 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Human-Like Grading: A Unified LLM-Enhanced Framework for Subjective Question Evaluation
Oct 09, 2025Automatic grading of subjective questions remains a significant challenge in examination assessment due to the diversity in question formats and the open-ended nature of student responses. Existing works primarily focus on a specific type of subjective question and lack the generality to support comprehensive exams that contain diverse question types. In this paper, we propose a unified Large Language Model (LLM)-enhanced auto-grading framework that provides human-like evaluation for all types of subjective questions across various domains. Our framework integrates four complementary modules to holistically evaluate student answers. In addition to a basic text matching module that provides a foundational assessment of content similarity, we leverage the powerful reasoning and generative capabilities of LLMs to: (1) compare key knowledge points extracted from both student and reference answers, (2) generate a pseudo-question from the student answer to assess its relevance to the original question, and (3) simulate human evaluation by identifying content-related and non-content strengths and weaknesses. Extensive experiments on both general-purpose and domain-specific datasets show that our framework consistently outperforms traditional and LLM-based baselines across multiple grading metrics. Moreover, the proposed system has been successfully deployed in real-world training and certification exams at a major e-commerce enterprise.
MERIT: A Merchant Incentive Ranking Model for Hotel Search & Ranking
Jun 10, 2025Online Travel Platforms (OTPs) have been working on improving their hotel Search & Ranking (S&R) systems that facilitate efficient matching between consumers and hotels. Existing OTPs focus almost exclusively on improving platform revenue. In this work, we take a first step in incorporating hotel merchants' objectives into the design of hotel S&R systems to achieve an incentive loop: the OTP tilts impressions and better-ranked positions to merchants with high quality, and in return, the merchants provide better service to consumers. Three critical design challenges need to be resolved to achieve this incentive loop: Matthew Effect in the consumer feedback-loop, unclear relation between hotel quality and performance, and conflicts between short-term and long-term revenue. To address these challenges, we propose MERIT, a MERchant IncenTive ranking model, which can simultaneously take the interests of merchants and consumers into account. We define a new Merchant Competitiveness Index (MCI) to represent hotel merchant quality and propose a new Merchant Tower to model the relation between MCI and ranking scores. Also, we design a monotonic structure for Merchant Tower to provide a clear relation between hotel quality and performance. Finally, we propose a Multi-objective Stratified Pairwise Loss, which can mitigate the conflicts between OTP's short-term and long-term revenue. The offline experiment results indicate that MERIT outperforms these methods in optimizing the demands of consumers and merchants. Furthermore, we conduct an online A/B test and obtain an improvement of 3.02% for the MCI score.
Whisper-SV: Adapting Whisper for Low-data-resource Speaker Verification
Jul 14, 2024



Trained on 680,000 hours of massive speech data, Whisper is a multitasking, multilingual speech foundation model demonstrating superior performance in automatic speech recognition, translation, and language identification. However, its applicability in speaker verification (SV) tasks remains unexplored, particularly in low-data-resource scenarios where labeled speaker data in specific domains are limited. To fill this gap, we propose a lightweight adaptor framework to boost SV with Whisper, namely Whisper-SV. Given that Whisper is not specifically optimized for SV tasks, we introduce a representation selection module to quantify the speaker-specific characteristics contained in each layer of Whisper and select the top-k layers with prominent discriminative speaker features. To aggregate pivotal speaker-related features while diminishing non-speaker redundancies across the selected top-k distinct layers of Whisper, we design a multi-layer aggregation module in Whisper-SV to integrate multi-layer representations into a singular, compacted representation for SV. In the multi-layer aggregation module, we employ convolutional layers with shortcut connections among different layers to refine speaker characteristics derived from multi-layer representations from Whisper. In addition, an attention aggregation layer is used to reduce non-speaker interference and amplify speaker-specific cues for SV tasks. Finally, a simple classification module is used for speaker classification. Experiments on VoxCeleb1, FFSVC, and IMSV datasets demonstrate that Whisper-SV achieves EER/minDCF of 2.22%/0.307, 6.14%/0.488, and 7.50%/0.582, respectively, showing superior performance in low-data-resource SV scenarios.
