 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-driven Learning of Probabilistic Model of Binary Droplet Collision for Spray Simulation
Apr 15, 2026Binary droplet collisions are ubiquitous in dense sprays. Traditional deterministic models cannot adequately represent transitional and stochastic behaviors of binary droplet collision. To bridge this gap, we developed a probabilistic model by using a machine learning approach, the Light Gradient-Boosting Machine (LightGBM). The model was trained on a comprehensive dataset of 33,540 experimental cases covering eight collision regimes across broad ranges of Weber number, Ohnesorge number, impact parameter, size ratio, and ambient pressure. The resulting machine learning classifier captures highly nonlinear regime boundaries with 99.2% accuracy and retains sensitivity in transitional regions. To facilitate its implementation in spray simulation, the model was translated into a probabilistic form, a multinomial logistic regression, which preserves 93.2% accuracy and maps continuous inter-regime transitions. A biased-dice sampling mechanism then converts these probabilities into definite yet stochastic outcomes. This work presents the first probabilistic, high-dimensional droplet collision model derived from experimental data, offering a physically consistent, comprehensive, and user-friendly solution for spray simulation.
Dynamical Mode Recognition of Turbulent Flames in a Swirl-stabilized Annular Combustor by a Time-series Learning Approach
Mar 17, 2025Thermoacoustic instability in annular combustors, essential to aero engines and modern gas turbines, can severely impair operational stability and efficiency, accurately recognizing and understanding various combustion modes is the prerequisite for understanding and controlling combustion instabilities. However, the high-dimensional spatial-temporal dynamics of turbulent flames typically pose considerable challenges to mode recognition. Based on the bidirectional temporal and nonlinear dimensionality reduction models, this study introduces a two-layer bidirectional long short-term memory variational autoencoder, Bi-LSTM-VAE model, to effectively recognize dynamical modes in annular combustion systems. Specifically, leveraging 16 pressure signals from a swirl-stabilized annular combustor, the model maps complex dynamics into a low-dimensional latent space while preserving temporal dependency and nonlinear behavior features through the recurrent neural network structure. The results show that the novel Bi-LSTM-VAE method enables a clear representation of combustion states in two-dimensional state space. Analysis of latent variable distributions reveals distinct patterns corresponding to a wide range of equivalence ratios and premixed fuel and air mass flow rates, offering novel insights into mode classification and transitions, highlighting this model's potential for deciphering complex thermoacoustic phenomena.
Stabilization Analysis and Mode Recognition of Kerosene Supersonic Combustion: A Deep Learning Approach Based on Res-CNN-beta-VAE
Mar 17, 2025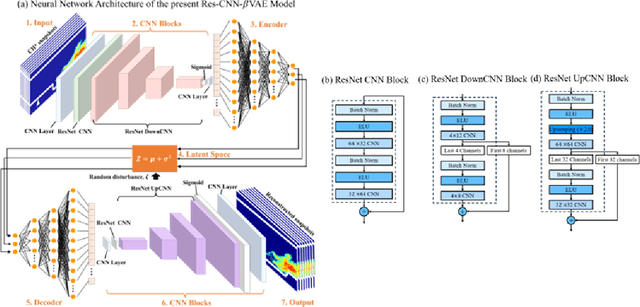
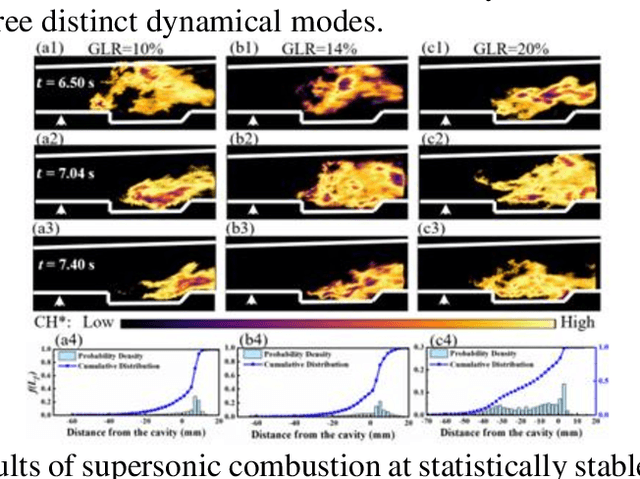
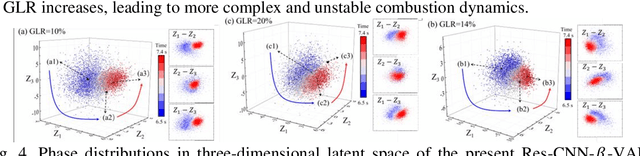

The scramjet engine is a key propulsion system for hypersonic vehicles, leveraging supersonic airflow to achieve high specific impulse, making it a promising technology for aerospace applications. Understanding and controlling the complex interactions between fuel injection, turbulent combustion, and aerodynamic effects of compressible flows are crucial for ensuring stable combustion in scramjet engines. However, identifying stable modes in scramjet combustors is often challenging due to limited experimental measurement means and extremely complex spatiotemporal evolution of supersonic turbulent combustion. This work introduces an innovative deep learning framework that combines dimensionality reduction via the Residual Convolutional Neural Network-beta-Variational Autoencoder (Res-CNN-beta-VAE) model with unsupervised clustering (K-means) to identify and analyze dynamical combustion modes in a supersonic combustor. By mapping high-dimensional data of combustion snapshots to a reduced three-dimensional latent space, the Res-CNN-beta-VAE model captures the essential temporal and spatial features of flame behaviors and enables the observation of transitions between combustion states. By analyzing the standard deviation of latent variable trajectories, we introduce a novel method for objectively distinguishing between dynamic transitions, which provides a scalable and expert-independent alternative to traditional classification methods. Besides, the unsupervised K-means clustering approach effectively identifies the complex interplay between the cavity and the jet-wake stabilization mechanisms, offering new insights into the system's behavior across different gas-to-liquid mass flow ratios (GLRs).
