 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Acoustic Similarity in Emotional Speech and Music via Self-Supervised Representations
Paper and Code
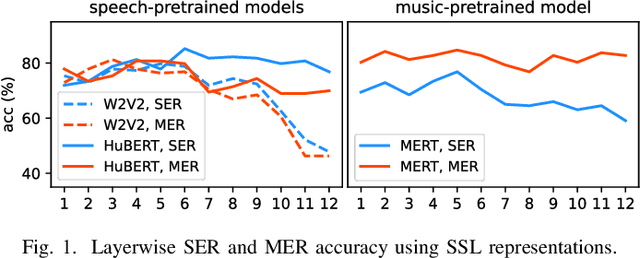
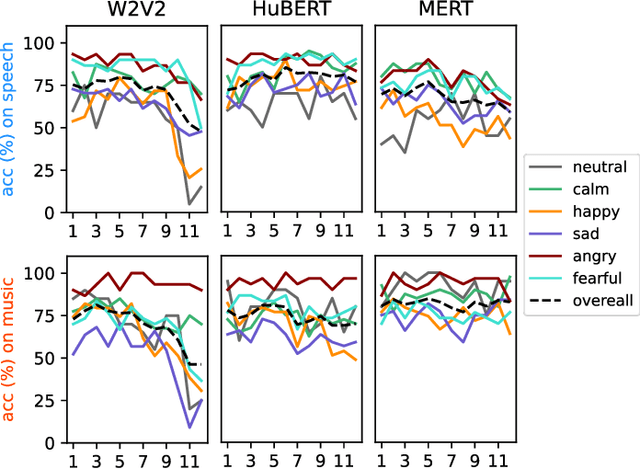
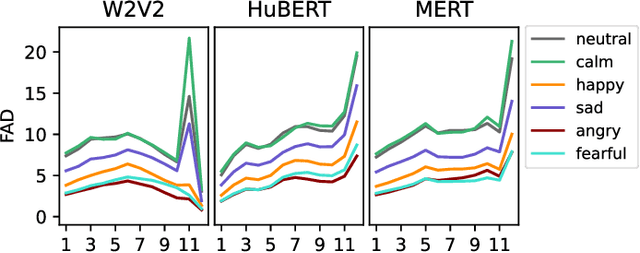

Emotion recognition from speech and music shares similarities due to their acoustic overlap, which has led to interest in transferring knowledge between these domains. However, the shared acoustic cues between speech and music, particularly those encoded by Self-Supervised Learning (SSL) models, remain largely unexplored, given the fact that SSL models for speech and music have rarely been applied in cross-domain research. In this work, we revisit the acoustic similarity between emotion speech and music, starting with an analysis of the layerwise behavior of SSL models for Speech Emotion Recognition (SER) and Music Emotion Recognition (MER). Furthermore, we perform cross-domain adaptation by comparing several approaches in a two-stage fine-tuning process, examining effective ways to utilize music for SER and speech for MER. Lastly, we explore the acoustic similarities between emotional speech and music using Frechet audio distance for individual emotions, uncovering the issue of emotion bias in both speech and music SSL models. Our findings reveal that while speech and music SSL models do capture shared acoustic features, their behaviors can vary depending on different emotions due to their training strategies and domain-specificities. Additionally, parameter-efficient fine-tuning can enhance SER and MER performance by leveraging knowledge from each other. This study provides new insights into the acoustic similarity between emotional speech and music, and highlights the potential for cross-domain generalization to improve SER and MER systems.