 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Reasoning Video Object Segmentation
Apr 13, 2026Reasoning video object segmentation predicts pixel-level masks in videos from natural-language queries that may involve implicit and temporally grounded references. However, existing methods are developed and evaluated in an offline regime, where the entire video is available at inference time and future frames can be exploited for retrospective disambiguation, deviating from real-world deployments that require strictly causal, frame-by-frame decisions. We study Online Reasoning Video Object Segmentation (ORVOS), where models must incrementally interpret queries using only past and current frames without revisiting previous predictions, while handling referent shifts as events unfold. To support evaluation, we introduce ORVOSB, a benchmark with frame-level causal annotations and referent-shift labels, comprising 210 videos, 12,907 annotated frames, and 512 queries across five reasoning categories. We further propose a baseline with continually-updated segmentation prompts and a structured temporal token reservoir for long-horizon reasoning under bounded computation. Experiments show that existing methods struggle under strict causality and referent shifts, while our baseline establishes a strong foundation for future research.
Revisiting Acoustic Similarity in Emotional Speech and Music via Self-Supervised Representations
Sep 26, 2024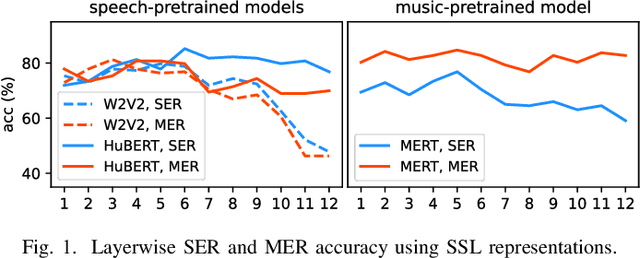
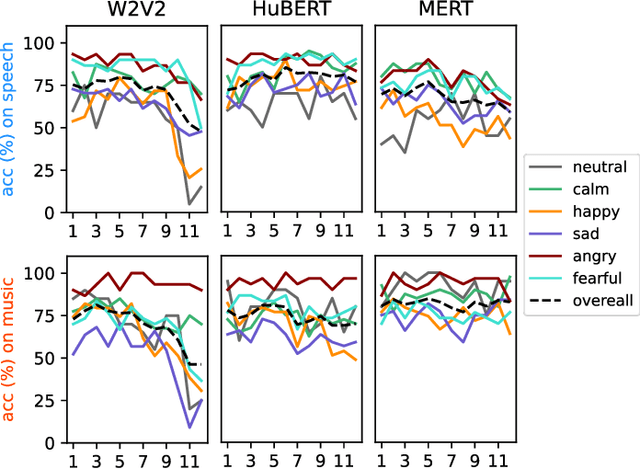
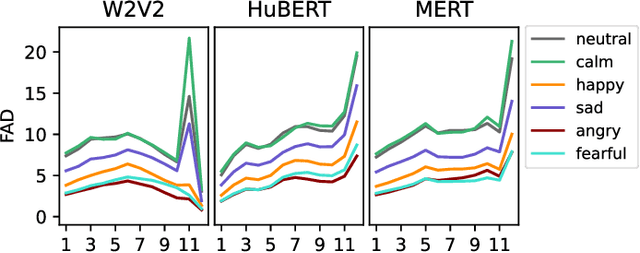

Emotion recognition from speech and music shares similarities due to their acoustic overlap, which has led to interest in transferring knowledge between these domains. However, the shared acoustic cues between speech and music, particularly those encoded by Self-Supervised Learning (SSL) models, remain largely unexplored, given the fact that SSL models for speech and music have rarely been applied in cross-domain research. In this work, we revisit the acoustic similarity between emotion speech and music, starting with an analysis of the layerwise behavior of SSL models for Speech Emotion Recognition (SER) and Music Emotion Recognition (MER). Furthermore, we perform cross-domain adaptation by comparing several approaches in a two-stage fine-tuning process, examining effective ways to utilize music for SER and speech for MER. Lastly, we explore the acoustic similarities between emotional speech and music using Frechet audio distance for individual emotions, uncovering the issue of emotion bias in both speech and music SSL models. Our findings reveal that while speech and music SSL models do capture shared acoustic features, their behaviors can vary depending on different emotions due to their training strategies and domain-specificities. Additionally, parameter-efficient fine-tuning can enhance SER and MER performance by leveraging knowledge from each other. This study provides new insights into the acoustic similarity between emotional speech and music, and highlights the potential for cross-domain generalization to improve SER and MER systems.
Open-Source Conversational AI with SpeechBrain 1.0
Jul 02, 2024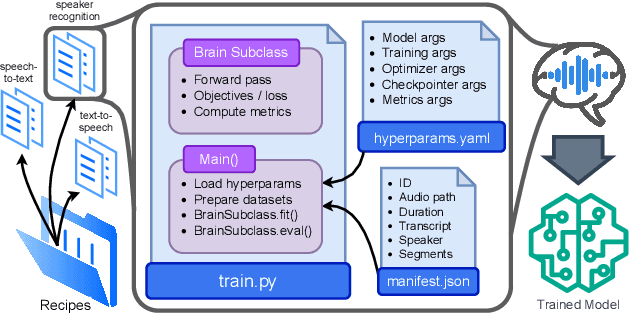