Steam Turbine Anomaly Detection: An Unsupervised Learning Approach Using Enhanced Long Short-Term Memory Variational Autoencoder
Nov 16, 2024As core thermal power generation equipment, steam turbines incur significant expenses and adverse effects on operation when facing interruptions like downtime, maintenance, and damage. Accurate anomaly detection is the prerequisite for ensuring the safe and stable operation of steam turbines. However, challenges in steam turbine anomaly detection, including inherent anomalies, lack of temporal information analysis, and high-dimensional data complexity, limit the effectiveness of existing methods. To address these challenges, we proposed an Enhanced Long Short-Term Memory Variational Autoencoder using Deep Advanced Features and Gaussian Mixture Model (ELSTMVAE-DAF-GMM) for precise unsupervised anomaly detection in unlabeled datasets. Specifically, LSTMVAE, integrating LSTM with VAE, was used to project high-dimensional time-series data to a low-dimensional phase space. The Deep Autoencoder-Local Outlier Factor (DAE-LOF) sample selection mechanism was used to eliminate inherent anomalies during training, further improving the model's precision and reliability. The novel deep advanced features (DAF) hybridize latent embeddings and reconstruction discrepancies from the LSTMVAE model and provide a more comprehensive data representation within a continuous and structured phase space, significantly enhancing anomaly detection by synergizing temporal dynamics with data pattern variations. These DAF were incorporated into GMM to ensure robust and effective unsupervised anomaly detection. We utilized real operating data from industry steam turbines and conducted both comparison and ablation experiments, demonstrating superior anomaly detection outcomes characterized by high accuracy and minimal false alarm rates compared with existing methods.
Distil-DCCRN: A Small-footprint DCCRN Leveraging Feature-based Knowledge Distillation in Speech Enhancement
Aug 08, 2024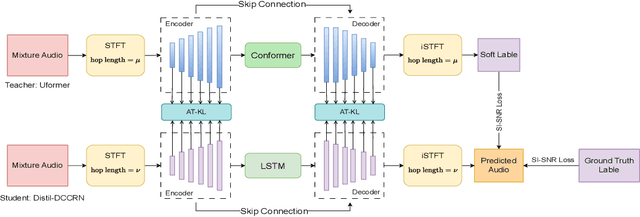
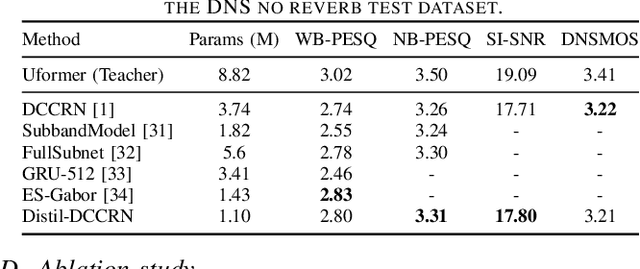

The deep complex convolution recurrent network (DCCRN) achieves excellent speech enhancement performance by utilizing the audio spectrum's complex features. However, it has a large number of model parameters. We propose a smaller model, Distil-DCCRN, which has only 30% of the parameters compared to the DCCRN. To ensure that the performance of Distil-DCCRN matches that of the DCCRN, we employ the knowledge distillation (KD) method to use a larger teacher model to help train a smaller student model. We design a knowledge distillation (KD) method, integrating attention transfer and Kullback-Leibler divergence (AT-KL) to train the student model Distil-DCCRN. Additionally, we use a model with better performance and a more complicated structure, Uformer, as the teacher model. Unlike previous KD approaches that mainly focus on model outputs, our method also leverages the intermediate features from the models' middle layers, facilitating rich knowledge transfer across different structured models despite variations in layer configurations and discrepancies in the channel and time dimensions of intermediate features. Employing our AT-KL approach, Distil-DCCRN outperforms DCCRN as well as several other competitive models in both PESQ and SI-SNR metrics on the DNS test set and achieves comparable results to DCCRN in DNSMOS.
