 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamical Mode Recognition of Turbulent Flames in a Swirl-stabilized Annular Combustor by a Time-series Learning Approach
Mar 17, 2025Thermoacoustic instability in annular combustors, essential to aero engines and modern gas turbines, can severely impair operational stability and efficiency, accurately recognizing and understanding various combustion modes is the prerequisite for understanding and controlling combustion instabilities. However, the high-dimensional spatial-temporal dynamics of turbulent flames typically pose considerable challenges to mode recognition. Based on the bidirectional temporal and nonlinear dimensionality reduction models, this study introduces a two-layer bidirectional long short-term memory variational autoencoder, Bi-LSTM-VAE model, to effectively recognize dynamical modes in annular combustion systems. Specifically, leveraging 16 pressure signals from a swirl-stabilized annular combustor, the model maps complex dynamics into a low-dimensional latent space while preserving temporal dependency and nonlinear behavior features through the recurrent neural network structure. The results show that the novel Bi-LSTM-VAE method enables a clear representation of combustion states in two-dimensional state space. Analysis of latent variable distributions reveals distinct patterns corresponding to a wide range of equivalence ratios and premixed fuel and air mass flow rates, offering novel insights into mode classification and transitions, highlighting this model's potential for deciphering complex thermoacoustic phenomena.
TOPS: Transition-based VOlatility-controlled Policy Search and its Global Convergence
Jan 24, 2022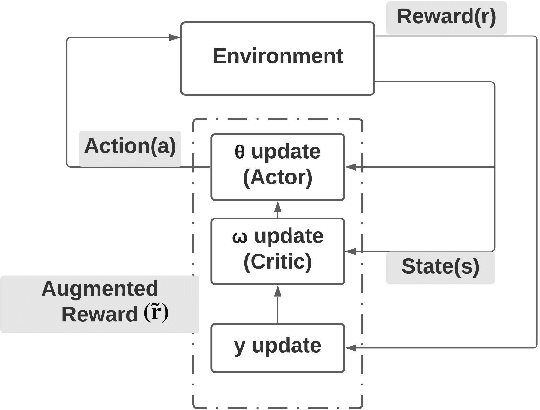
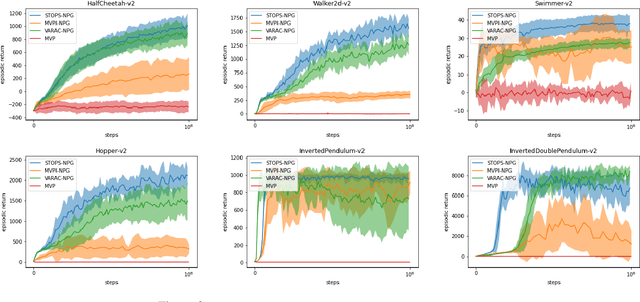
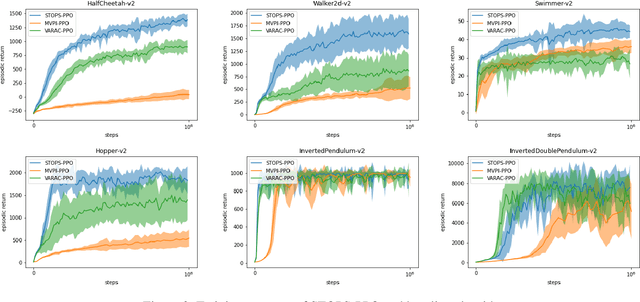
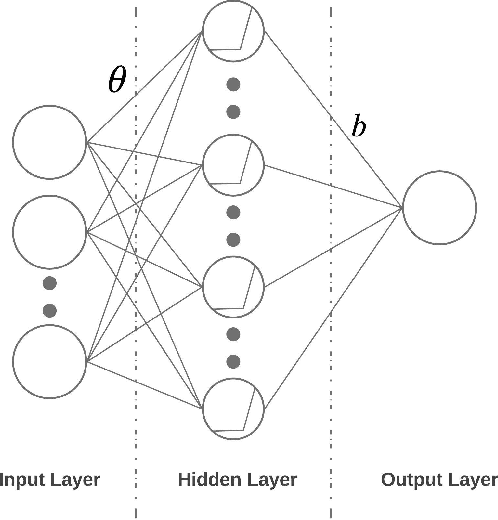
Risk-averse problems receive far less attention than risk-neutral control problems in reinforcement learning, and existing risk-averse approaches are challenging to deploy to real-world applications. One primary reason is that such risk-averse algorithms often learn from consecutive trajectories with a certain length, which significantly increases the potential danger of causing dangerous failures in practice. This paper proposes Transition-based VOlatility-controlled Policy Search (TOPS), a novel algorithm that solves risk-averse problems by learning from (possibly non-consecutive) transitions instead of only consecutive trajectories. By using an actor-critic scheme with an overparameterized two-layer neural network, our algorithm finds a globally optimal policy at a sublinear rate with proximal policy optimization and natural policy gradient, with effectiveness comparable to the state-of-the-art convergence rate of risk-neutral policy-search methods. The algorithm is evaluated on challenging Mujoco robot simulation tasks under the mean-variance evaluation metric. Both theoretical analysis and experimental results demonstrate a state-of-the-art level of risk-averse policy search methods.