SpeechBrain is an open-source Conversational AI toolkit based on PyTorch, focused particularly on speech processing tasks such as speech recognition, speech enhancement, speaker recognition, text-to-speech, and much more. It promotes transparency and replicability by releasing both the pre-trained models and the complete "recipes" of code and algorithms required for training them. This paper presents SpeechBrain 1.0, a significant milestone in the evolution of the toolkit, which now has over 200 recipes for speech, audio, and language processing tasks, and more than 100 models available on Hugging Face. SpeechBrain 1.0 introduces new technologies to support diverse learning modalities, Large Language Model (LLM) integration, and advanced decoding strategies, along with novel models, tasks, and modalities. It also includes a new benchmark repository, offering researchers a unified platform for evaluating models across diverse tasks
ASR and Emotional Speech: A Word-Level Investigation of the Mutual Impact of Speech and Emotion Recognition
May 25, 2023



In Speech Emotion Recognition (SER), textual data is often used alongside audio signals to address their inherent variability. However, the reliance on human annotated text in most research hinders the development of practical SER systems. To overcome this challenge, we investigate how Automatic Speech Recognition (ASR) performs on emotional speech by analyzing the ASR performance on emotion corpora and examining the distribution of word errors and confidence scores in ASR transcripts to gain insight into how emotion affects ASR. We utilize four ASR systems, namely Kaldi ASR, wav2vec, Conformer, and Whisper, and three corpora: IEMOCAP, MOSI, and MELD to ensure generalizability. Additionally, we conduct text-based SER on ASR transcripts with increasing word error rates to investigate how ASR affects SER. The objective of this study is to uncover the relationship and mutual impact of ASR and SER, in order to facilitate ASR adaptation to emotional speech and the use of SER in real world.
GesGPT: Speech Gesture Synthesis With Text Parsing from GPT
Mar 23, 2023
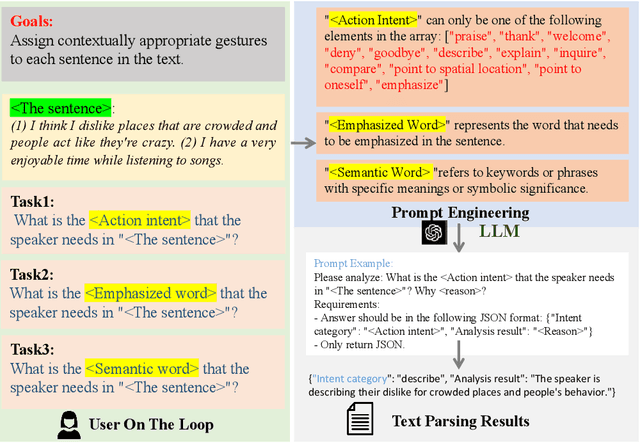


