 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSNAT-YOLO: Efficient Cross-Layer Aggregation Network for Edge-Oriented Gangue Detection
Feb 09, 2025To address the issues of slow detection speed,low accuracy,difficulty in deployment on industrial edge devices,and large parameter and computational requirements in deep learning-based coal gangue target detection methods,we propose a lightweight coal gangue target detection algorithm based on an improved YOLOv11.First,we use the lightweight network ShuffleNetV2 as the backbone to enhance detection speed.Second,we introduce a lightweight downsampling operation,ADown,which reduces model complexity while improving average detection accuracy.Third,we improve the C2PSA module in YOLOv11 by incorporating the Triplet Attention mechanism,resulting in the proposed C2PSA-TriAtt module,which enhances the model's ability to focus on different dimensions of images.Fourth,we propose the Inner-FocalerIoU loss function to replace the existing CIoU loss function.Experimental results show that our model achieves a detection accuracy of 99.10% in coal gangue detection tasks,reduces the model size by 38%,the number of parameters by 41%,and the computational cost by 40%,while decreasing the average detection time per image by 1 ms.The improved model demonstrates enhanced detection speed and accuracy,making it suitable for deployment on industrial edge mobile devices,thus contributing positively to coal processing and efficient utilization of coal resources.
Restoring Real-World Degraded Events Improves Deblurring Quality
Jul 30, 2024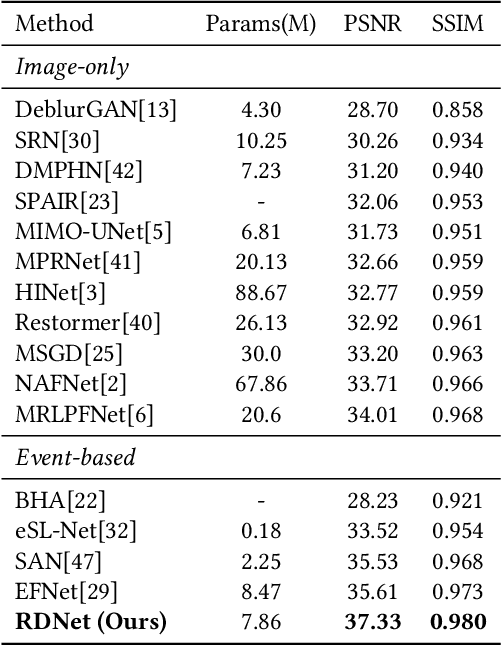
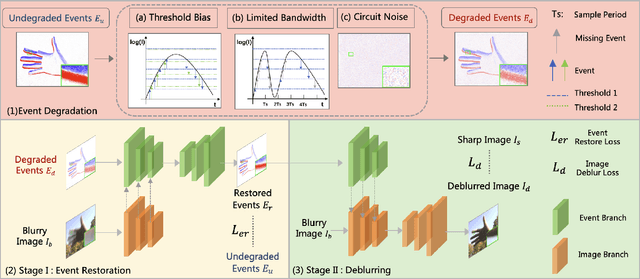
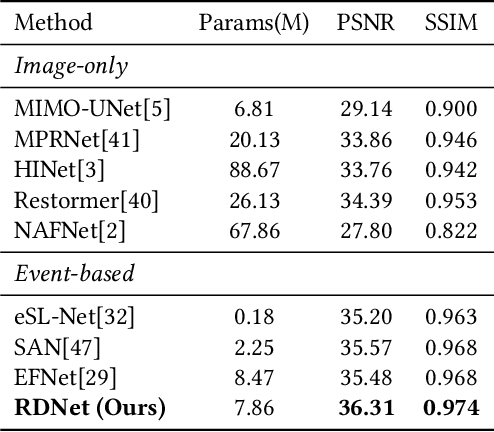
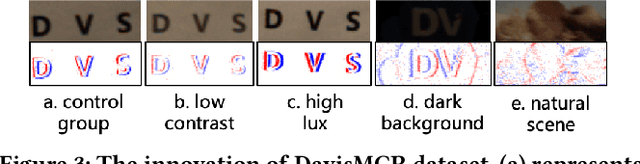
Due to its high speed and low latency, DVS is frequently employed in motion deblurring. Ideally, high-quality events would adeptly capture intricate motion information. However, real-world events are generally degraded, thereby introducing significant artifacts into the deblurred results. In response to this challenge, we model the degradation of events and propose RDNet to improve the quality of image deblurring. Specifically, we first analyze the mechanisms underlying degradation and simulate paired events based on that. These paired events are then fed into the first stage of the RDNet for training the restoration model. The events restored in this stage serve as a guide for the second-stage deblurring process. To better assess the deblurring performance of different methods on real-world degraded events, we present a new real-world dataset named DavisMCR. This dataset incorporates events with diverse degradation levels, collected by manipulating environmental brightness and target object contrast. Our experiments are conducted on synthetic datasets (GOPRO), real-world datasets (REBlur), and the proposed dataset (DavisMCR). The results demonstrate that RDNet outperforms classical event denoising methods in event restoration. Furthermore, RDNet exhibits better performance in deblurring tasks compared to state-of-the-art methods. DavisMCR are available at https://github.com/Yeeesir/DVS_RDNet.
