 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProAPO: Progressively Automatic Prompt Optimization for Visual Classification
Feb 27, 2025
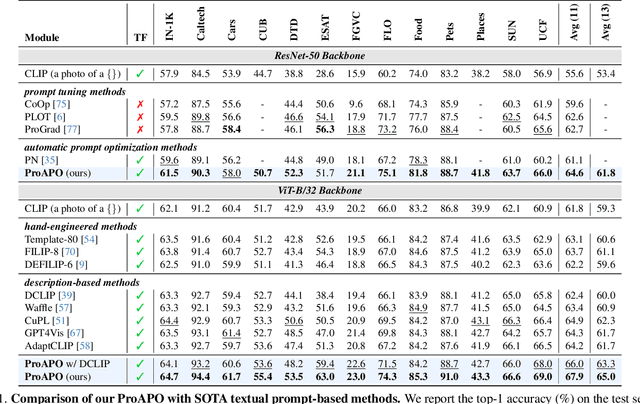
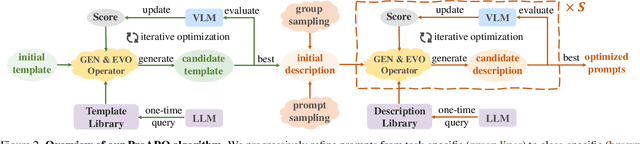
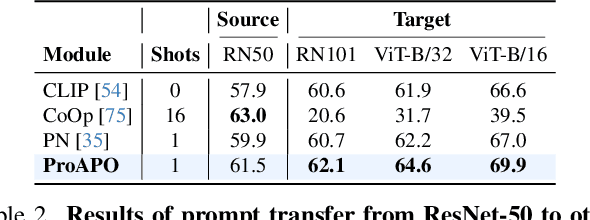
Vision-language models (VLMs) have made significant progress in image classification by training with large-scale paired image-text data. Their performances largely depend on the prompt quality. While recent methods show that visual descriptions generated by large language models (LLMs) enhance the generalization of VLMs, class-specific prompts may be inaccurate or lack discrimination due to the hallucination in LLMs. In this paper, we aim to find visually discriminative prompts for fine-grained categories with minimal supervision and no human-in-the-loop. An evolution-based algorithm is proposed to progressively optimize language prompts from task-specific templates to class-specific descriptions. Unlike optimizing templates, the search space shows an explosion in class-specific candidate prompts. This increases prompt generation costs, iterative times, and the overfitting problem. To this end, we first introduce several simple yet effective edit-based and evolution-based operations to generate diverse candidate prompts by one-time query of LLMs. Then, two sampling strategies are proposed to find a better initial search point and reduce traversed categories, saving iteration costs. Moreover, we apply a novel fitness score with entropy constraints to mitigate overfitting. In a challenging one-shot image classification setting, our method outperforms existing textual prompt-based methods and improves LLM-generated description methods across 13 datasets. Meanwhile, we demonstrate that our optimal prompts improve adapter-based methods and transfer effectively across different backbones.
Enhance Hyperbolic Representation Learning via Second-order Pooling
Oct 29, 2024



Hyperbolic representation learning is well known for its ability to capture hierarchical information. However, the distance between samples from different levels of hierarchical classes can be required large. We reveal that the hyperbolic discriminant objective forces the backbone to capture this hierarchical information, which may inevitably increase the Lipschitz constant of the backbone. This can hinder the full utilization of the backbone's generalization ability. To address this issue, we introduce second-order pooling into hyperbolic representation learning, as it naturally increases the distance between samples without compromising the generalization ability of the input features. In this way, the Lipschitz constant of the backbone does not necessarily need to be large. However, current off-the-shelf low-dimensional bilinear pooling methods cannot be directly employed in hyperbolic representation learning because they inevitably reduce the distance expansion capability. To solve this problem, we propose a kernel approximation regularization, which enables the low-dimensional bilinear features to approximate the kernel function well in low-dimensional space. Finally, we conduct extensive experiments on graph-structured datasets to demonstrate the effectiveness of the proposed method.
Exploring Information-Theoretic Metrics Associated with Neural Collapse in Supervised Training
Sep 25, 2024



In this paper, we utilize information-theoretic metrics like matrix entropy and mutual information to analyze supervised learning. We explore the information content of data representations and classification head weights and their information interplay during supervised training. Experiments show that matrix entropy cannot solely describe the interaction of the information content of data representation and classification head weights but it can effectively reflect the similarity and clustering behavior of the data. Inspired by this, we propose a cross-modal alignment loss to improve the alignment between the representations of the same class from different modalities. Moreover, in order to assess the interaction of the information content of data representation and classification head weights more accurately, we utilize new metrics like matrix mutual information ratio (MIR) and matrix information entropy difference ratio (HDR). Through theory and experiment, we show that HDR and MIR can not only effectively describe the information interplay of supervised training but also improve the performance of supervised and semi-supervised learning.