Factorized Learning Assisted with Large Language Model for Gloss-free Sign Language Translation
Mar 19, 2024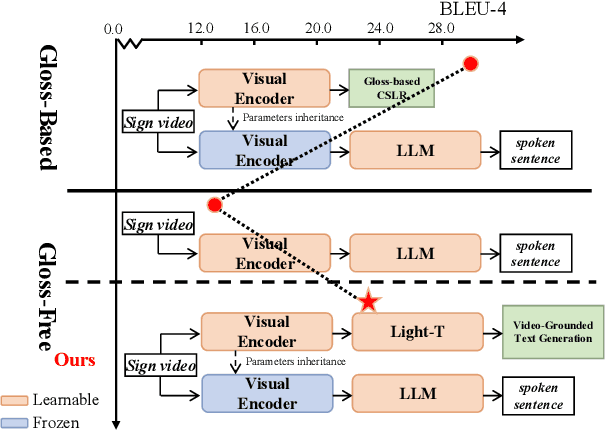
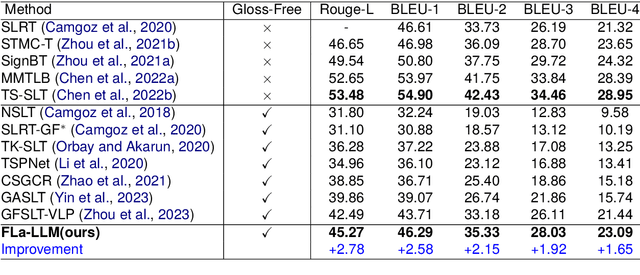
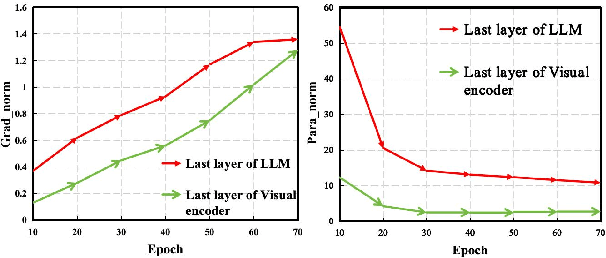
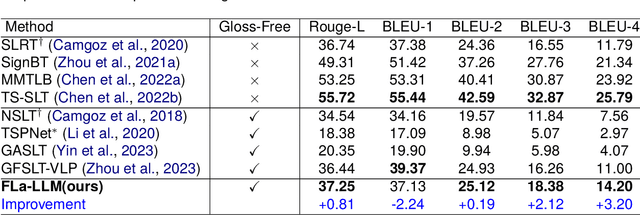
Previous Sign Language Translation (SLT) methods achieve superior performance by relying on gloss annotations. However, labeling high-quality glosses is a labor-intensive task, which limits the further development of SLT. Although some approaches work towards gloss-free SLT through jointly training the visual encoder and translation network, these efforts still suffer from poor performance and inefficient use of the powerful Large Language Model (LLM). Most seriously, we find that directly introducing LLM into SLT will lead to insufficient learning of visual representations as LLM dominates the learning curve. To address these problems, we propose Factorized Learning assisted with Large Language Model (FLa-LLM) for gloss-free SLT. Concretely, we factorize the training process into two stages. In the visual initialing stage, we employ a lightweight translation model after the visual encoder to pre-train the visual encoder. In the LLM fine-tuning stage, we freeze the acquired knowledge in the visual encoder and integrate it with a pre-trained LLM to inspire the LLM's translation potential. This factorized training strategy proves to be highly effective as evidenced by significant improvements achieved across three SLT datasets which are all conducted under the gloss-free setting.
An audio-quality-based multi-strategy approach for target speaker extraction in the MISP 2023 Challenge
Jan 08, 2024This paper describes our audio-quality-based multi-strategy approach for the audio-visual target speaker extraction (AVTSE) task in the Multi-modal Information based Speech Processing (MISP) 2023 Challenge. Specifically, our approach adopts different extraction strategies based on the audio quality, striking a balance between interference removal and speech preservation, which benifits the back-end automatic speech recognition (ASR) systems. Experiments show that our approach achieves a character error rate (CER) of 24.2% and 33.2% on the Dev and Eval set, respectively, obtaining the second place in the challenge.