End-to-end Alternating Optimization for Real-World Blind Super Resolution
Aug 17, 2023Blind Super-Resolution (SR) usually involves two sub-problems: 1) estimating the degradation of the given low-resolution (LR) image; 2) super-resolving the LR image to its high-resolution (HR) counterpart. Both problems are ill-posed due to the information loss in the degrading process. Most previous methods try to solve the two problems independently, but often fall into a dilemma: a good super-resolved HR result requires an accurate degradation estimation, which however, is difficult to be obtained without the help of original HR information. To address this issue, instead of considering these two problems independently, we adopt an alternating optimization algorithm, which can estimate the degradation and restore the SR image in a single model. Specifically, we design two convolutional neural modules, namely \textit{Restorer} and \textit{Estimator}. \textit{Restorer} restores the SR image based on the estimated degradation, and \textit{Estimator} estimates the degradation with the help of the restored SR image. We alternate these two modules repeatedly and unfold this process to form an end-to-end trainable network. In this way, both \textit{Restorer} and \textit{Estimator} could get benefited from the intermediate results of each other, and make each sub-problem easier. Moreover, \textit{Restorer} and \textit{Estimator} are optimized in an end-to-end manner, thus they could get more tolerant of the estimation deviations of each other and cooperate better to achieve more robust and accurate final results. Extensive experiments on both synthetic datasets and real-world images show that the proposed method can largely outperform state-of-the-art methods and produce more visually favorable results. The codes are rleased at \url{https://github.com/greatlog/RealDAN.git}.
* Extension of our previous NeurIPS paper. Accepted to IJCV
Learning the Degradation Distribution for Blind Image Super-Resolution
Mar 09, 2022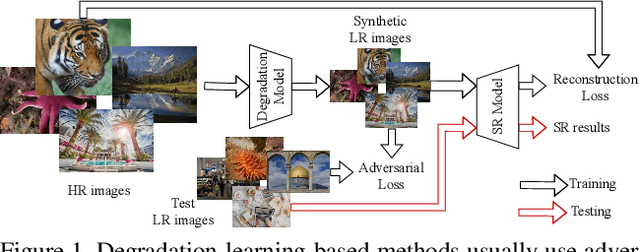
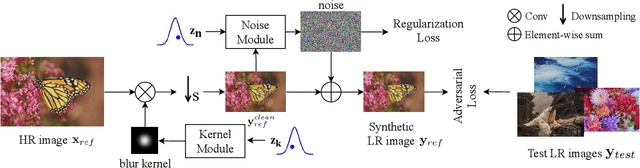
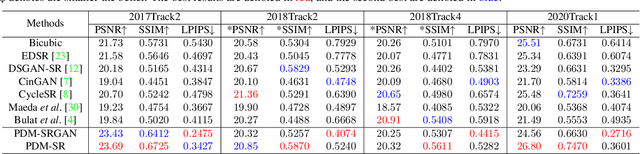
Synthetic high-resolution (HR) \& low-resolution (LR) pairs are widely used in existing super-resolution (SR) methods. To avoid the domain gap between synthetic and test images, most previous methods try to adaptively learn the synthesizing (degrading) process via a deterministic model. However, some degradations in real scenarios are stochastic and cannot be determined by the content of the image. These deterministic models may fail to model the random factors and content-independent parts of degradations, which will limit the performance of the following SR models. In this paper, we propose a probabilistic degradation model (PDM), which studies the degradation $\mathbf{D}$ as a random variable, and learns its distribution by modeling the mapping from a priori random variable $\mathbf{z}$ to $\mathbf{D}$. Compared with previous deterministic degradation models, PDM could model more diverse degradations and generate HR-LR pairs that may better cover the various degradations of test images, and thus prevent the SR model from over-fitting to specific ones. Extensive experiments have demonstrated that our degradation model can help the SR model achieve better performance on different datasets. The source codes are released at \url{git@github.com:greatlog/UnpairedSR.git}.
