 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMT-Mark: Rethinking Image Watermarking via Mutual-Teacher Collaboration with Adaptive Feature Modulation
Dec 22, 2025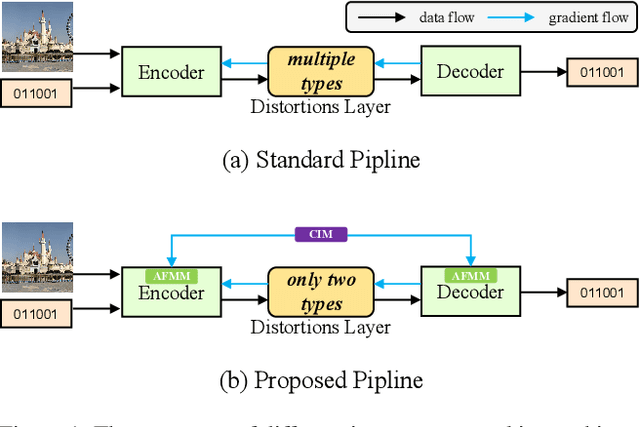
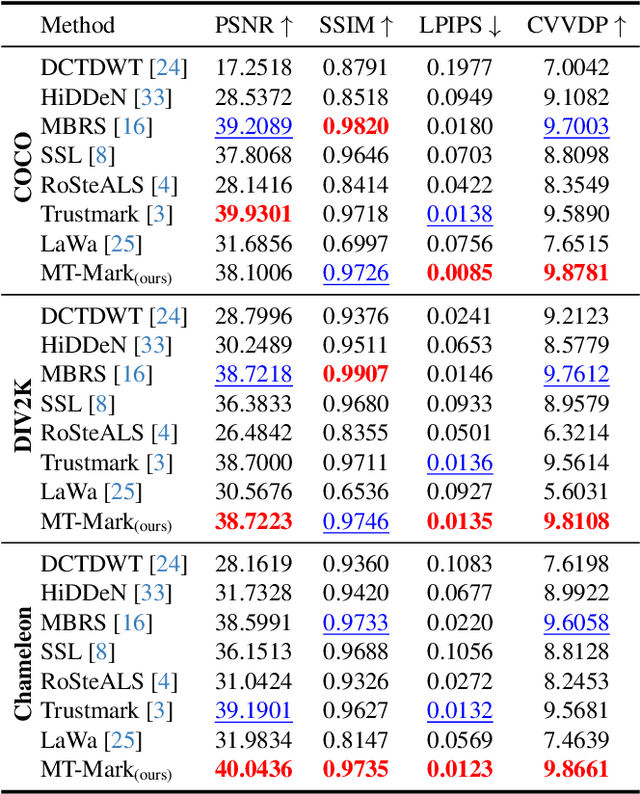
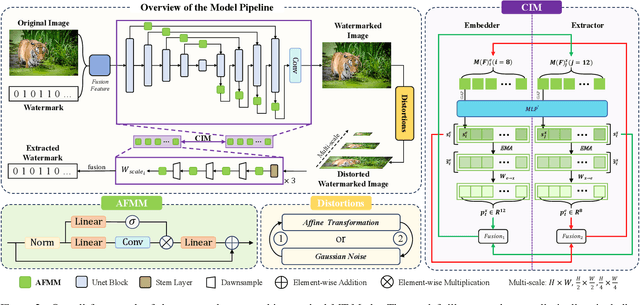
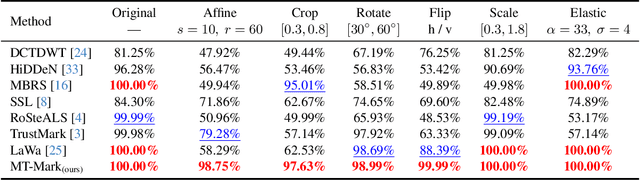
Existing deep image watermarking methods follow a fixed embedding-distortion-extraction pipeline, where the embedder and extractor are weakly coupled through a final loss and optimized in isolation. This design lacks explicit collaboration, leaving no structured mechanism for the embedder to incorporate decoding-aware cues or for the extractor to guide embedding during training. To address this architectural limitation, we rethink deep image watermarking by reformulating embedding and extraction as explicitly collaborative components. To realize this reformulation, we introduce a Collaborative Interaction Mechanism (CIM) that establishes direct, bidirectional communication between the embedder and extractor, enabling a mutual-teacher training paradigm and coordinated optimization. Built upon this explicitly collaborative architecture, we further propose an Adaptive Feature Modulation Module (AFMM) to support effective interaction. AFMM enables content-aware feature regulation by decoupling modulation structure and strength, guiding watermark embedding toward stable image features while suppressing host interference during extraction. Under CIM, the AFMMs on both sides form a closed-loop collaboration that aligns embedding behavior with extraction objectives. This architecture-level redesign changes how robustness is learned in watermarking systems. Rather than relying on exhaustive distortion simulation, robustness emerges from coordinated representation learning between embedding and extraction. Experiments on real-world and AI-generated datasets demonstrate that the proposed method consistently outperforms state-of-the-art approaches in watermark extraction accuracy while maintaining high perceptual quality, showing strong robustness and generalization.