R2-Talker: Realistic Real-Time Talking Head Synthesis with Hash Grid Landmarks Encoding and Progressive Multilayer Conditioning
Dec 09, 2023



Dynamic NeRFs have recently garnered growing attention for 3D talking portrait synthesis. Despite advances in rendering speed and visual quality, challenges persist in enhancing efficiency and effectiveness. We present R2-Talker, an efficient and effective framework enabling realistic real-time talking head synthesis. Specifically, using multi-resolution hash grids, we introduce a novel approach for encoding facial landmarks as conditional features. This approach losslessly encodes landmark structures as conditional features, decoupling input diversity, and conditional spaces by mapping arbitrary landmarks to a unified feature space. We further propose a scheme of progressive multilayer conditioning in the NeRF rendering pipeline for effective conditional feature fusion. Our new approach has the following advantages as demonstrated by extensive experiments compared with the state-of-the-art works: 1) The lossless input encoding enables acquiring more precise features, yielding superior visual quality. The decoupling of inputs and conditional spaces improves generalizability. 2) The fusing of conditional features and MLP outputs at each MLP layer enhances conditional impact, resulting in more accurate lip synthesis and better visual quality. 3) It compactly structures the fusion of conditional features, significantly enhancing computational efficiency.
PMMTalk: Speech-Driven 3D Facial Animation from Complementary Pseudo Multi-modal Features
Dec 05, 2023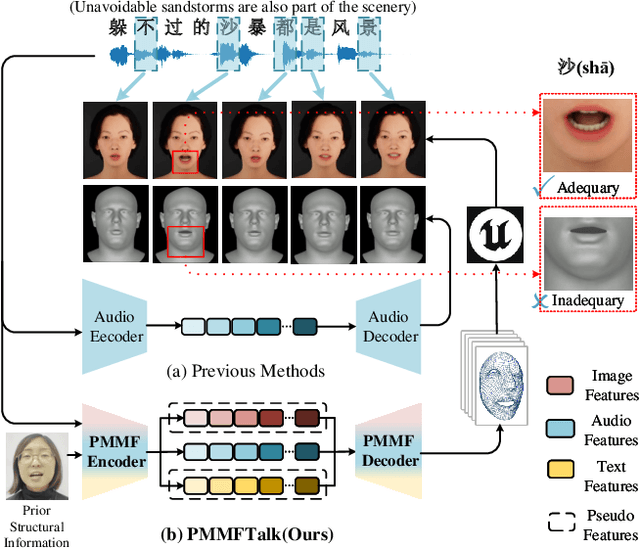
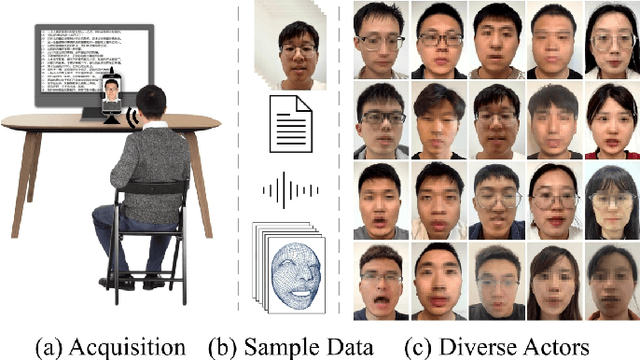
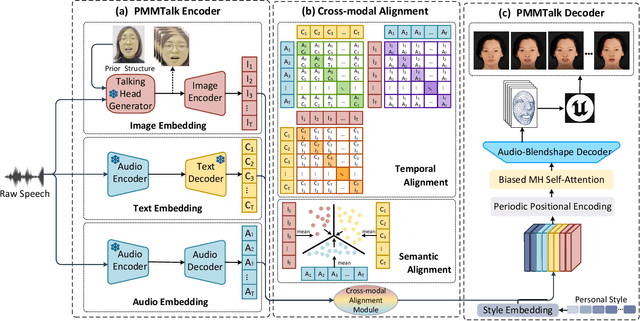
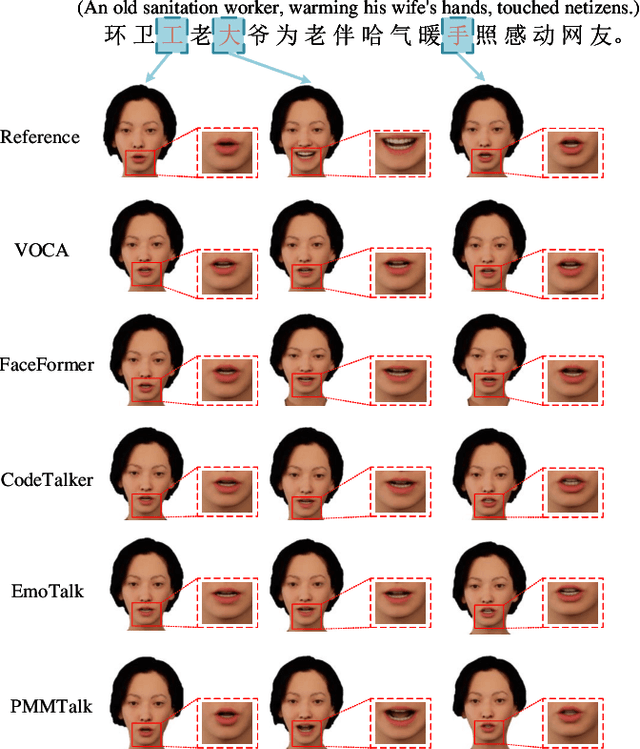
Speech-driven 3D facial animation has improved a lot recently while most related works only utilize acoustic modality and neglect the influence of visual and textual cues, leading to unsatisfactory results in terms of precision and coherence. We argue that visual and textual cues are not trivial information. Therefore, we present a novel framework, namely PMMTalk, using complementary Pseudo Multi-Modal features for improving the accuracy of facial animation. The framework entails three modules: PMMTalk encoder, cross-modal alignment module, and PMMTalk decoder. Specifically, the PMMTalk encoder employs the off-the-shelf talking head generation architecture and speech recognition technology to extract visual and textual information from speech, respectively. Subsequently, the cross-modal alignment module aligns the audio-image-text features at temporal and semantic levels. Then PMMTalk decoder is employed to predict lip-syncing facial blendshape coefficients. Contrary to prior methods, PMMTalk only requires an additional random reference face image but yields more accurate results. Additionally, it is artist-friendly as it seamlessly integrates into standard animation production workflows by introducing facial blendshape coefficients. Finally, given the scarcity of 3D talking face datasets, we introduce a large-scale 3D Chinese Audio-Visual Facial Animation (3D-CAVFA) dataset. Extensive experiments and user studies show that our approach outperforms the state of the art. We recommend watching the supplementary video.