Approaching the Limit of Image Rescaling via Flow Guidance
Nov 09, 2021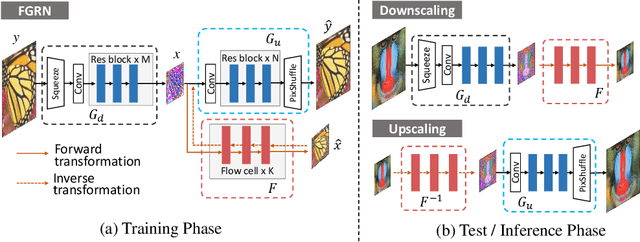
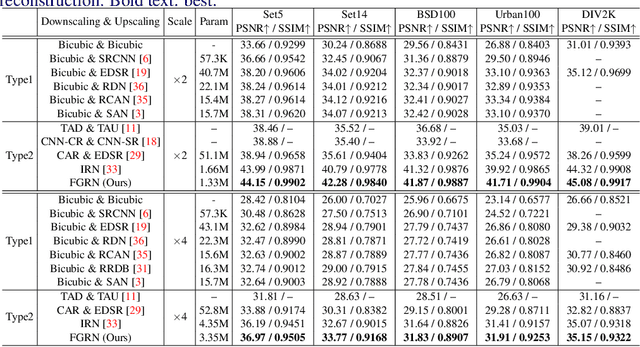
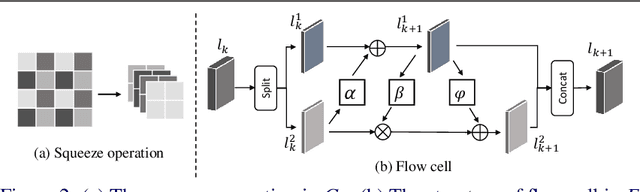
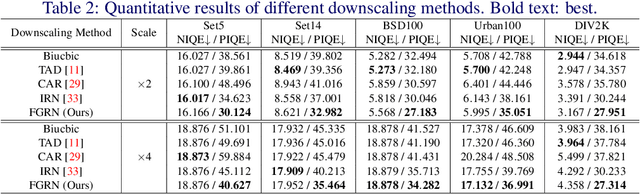
Image downscaling and upscaling are two basic rescaling operations. Once the image is downscaled, it is difficult to be reconstructed via upscaling due to the loss of information. To make these two processes more compatible and improve the reconstruction performance, some efforts model them as a joint encoding-decoding task, with the constraint that the downscaled (i.e. encoded) low-resolution (LR) image must preserve the original visual appearance. To implement this constraint, most methods guide the downscaling module by supervising it with the bicubically downscaled LR version of the original high-resolution (HR) image. However, this bicubic LR guidance may be suboptimal for the subsequent upscaling (i.e. decoding) and restrict the final reconstruction performance. In this paper, instead of directly applying the LR guidance, we propose an additional invertible flow guidance module (FGM), which can transform the downscaled representation to the visually plausible image during downscaling and transform it back during upscaling. Benefiting from the invertibility of FGM, the downscaled representation could get rid of the LR guidance and would not disturb the downscaling-upscaling process. It allows us to remove the restrictions on the downscaling module and optimize the downscaling and upscaling modules in an end-to-end manner. In this way, these two modules could cooperate to maximize the HR reconstruction performance. Extensive experiments demonstrate that the proposed method can achieve state-of-the-art (SotA) performance on both downscaled and reconstructed images.