WenetSpeech4TTS: A 12,800-hour Mandarin TTS Corpus for Large Speech Generation Model Benchmark
Jun 11, 2024
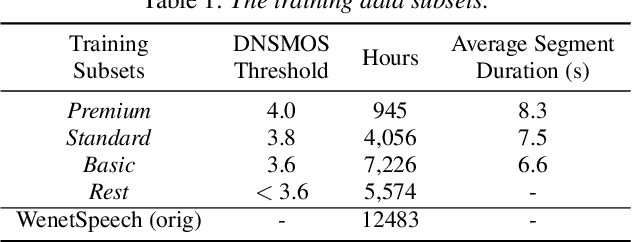
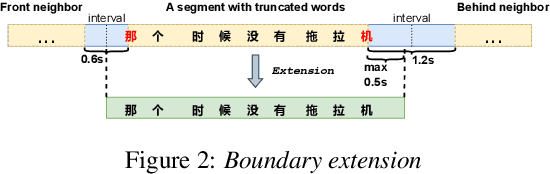
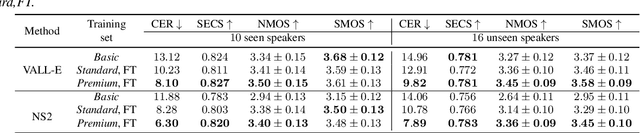
With the development of large text-to-speech (TTS) models and scale-up of the training data, state-of-the-art TTS systems have achieved impressive performance. In this paper, we present WenetSpeech4TTS, a multi-domain Mandarin corpus derived from the open-sourced WenetSpeech dataset. Tailored for the text-to-speech tasks, we refined WenetSpeech by adjusting segment boundaries, enhancing the audio quality, and eliminating speaker mixing within each segment. Following a more accurate transcription process and quality-based data filtering process, the obtained WenetSpeech4TTS corpus contains $12,800$ hours of paired audio-text data. Furthermore, we have created subsets of varying sizes, categorized by segment quality scores to allow for TTS model training and fine-tuning. VALL-E and NaturalSpeech 2 systems are trained and fine-tuned on these subsets to validate the usability of WenetSpeech4TTS, establishing baselines on benchmark for fair comparison of TTS systems. The corpus and corresponding benchmarks are publicly available on huggingface.
Dynamical Mode Recognition of Coupled Flame Oscillators by Supervised and Unsupervised Learning Approaches
Apr 27, 2024



Combustion instability in gas turbines and rocket engines, as one of the most challenging problems in combustion research, arises from the complex interactions among flames, which are also influenced by chemical reactions, heat and mass transfer, and acoustics. Identifying and understanding combustion instability is essential to ensure the safe and reliable operation of many combustion systems, where exploring and classifying the dynamical behaviors of complex flame systems is a core take. To facilitate fundamental studies, the present work concerns dynamical mode recognition of coupled flame oscillators made of flickering buoyant diffusion flames, which have gained increasing attention in recent years but are not sufficiently understood. The time series data of flame oscillators are generated by fully validated reacting flow simulations. Due to limitations of expertise-based models, a data-driven approach is adopted. In this study, a nonlinear dimensional reduction model of variational autoencoder (VAE) is used to project the simulation data onto a 2-dimensional latent space. Based on the phase trajectories in latent space, both supervised and unsupervised classifiers are proposed for datasets with well known labeling and without, respectively. For labeled datasets, we establish the Wasserstein-distance-based classifier (WDC) for mode recognition; for unlabeled datasets, we develop a novel unsupervised classifier (GMM-DTWC) combining dynamic time warping (DTW) and Gaussian mixture model (GMM). Through comparing with conventional approaches for dimensionality reduction and classification, the proposed supervised and unsupervised VAE-based approaches exhibit a prominent performance for distinguishing dynamical modes, implying their potential extension to dynamical mode recognition of complex combustion problems.
An audio-quality-based multi-strategy approach for target speaker extraction in the MISP 2023 Challenge
Jan 08, 2024This paper describes our audio-quality-based multi-strategy approach for the audio-visual target speaker extraction (AVTSE) task in the Multi-modal Information based Speech Processing (MISP) 2023 Challenge. Specifically, our approach adopts different extraction strategies based on the audio quality, striking a balance between interference removal and speech preservation, which benifits the back-end automatic speech recognition (ASR) systems. Experiments show that our approach achieves a character error rate (CER) of 24.2% and 33.2% on the Dev and Eval set, respectively, obtaining the second place in the challenge.