Conversational Speech Recognition by Learning Audio-textual Cross-modal Contextual Representation
Oct 22, 2023Automatic Speech Recognition (ASR) in conversational settings presents unique challenges, including extracting relevant contextual information from previous conversational turns. Due to irrelevant content, error propagation, and redundancy, existing methods struggle to extract longer and more effective contexts. To address this issue, we introduce a novel Conversational ASR system, extending the Conformer encoder-decoder model with cross-modal conversational representation. Our approach leverages a cross-modal extractor that combines pre-trained speech and text models through a specialized encoder and a modal-level mask input. This enables the extraction of richer historical speech context without explicit error propagation. We also incorporate conditional latent variational modules to learn conversational level attributes such as role preference and topic coherence. By introducing both cross-modal and conversational representations into the decoder, our model retains context over longer sentences without information loss, achieving relative accuracy improvements of 8.8% and 23% on Mandarin conversation datasets HKUST and MagicData-RAMC, respectively, compared to the standard Conformer model.
Modeling Price Elasticity for Occupancy Prediction in Hotel Dynamic Pricing
Aug 11, 2022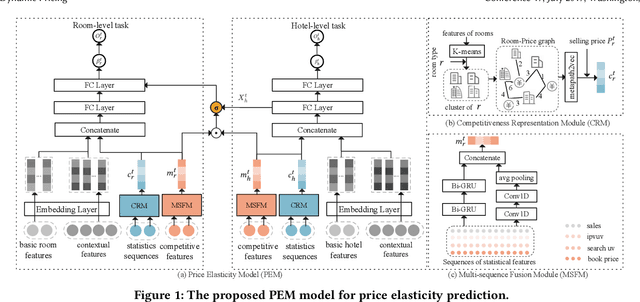
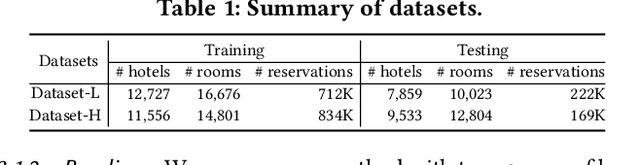
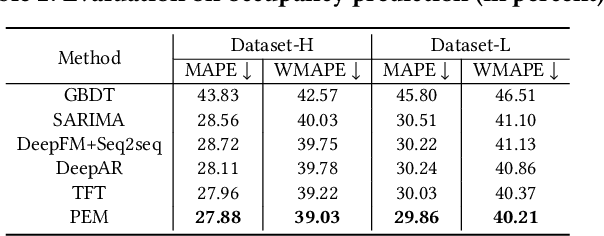

Demand estimation plays an important role in dynamic pricing where the optimal price can be obtained via maximizing the revenue based on the demand curve. In online hotel booking platform, the demand or occupancy of rooms varies across room-types and changes over time, and thus it is challenging to get an accurate occupancy estimate. In this paper, we propose a novel hotel demand function that explicitly models the price elasticity of demand for occupancy prediction, and design a price elasticity prediction model to learn the dynamic price elasticity coefficient from a variety of affecting factors. Our model is composed of carefully designed elasticity learning modules to alleviate the endogeneity problem, and trained in a multi-task framework to tackle the data sparseness. We conduct comprehensive experiments on real-world datasets and validate the superiority of our method over the state-of-the-art baselines for both occupancy prediction and dynamic pricing.