From General to Specific: Online Updating for Blind Super-Resolution
Jul 06, 2021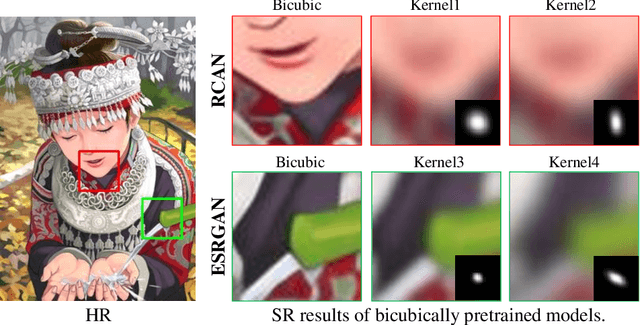
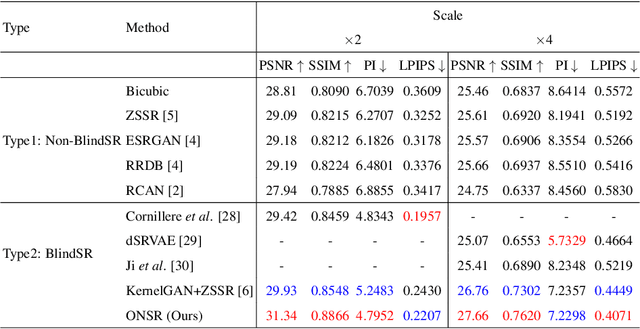
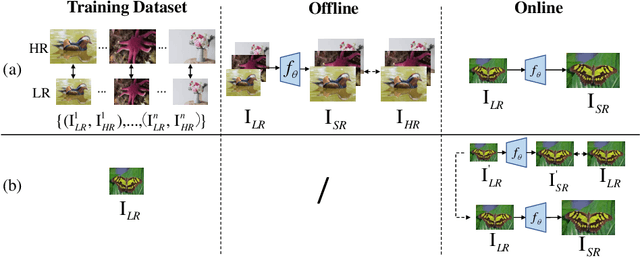
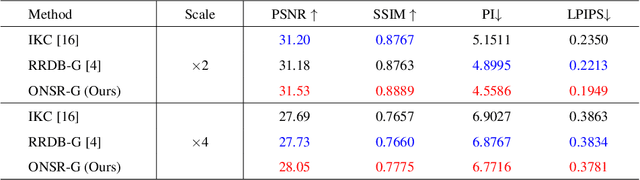
Most deep learning-based super-resolution (SR) methods are not image-specific: 1) They are exhaustively trained on datasets synthesized by predefined blur kernels (\eg bicubic), regardless of the domain gap with test images. 2) Their model weights are fixed during testing, which means that test images with various degradations are super-resolved by the same set of weights. However, degradations of real images are various and unknown (\ie blind SR). It is hard for a single model to perform well in all cases. To address these issues, we propose an online super-resolution (ONSR) method. It does not rely on predefined blur kernels and allows the model weights to be updated according to the degradation of the test image. Specifically, ONSR consists of two branches, namely internal branch (IB) and external branch (EB). IB could learn the specific degradation of the given test LR image, and EB could learn to super resolve images degraded by the learned degradation. In this way, ONSR could customize a specific model for each test image, and thus could be more tolerant with various degradations in real applications. Extensive experiments on both synthesized and real-world images show that ONSR can generate more visually favorable SR results and achieve state-of-the-art performance in blind SR.
End-to-end Alternating Optimization for Blind Super Resolution
May 14, 2021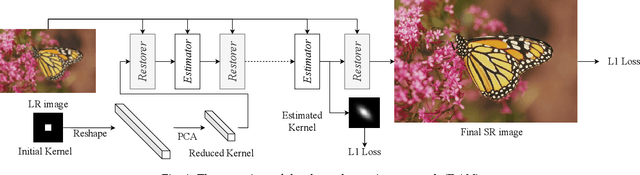
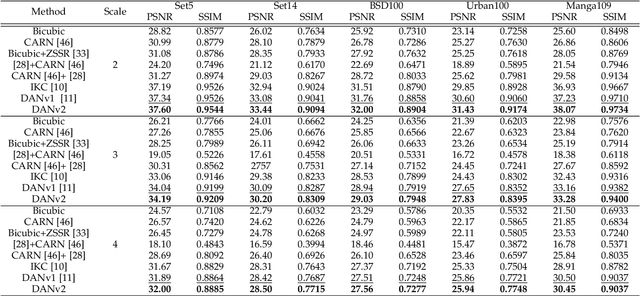
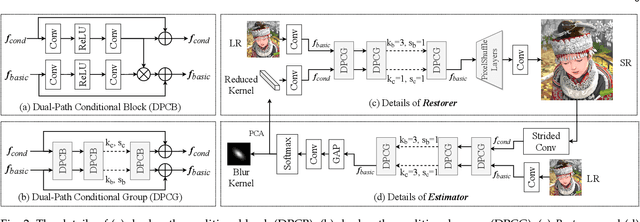

Previous methods decompose the blind super-resolution (SR) problem into two sequential steps: \textit{i}) estimating the blur kernel from given low-resolution (LR) image and \textit{ii}) restoring the SR image based on the estimated kernel. This two-step solution involves two independently trained models, which may not be well compatible with each other. A small estimation error of the first step could cause a severe performance drop of the second one. While on the other hand, the first step can only utilize limited information from the LR image, which makes it difficult to predict a highly accurate blur kernel. Towards these issues, instead of considering these two steps separately, we adopt an alternating optimization algorithm, which can estimate the blur kernel and restore the SR image in a single model. Specifically, we design two convolutional neural modules, namely \textit{Restorer} and \textit{Estimator}. \textit{Restorer} restores the SR image based on the predicted kernel, and \textit{Estimator} estimates the blur kernel with the help of the restored SR image. We alternate these two modules repeatedly and unfold this process to form an end-to-end trainable network. In this way, \textit{Estimator} utilizes information from both LR and SR images, which makes the estimation of the blur kernel easier. More importantly, \textit{Restorer} is trained with the kernel estimated by \textit{Estimator}, instead of the ground-truth kernel, thus \textit{Restorer} could be more tolerant to the estimation error of \textit{Estimator}. Extensive experiments on synthetic datasets and real-world images show that our model can largely outperform state-of-the-art methods and produce more visually favorable results at a much higher speed. The source code is available at \url{https://github.com/greatlog/DAN.git}.
