from Complementary Pseudo Multi-modal Features
Dec 05, 2023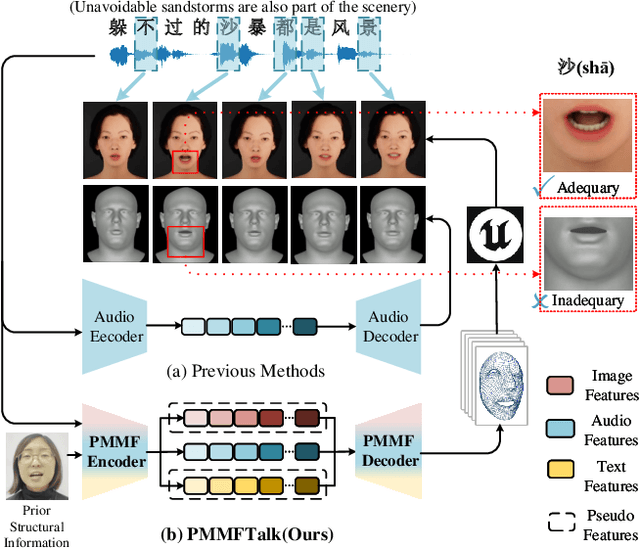
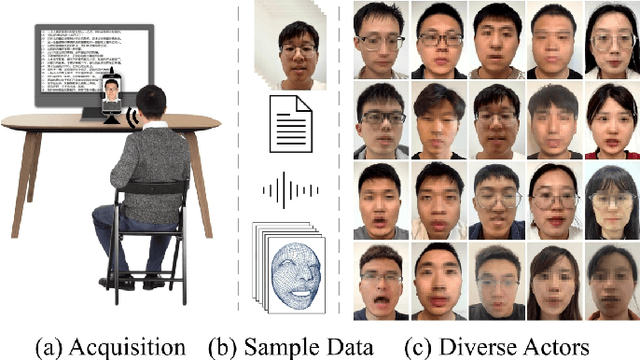
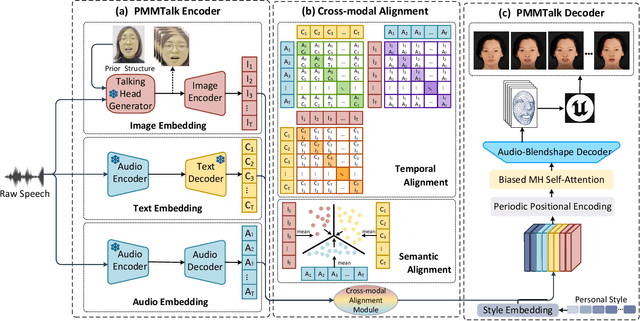
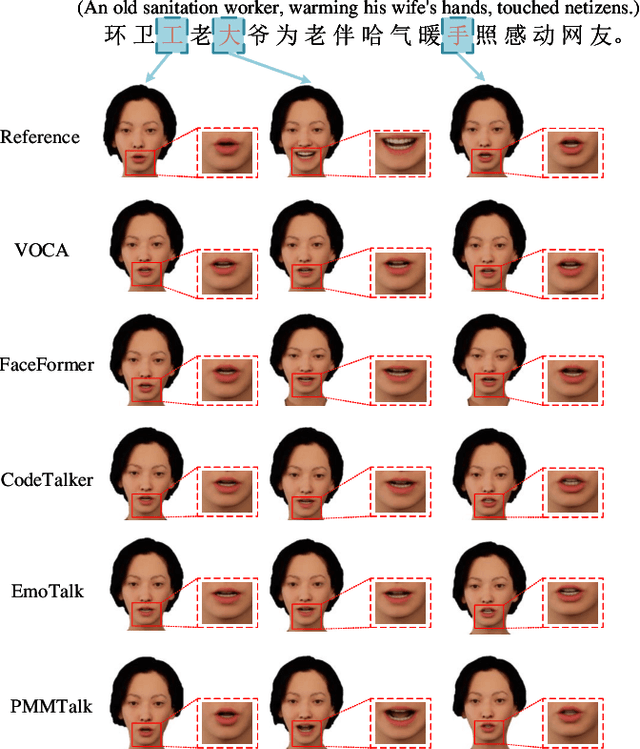
Speech-driven 3D facial animation has improved a lot recently while most related works only utilize acoustic modality and neglect the influence of visual and textual cues, leading to unsatisfactory results in terms of precision and coherence. We argue that visual and textual cues are not trivial information. Therefore, we present a novel framework, namely PMMTalk, using complementary Pseudo Multi-Modal features for improving the accuracy of facial animation. The framework entails three modules: PMMTalk encoder, cross-modal alignment module, and PMMTalk decoder. Specifically, the PMMTalk encoder employs the off-the-shelf talking head generation architecture and speech recognition technology to extract visual and textual information from speech, respectively. Subsequently, the cross-modal alignment module aligns the audio-image-text features at temporal and semantic levels. Then PMMTalk decoder is employed to predict lip-syncing facial blendshape coefficients. Contrary to prior methods, PMMTalk only requires an additional random reference face image but yields more accurate results. Additionally, it is artist-friendly as it seamlessly integrates into standard animation production workflows by introducing facial blendshape coefficients. Finally, given the scarcity of 3D talking face datasets, we introduce a large-scale 3D Chinese Audio-Visual Facial Animation (3D-CAVFA) dataset. Extensive experiments and user studies show that our approach outperforms the state of the art. We recommend watching the supplementary video.