RealityAvatar: Towards Realistic Loose Clothing Modeling in Animatable 3D Gaussian Avatars
Apr 02, 2025
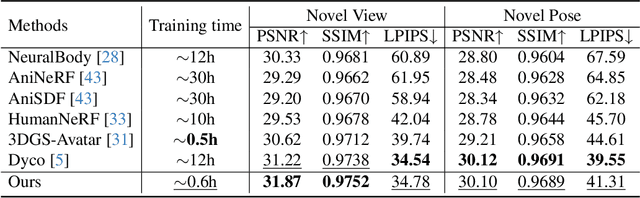

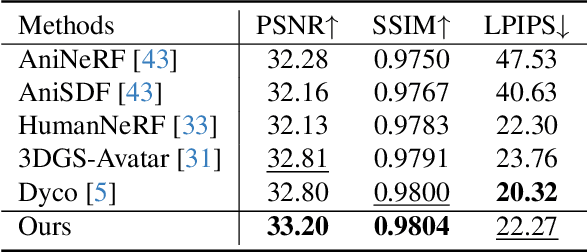
Modeling animatable human avatars from monocular or multi-view videos has been widely studied, with recent approaches leveraging neural radiance fields (NeRFs) or 3D Gaussian Splatting (3DGS) achieving impressive results in novel-view and novel-pose synthesis. However, existing methods often struggle to accurately capture the dynamics of loose clothing, as they primarily rely on global pose conditioning or static per-frame representations, leading to oversmoothing and temporal inconsistencies in non-rigid regions. To address this, We propose RealityAvatar, an efficient framework for high-fidelity digital human modeling, specifically targeting loosely dressed avatars. Our method leverages 3D Gaussian Splatting to capture complex clothing deformations and motion dynamics while ensuring geometric consistency. By incorporating a motion trend module and a latentbone encoder, we explicitly model pose-dependent deformations and temporal variations in clothing behavior. Extensive experiments on benchmark datasets demonstrate the effectiveness of our approach in capturing fine-grained clothing deformations and motion-driven shape variations. Our method significantly enhances structural fidelity and perceptual quality in dynamic human reconstruction, particularly in non-rigid regions, while achieving better consistency across temporal frames.
DiffMAC: Diffusion Manifold Hallucination Correction for High Generalization Blind Face Restoration
Mar 15, 2024Blind face restoration (BFR) is a highly challenging problem due to the uncertainty of degradation patterns. Current methods have low generalization across photorealistic and heterogeneous domains. In this paper, we propose a Diffusion-Information-Diffusion (DID) framework to tackle diffusion manifold hallucination correction (DiffMAC), which achieves high-generalization face restoration in diverse degraded scenes and heterogeneous domains. Specifically, the first diffusion stage aligns the restored face with spatial feature embedding of the low-quality face based on AdaIN, which synthesizes degradation-removal results but with uncontrollable artifacts for some hard cases. Based on Stage I, Stage II considers information compression using manifold information bottleneck (MIB) and finetunes the first diffusion model to improve facial fidelity. DiffMAC effectively fights against blind degradation patterns and synthesizes high-quality faces with attribute and identity consistencies. Experimental results demonstrate the superiority of DiffMAC over state-of-the-art methods, with a high degree of generalization in real-world and heterogeneous settings. The source code and models will be public.