SAR-Net: A Scenario-Aware Ranking Network for Personalized Fair Recommendation in Hundreds of Travel Scenarios
Oct 19, 2021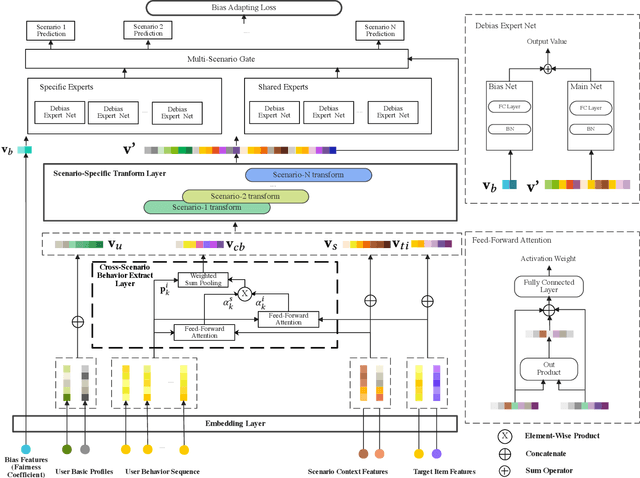


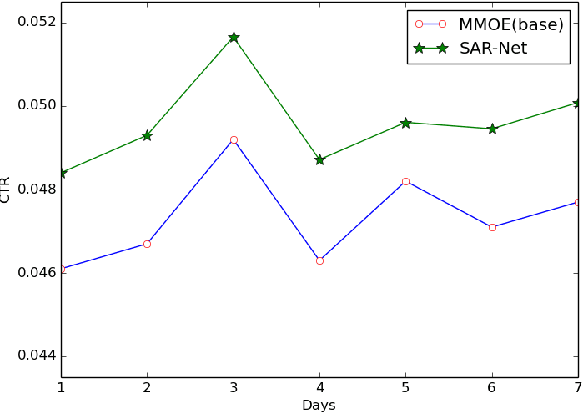
The travel marketing platform of Alibaba serves an indispensable role for hundreds of different travel scenarios from Fliggy, Taobao, Alipay apps, etc. To provide personalized recommendation service for users visiting different scenarios, there are two critical issues to be carefully addressed. First, since the traffic characteristics of different scenarios, it is very challenging to train a unified model to serve all. Second, during the promotion period, the exposure of some specific items will be re-weighted due to manual intervention, resulting in biased logs, which will degrade the ranking model trained using these biased data. In this paper, we propose a novel Scenario-Aware Ranking Network (SAR-Net) to address these issues. SAR-Net harvests the abundant data from different scenarios by learning users' cross-scenario interests via two specific attention modules, which leverage the scenario features and item features to modulate the user behavior features, respectively. Then, taking the encoded features of previous module as input, a scenario-specific linear transformation layer is adopted to further extract scenario-specific features, followed by two groups of debias expert networks, i.e., scenario-specific experts and scenario-shared experts. They output intermediate results independently, which are further fused into the final result by a multi-scenario gating module. In addition, to mitigate the data fairness issue caused by manual intervention, we propose the concept of Fairness Coefficient (FC) to measures the importance of individual sample and use it to reweigh the prediction in the debias expert networks. Experiments on an offline dataset covering over 80 million users and 1.55 million travel items and an online A/B test demonstrate the effectiveness of our SAR-Net and its superiority over state-of-the-art methods.