P2 Explore: Efficient Exploration in Unknown Clustered Environment with Floor Plan Prediction
Sep 17, 2024



Robot exploration aims at constructing unknown environments and it is important to achieve it with shorter paths. Traditional methods focus on optimizing the visiting order based on current observations, which may lead to local-minimal results. Recently, by predicting the structure of the unseen environment, the exploration efficiency can be further improved. However, in a cluttered environment, due to the randomness of obstacles, the ability for prediction is limited. Therefore, to solve this problem, we propose a map prediction algorithm that can be efficient in predicting the layout of noisy indoor environments. We focus on the scenario of 2D exploration. First, we perform floor plan extraction by denoising the cluttered map using deep learning. Then, we use a floor plan-based algorithm to improve the prediction accuracy. Additionally, we extract the segmentation of rooms and construct their connectivity based on the predicted map, which can be used for downstream tasks. To validate the effectiveness of the proposed method, it is applied to exploration tasks. Extensive experiments show that even in cluttered scenes, our proposed method can benefit efficiency.
Restoring Real-World Degraded Events Improves Deblurring Quality
Jul 30, 2024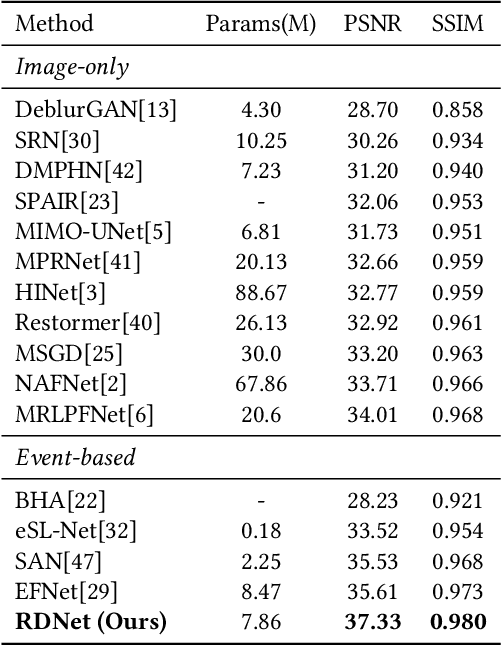
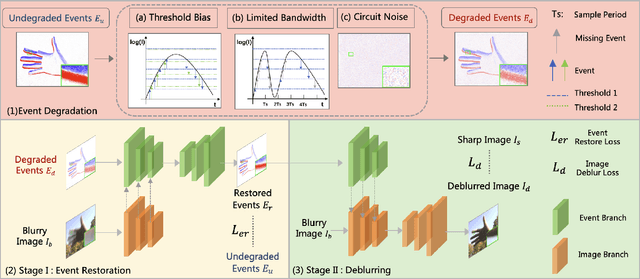
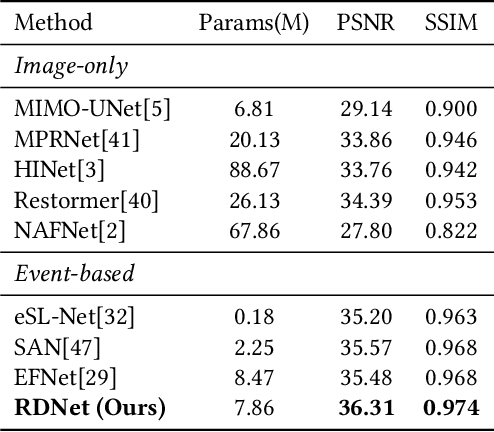
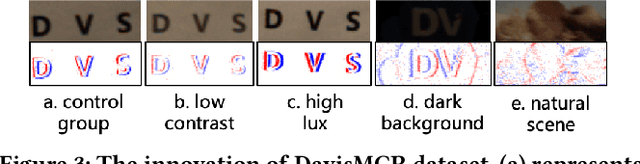
Due to its high speed and low latency, DVS is frequently employed in motion deblurring. Ideally, high-quality events would adeptly capture intricate motion information. However, real-world events are generally degraded, thereby introducing significant artifacts into the deblurred results. In response to this challenge, we model the degradation of events and propose RDNet to improve the quality of image deblurring. Specifically, we first analyze the mechanisms underlying degradation and simulate paired events based on that. These paired events are then fed into the first stage of the RDNet for training the restoration model. The events restored in this stage serve as a guide for the second-stage deblurring process. To better assess the deblurring performance of different methods on real-world degraded events, we present a new real-world dataset named DavisMCR. This dataset incorporates events with diverse degradation levels, collected by manipulating environmental brightness and target object contrast. Our experiments are conducted on synthetic datasets (GOPRO), real-world datasets (REBlur), and the proposed dataset (DavisMCR). The results demonstrate that RDNet outperforms classical event denoising methods in event restoration. Furthermore, RDNet exhibits better performance in deblurring tasks compared to state-of-the-art methods. DavisMCR are available at https://github.com/Yeeesir/DVS_RDNet.
