 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWenetSpeech4TTS: A 12,800-hour Mandarin TTS Corpus for Large Speech Generation Model Benchmark
Paper and Code
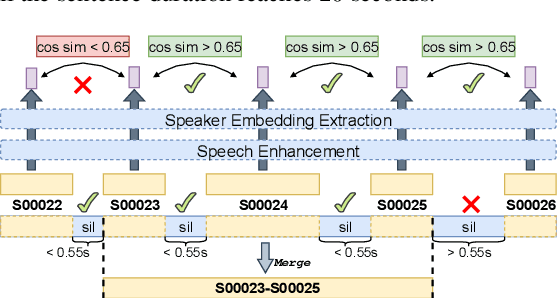
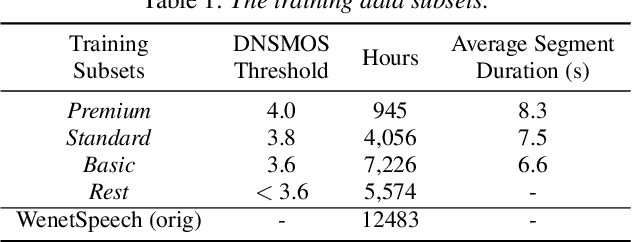
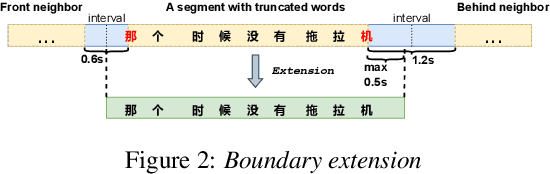
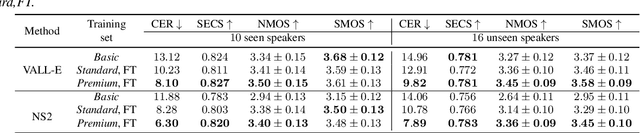
With the development of large text-to-speech (TTS) models and scale-up of the training data, state-of-the-art TTS systems have achieved impressive performance. In this paper, we present WenetSpeech4TTS, a multi-domain Mandarin corpus derived from the open-sourced WenetSpeech dataset. Tailored for the text-to-speech tasks, we refined WenetSpeech by adjusting segment boundaries, enhancing the audio quality, and eliminating speaker mixing within each segment. Following a more accurate transcription process and quality-based data filtering process, the obtained WenetSpeech4TTS corpus contains $12,800$ hours of paired audio-text data. Furthermore, we have created subsets of varying sizes, categorized by segment quality scores to allow for TTS model training and fine-tuning. VALL-E and NaturalSpeech 2 systems are trained and fine-tuned on these subsets to validate the usability of WenetSpeech4TTS, establishing baselines on benchmark for fair comparison of TTS systems. The corpus and corresponding benchmarks are publicly available on huggingface.