GesGPT: Speech Gesture Synthesis With Text Parsing from GPT
Mar 23, 2023
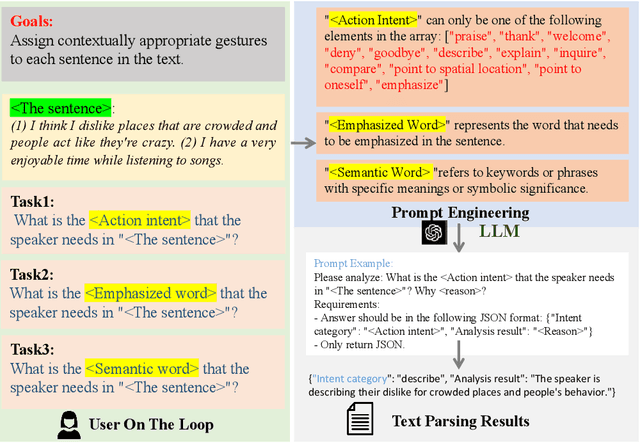


Gesture synthesis has gained significant attention as a critical research area, focusing on producing contextually appropriate and natural gestures corresponding to speech or textual input. Although deep learning-based approaches have achieved remarkable progress, they often overlook the rich semantic information present in the text, leading to less expressive and meaningful gestures. We propose GesGPT, a novel approach to gesture generation that leverages the semantic analysis capabilities of Large Language Models (LLMs), such as GPT. By capitalizing on the strengths of LLMs for text analysis, we design prompts to extract gesture-related information from textual input. Our method entails developing prompt principles that transform gesture generation into an intention classification problem based on GPT, and utilizing a curated gesture library and integration module to produce semantically rich co-speech gestures. Experimental results demonstrate that GesGPT effectively generates contextually appropriate and expressive gestures, offering a new perspective on semantic co-speech gesture generation.
Approaching the Limit of Image Rescaling via Flow Guidance
Nov 09, 2021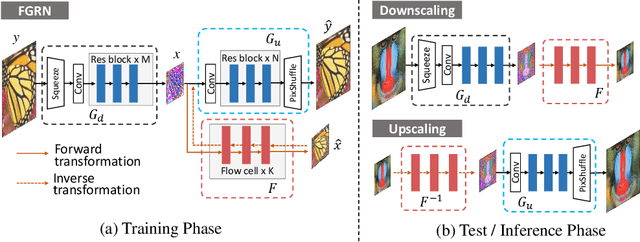
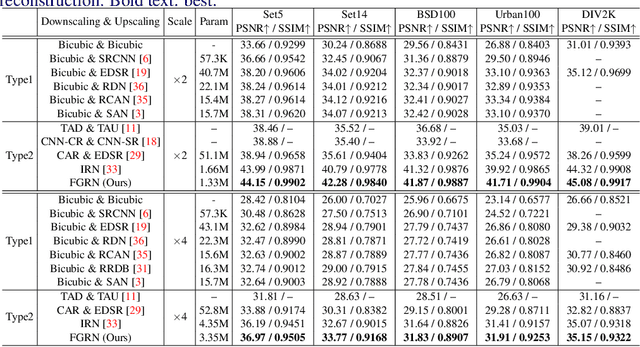
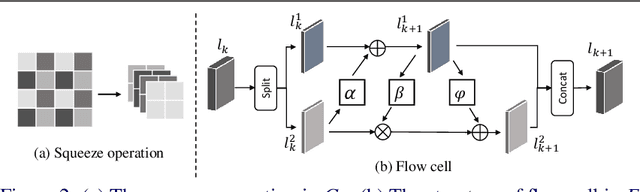
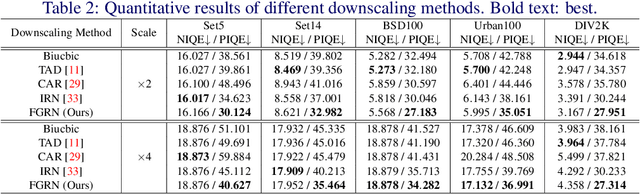
Image downscaling and upscaling are two basic rescaling operations. Once the image is downscaled, it is difficult to be reconstructed via upscaling due to the loss of information. To make these two processes more compatible and improve the reconstruction performance, some efforts model them as a joint encoding-decoding task, with the constraint that the downscaled (i.e. encoded) low-resolution (LR) image must preserve the original visual appearance. To implement this constraint, most methods guide the downscaling module by supervising it with the bicubically downscaled LR version of the original high-resolution (HR) image. However, this bicubic LR guidance may be suboptimal for the subsequent upscaling (i.e. decoding) and restrict the final reconstruction performance. In this paper, instead of directly applying the LR guidance, we propose an additional invertible flow guidance module (FGM), which can transform the downscaled representation to the visually plausible image during downscaling and transform it back during upscaling. Benefiting from the invertibility of FGM, the downscaled representation could get rid of the LR guidance and would not disturb the downscaling-upscaling process. It allows us to remove the restrictions on the downscaling module and optimize the downscaling and upscaling modules in an end-to-end manner. In this way, these two modules could cooperate to maximize the HR reconstruction performance. Extensive experiments demonstrate that the proposed method can achieve state-of-the-art (SotA) performance on both downscaled and reconstructed images.