Unfolding the Alternating Optimization for Blind Super Resolution
Oct 16, 2020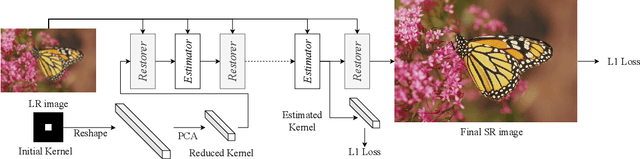
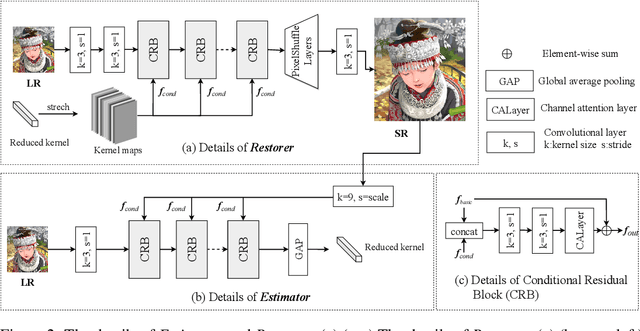
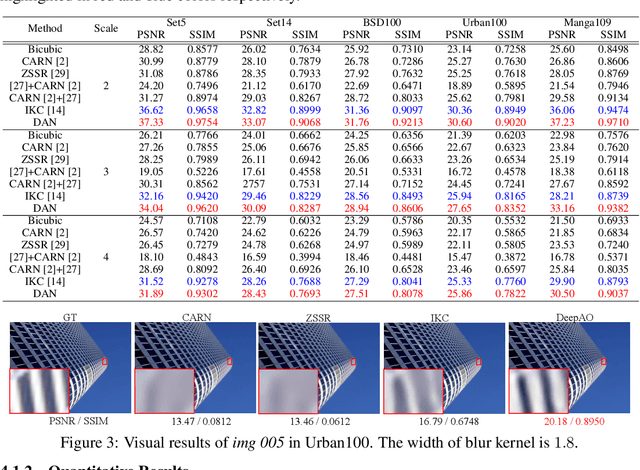

Previous methods decompose blind super resolution (SR) problem into two sequential steps: \textit{i}) estimating blur kernel from given low-resolution (LR) image and \textit{ii}) restoring SR image based on estimated kernel. This two-step solution involves two independently trained models, which may not be well compatible with each other. Small estimation error of the first step could cause severe performance drop of the second one. While on the other hand, the first step can only utilize limited information from LR image, which makes it difficult to predict highly accurate blur kernel. Towards these issues, instead of considering these two steps separately, we adopt an alternating optimization algorithm, which can estimate blur kernel and restore SR image in a single model. Specifically, we design two convolutional neural modules, namely \textit{Restorer} and \textit{Estimator}. \textit{Restorer} restores SR image based on predicted kernel, and \textit{Estimator} estimates blur kernel with the help of restored SR image. We alternate these two modules repeatedly and unfold this process to form an end-to-end trainable network. In this way, \textit{Estimator} utilizes information from both LR and SR images, which makes the estimation of blur kernel easier. More importantly, \textit{Restorer} is trained with the kernel estimated by \textit{Estimator}, instead of ground-truth kernel, thus \textit{Restorer} could be more tolerant to the estimation error of \textit{Estimator}. Extensive experiments on synthetic datasets and real-world images show that our model can largely outperform state-of-the-art methods and produce more visually favorable results at much higher speed. The source code is available at https://github.com/greatlog/DAN.git.