WenetSpeech4TTS: A 12,800-hour Mandarin TTS Corpus for Large Speech Generation Model Benchmark
Jun 11, 2024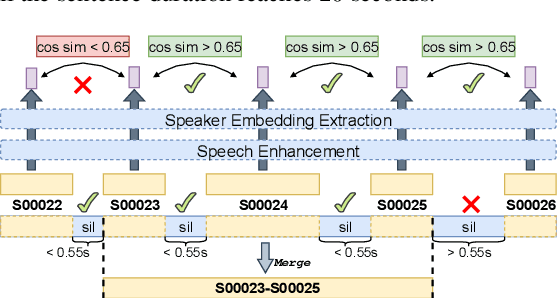
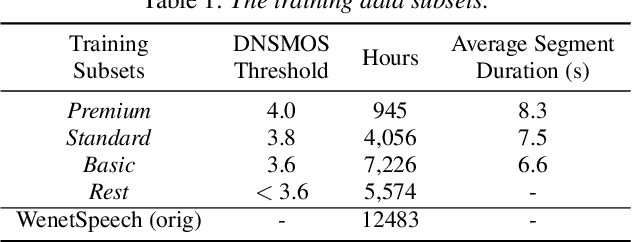
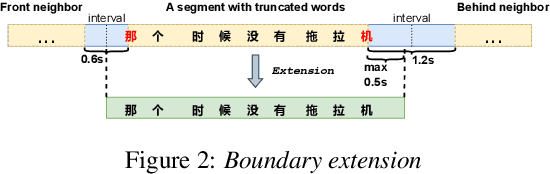
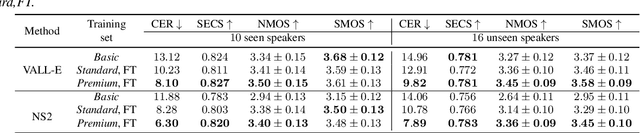
With the development of large text-to-speech (TTS) models and scale-up of the training data, state-of-the-art TTS systems have achieved impressive performance. In this paper, we present WenetSpeech4TTS, a multi-domain Mandarin corpus derived from the open-sourced WenetSpeech dataset. Tailored for the text-to-speech tasks, we refined WenetSpeech by adjusting segment boundaries, enhancing the audio quality, and eliminating speaker mixing within each segment. Following a more accurate transcription process and quality-based data filtering process, the obtained WenetSpeech4TTS corpus contains $12,800$ hours of paired audio-text data. Furthermore, we have created subsets of varying sizes, categorized by segment quality scores to allow for TTS model training and fine-tuning. VALL-E and NaturalSpeech 2 systems are trained and fine-tuned on these subsets to validate the usability of WenetSpeech4TTS, establishing baselines on benchmark for fair comparison of TTS systems. The corpus and corresponding benchmarks are publicly available on huggingface.
Distributed Motion Control of Multiple Mobile Manipulator System with Disturbance and Communication Delay
Jun 09, 2024



In real-world object manipulation scenarios, multiple mobile manipulator systems may suffer from disturbances and asynchrony, leading to excessive interaction forces and causing object damage or emergency stops. This paper presents a novel distributed motion control approach aimed at reducing these unnecessary interaction forces. The control strategy only utilizes force information without the need for global position and velocity information. Disturbances are corrected through compensatory movements of the manipulators. Besides, the asymmetric, non-uniform, and time-varying communication delays between robots are also considered. The stability of the control law is rigorously proven by the Lyapunov theorem. Subsequently, the efficacy of the proposed control law is validated through simulations and experiments of collaborative object transportation by two robots. Experimental results demonstrate the effectiveness of the proposed control law in reducing interaction forces during object manipulation.