Dimensionality Reduction and Dynamical Mode Recognition of Circular Arrays of Flame Oscillators Using Deep Neural Network
Dec 05, 2023



Oscillatory combustion in aero engines and modern gas turbines often has significant adverse effects on their operation, and accurately recognizing various oscillation modes is the prerequisite for understanding and controlling combustion instability. However, the high-dimensional spatial-temporal data of a complex combustion system typically poses considerable challenges to the dynamical mode recognition. Based on a two-layer bidirectional long short-term memory variational autoencoder (Bi-LSTM-VAE) dimensionality reduction model and a two-dimensional Wasserstein distance-based classifier (WDC), this study proposes a promising method (Bi-LSTM-VAE-WDC) for recognizing dynamical modes in oscillatory combustion systems. Specifically, the Bi-LSTM-VAE dimension reduction model was introduced to reduce the high-dimensional spatial-temporal data of the combustion system to a low-dimensional phase space; Gaussian kernel density estimates (GKDE) were computed based on the distribution of phase points in a grid; two-dimensional WD values were calculated from the GKDE maps to recognize the oscillation modes. The time-series data used in this study were obtained from numerical simulations of circular arrays of laminar flame oscillators. The results show that the novel Bi-LSTM-VAE method can produce a non-overlapping distribution of phase points, indicating an effective unsupervised mode recognition and classification. Furthermore, the present method exhibits a more prominent performance than VAE and PCA (principal component analysis) for distinguishing dynamical modes in complex flame systems, implying its potential in studying turbulent combustion.
MBTFNet: Multi-Band Temporal-Frequency Neural Network For Singing Voice Enhancement
Oct 06, 2023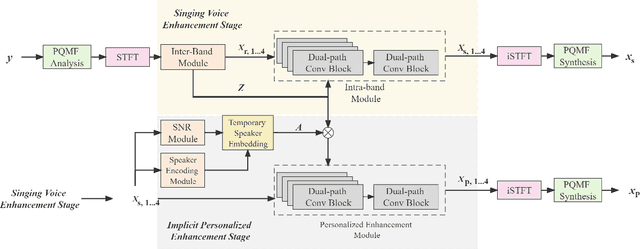
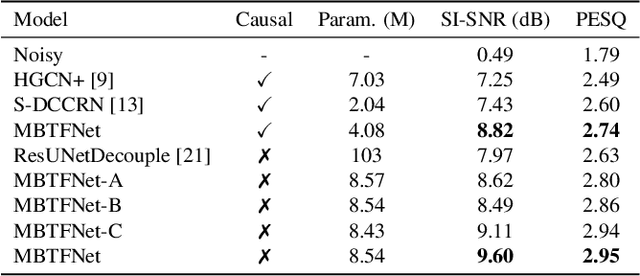
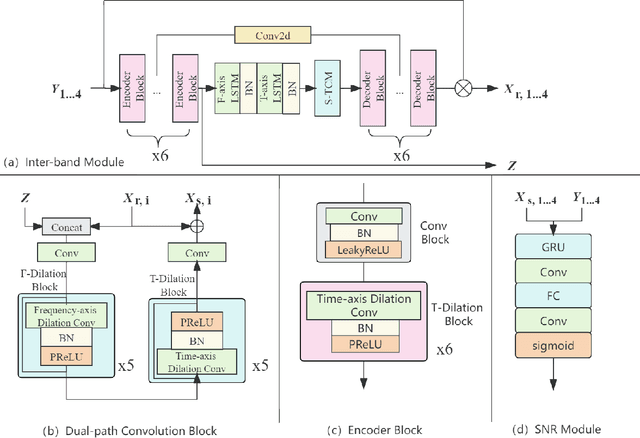
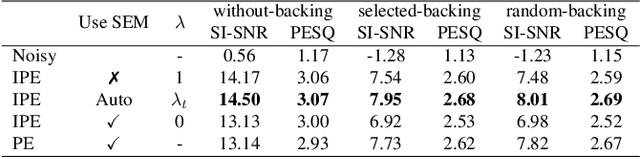
A typical neural speech enhancement (SE) approach mainly handles speech and noise mixtures, which is not optimal for singing voice enhancement scenarios. Music source separation (MSS) models treat vocals and various accompaniment components equally, which may reduce performance compared to the model that only considers vocal enhancement. In this paper, we propose a novel multi-band temporal-frequency neural network (MBTFNet) for singing voice enhancement, which particularly removes background music, noise and even backing vocals from singing recordings. MBTFNet combines inter and intra-band modeling for better processing of full-band signals. Dual-path modeling are introduced to expand the receptive field of the model. We propose an implicit personalized enhancement (IPE) stage based on signal-to-noise ratio (SNR) estimation, which further improves the performance of MBTFNet. Experiments show that our proposed model significantly outperforms several state-of-the-art SE and MSS models.