Gesture synthesis has gained significant attention as a critical research area, focusing on producing contextually appropriate and natural gestures corresponding to speech or textual input. Although deep learning-based approaches have achieved remarkable progress, they often overlook the rich semantic information present in the text, leading to less expressive and meaningful gestures. We propose GesGPT, a novel approach to gesture generation that leverages the semantic analysis capabilities of Large Language Models (LLMs), such as GPT. By capitalizing on the strengths of LLMs for text analysis, we design prompts to extract gesture-related information from textual input. Our method entails developing prompt principles that transform gesture generation into an intention classification problem based on GPT, and utilizing a curated gesture library and integration module to produce semantically rich co-speech gestures. Experimental results demonstrate that GesGPT effectively generates contextually appropriate and expressive gestures, offering a new perspective on semantic co-speech gesture generation.
AI-enabled Automatic Multimodal Fusion of Cone-Beam CT and Intraoral Scans for Intelligent 3D Tooth-Bone Reconstruction and Clinical Applications
Mar 11, 2022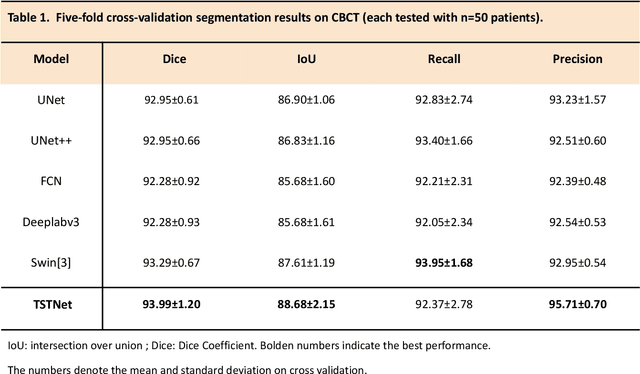
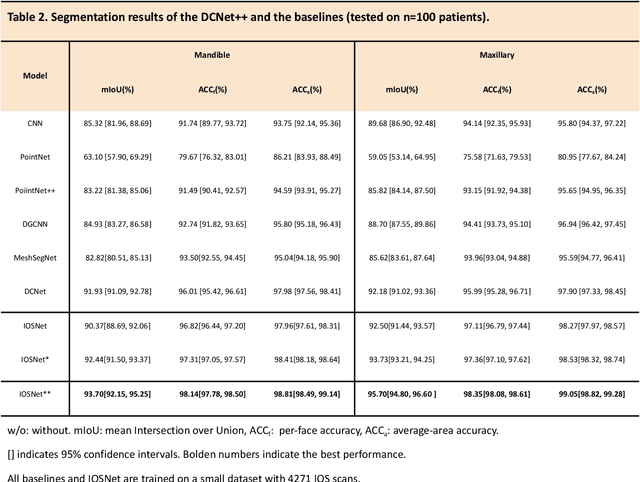

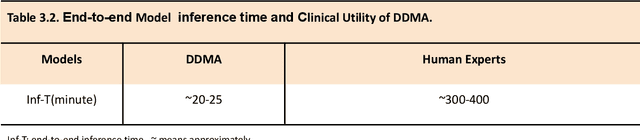
A critical step in virtual dental treatment planning is to accurately delineate all tooth-bone structures from CBCT with high fidelity and accurate anatomical information. Previous studies have established several methods for CBCT segmentation using deep learning. However, the inherent resolution discrepancy of CBCT and the loss of occlusal and dentition information largely limited its clinical applicability. Here, we present a Deep Dental Multimodal Analysis (DDMA) framework consisting of a CBCT segmentation model, an intraoral scan (IOS) segmentation model (the most accurate digital dental model), and a fusion model to generate 3D fused crown-root-bone structures with high fidelity and accurate occlusal and dentition information. Our model was trained with a large-scale dataset with 503 CBCT and 28,559 IOS meshes manually annotated by experienced human experts. For CBCT segmentation, we use a five-fold cross validation test, each with 50 CBCT, and our model achieves an average Dice coefficient and IoU of 93.99% and 88.68%, respectively, significantly outperforming the baselines. For IOS segmentations, our model achieves an mIoU of 93.07% and 95.70% on the maxillary and mandible on a test set of 200 IOS meshes, which are 1.77% and 3.52% higher than the state-of-art method. Our DDMA framework takes about 20 to 25 minutes to generate the fused 3D mesh model following the sequential processing order, compared to over 5 hours by human experts. Notably, our framework has been incorporated into a software by a clear aligner manufacturer, and real-world clinical cases demonstrate that our model can visualize crown-root-bone structures during the entire orthodontic treatment and can predict risks like dehiscence and fenestration. These findings demonstrate the potential of multi-modal deep learning to improve the quality of digital dental models and help dentists make better clinical decisions.