Unveiling the Dynamics of Information Interplay in Supervised Learning
Jun 06, 2024In this paper, we use matrix information theory as an analytical tool to analyze the dynamics of the information interplay between data representations and classification head vectors in the supervised learning process. Specifically, inspired by the theory of Neural Collapse, we introduce matrix mutual information ratio (MIR) and matrix entropy difference ratio (HDR) to assess the interactions of data representation and class classification heads in supervised learning, and we determine the theoretical optimal values for MIR and HDR when Neural Collapse happens. Our experiments show that MIR and HDR can effectively explain many phenomena occurring in neural networks, for example, the standard supervised training dynamics, linear mode connectivity, and the performance of label smoothing and pruning. Additionally, we use MIR and HDR to gain insights into the dynamics of grokking, which is an intriguing phenomenon observed in supervised training, where the model demonstrates generalization capabilities long after it has learned to fit the training data. Furthermore, we introduce MIR and HDR as loss terms in supervised and semi-supervised learning to optimize the information interactions among samples and classification heads. The empirical results provide evidence of the method's effectiveness, demonstrating that the utilization of MIR and HDR not only aids in comprehending the dynamics throughout the training process but can also enhances the training procedure itself.
RHAML: Rendezvous-based Hierarchical Architecture for Mutual Localization
May 20, 2024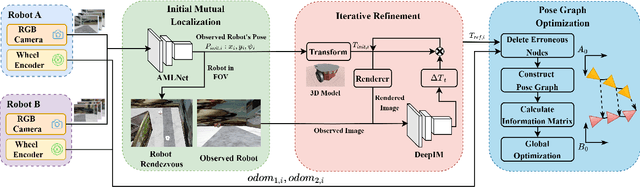
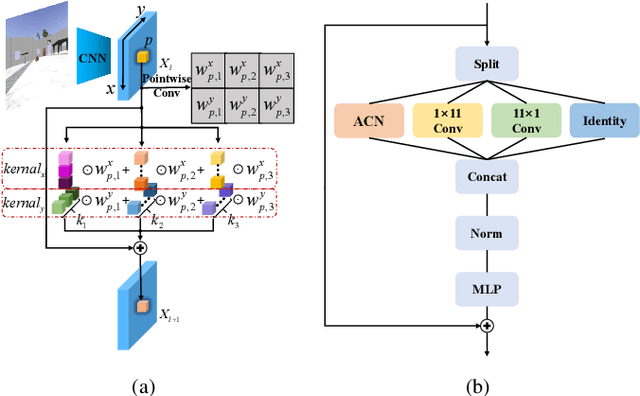


Mutual localization serves as the foundation for collaborative perception and task assignment in multi-robot systems. Effectively utilizing limited onboard sensors for mutual localization between marker-less robots is a worthwhile goal. However, due to inadequate consideration of large scale variations of the observed robot and localization refinement, previous work has shown limited accuracy when robots are equipped only with RGB cameras. To enhance the precision of localization, this paper proposes a novel rendezvous-based hierarchical architecture for mutual localization (RHAML). Firstly, to learn multi-scale robot features, anisotropic convolutions are introduced into the network, yielding initial localization results. Then, the iterative refinement module with rendering is employed to adjust the observed robot poses. Finally, the pose graph is conducted to globally optimize all localization results, which takes into account multi-frame observations. Therefore, a flexible architecture is provided that allows for the selection of appropriate modules based on requirements. Simulations demonstrate that RHAML effectively addresses the problem of multi-robot mutual localization, achieving translation errors below 2 cm and rotation errors below 0.5 degrees when robots exhibit 5 m of depth variation. Moreover, its practical utility is validated by applying it to map fusion when multi-robots explore unknown environments.
Multi-Robot Rendezvous in Unknown Environment with Limited Communication
May 14, 2024



Rendezvous aims at gathering all robots at a specific location, which is an important collaborative behavior for multirobot systems. However, in an unknown environment, it is challenging to achieve rendezvous. Previous researches mainly focus on special scenarios where communication is not allowed and each robot executes a random searching strategy, which is highly time-consuming, especially in large-scale environments. In this work, we focus on rendezvous in unknown environments where communication is available. We divide this task into two steps: rendezvous based environment exploration with relative pose (RP) estimation and rendezvous point election. A new strategy called partitioned and incomplete exploration for rendezvous (PIER) is proposed to efficiently explore the unknown environment, where lightweight topological maps are constructed and shared among robots for RP estimation with very few communications. Then, a rendezvous point selection algorithm based on the merged topological map is proposed for efficient rendezvous for multi-robot systems. The effectiveness of the proposed methods is validated in both simulations and real-world experiments.