From General to Specific: Online Updating for Blind Super-Resolution
Jul 06, 2021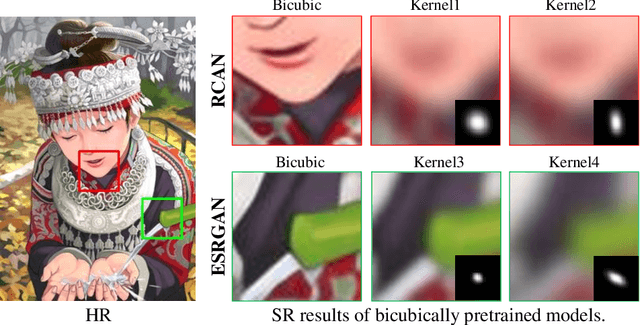
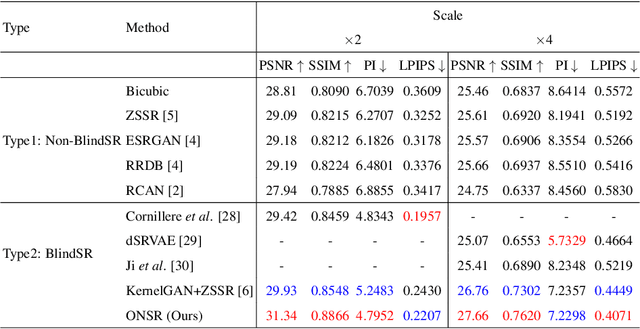
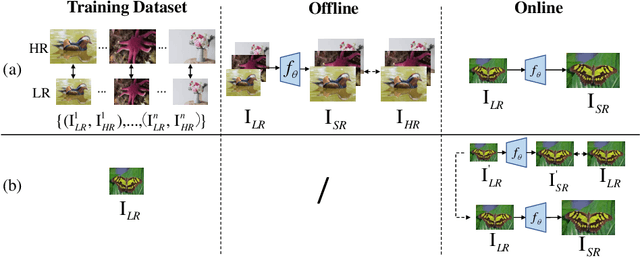
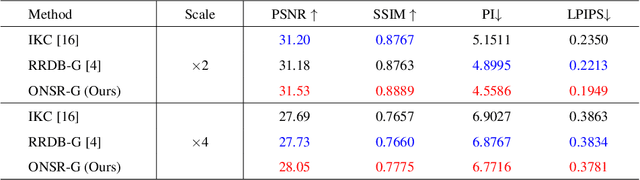
Most deep learning-based super-resolution (SR) methods are not image-specific: 1) They are exhaustively trained on datasets synthesized by predefined blur kernels (\eg bicubic), regardless of the domain gap with test images. 2) Their model weights are fixed during testing, which means that test images with various degradations are super-resolved by the same set of weights. However, degradations of real images are various and unknown (\ie blind SR). It is hard for a single model to perform well in all cases. To address these issues, we propose an online super-resolution (ONSR) method. It does not rely on predefined blur kernels and allows the model weights to be updated according to the degradation of the test image. Specifically, ONSR consists of two branches, namely internal branch (IB) and external branch (EB). IB could learn the specific degradation of the given test LR image, and EB could learn to super resolve images degraded by the learned degradation. In this way, ONSR could customize a specific model for each test image, and thus could be more tolerant with various degradations in real applications. Extensive experiments on both synthesized and real-world images show that ONSR can generate more visually favorable SR results and achieve state-of-the-art performance in blind SR.