 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Video Anomaly Detection from Event Streams: A Baseline and Benchmark Datasets
Mar 26, 2026Event-based vision, characterized by low redundancy, focus on dynamic motion, and inherent privacy-preserving properties, naturally fits the demands of video anomaly detection (VAD). However, the absence of dedicated event-stream anomaly detection datasets and effective modeling strategies has significantly hindered progress in this field. In this work, we take the first major step toward establishing event-based VAD as a unified research direction. We first construct multiple event-stream based benchmarks for video anomaly detection, featuring synchronized event and RGB recordings. Leveraging the unique properties of events, we then propose an EVent-centric spatiotemporal Video Anomaly Detection framework, namely EWAD, with three key innovations: an event density aware dynamic sampling strategy to select temporally informative segments; a density-modulated temporal modeling approach that captures contextual relations from sparse event streams; and an RGB-to-event knowledge distillation mechanism to enhance event-based representations under weak supervision. Extensive experiments on three benchmarks demonstrate that our EWAD achieves significant improvements over existing approaches, highlighting the potential and effectiveness of event-driven modeling for video anomaly detection. The benchmark datasets will be made publicly available.
AVadCLIP: Audio-Visual Collaboration for Robust Video Anomaly Detection
Apr 06, 2025



With the increasing adoption of video anomaly detection in intelligent surveillance domains, conventional visual-based detection approaches often struggle with information insufficiency and high false-positive rates in complex environments. To address these limitations, we present a novel weakly supervised framework that leverages audio-visual collaboration for robust video anomaly detection. Capitalizing on the exceptional cross-modal representation learning capabilities of Contrastive Language-Image Pretraining (CLIP) across visual, audio, and textual domains, our framework introduces two major innovations: an efficient audio-visual fusion that enables adaptive cross-modal integration through lightweight parametric adaptation while maintaining the frozen CLIP backbone, and a novel audio-visual prompt that dynamically enhances text embeddings with key multimodal information based on the semantic correlation between audio-visual features and textual labels, significantly improving CLIP's generalization for the video anomaly detection task. Moreover, to enhance robustness against modality deficiency during inference, we further develop an uncertainty-driven feature distillation module that synthesizes audio-visual representations from visual-only inputs. This module employs uncertainty modeling based on the diversity of audio-visual features to dynamically emphasize challenging features during the distillation process. Our framework demonstrates superior performance across multiple benchmarks, with audio integration significantly boosting anomaly detection accuracy in various scenarios. Notably, with unimodal data enhanced by uncertainty-driven distillation, our approach consistently outperforms current unimodal VAD methods.
Revisiting Acoustic Similarity in Emotional Speech and Music via Self-Supervised Representations
Sep 26, 2024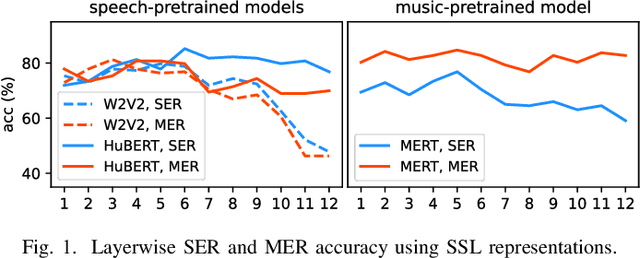
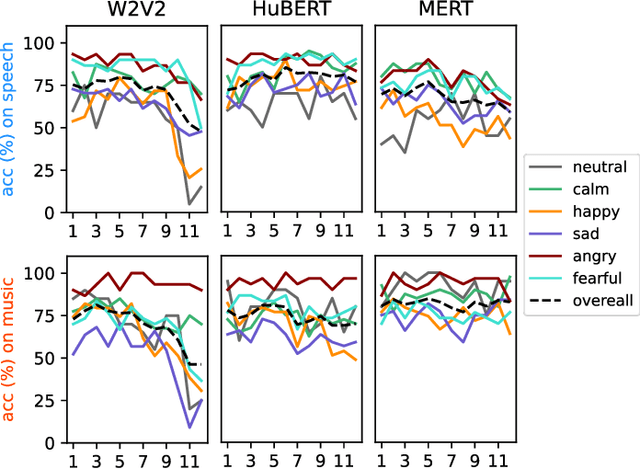
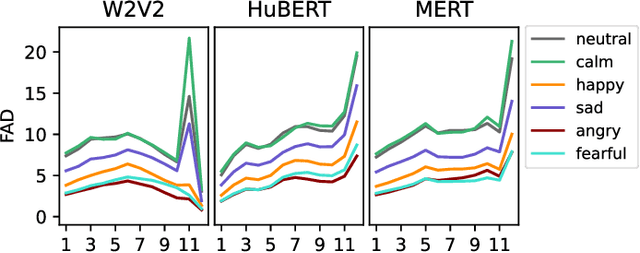

Emotion recognition from speech and music shares similarities due to their acoustic overlap, which has led to interest in transferring knowledge between these domains. However, the shared acoustic cues between speech and music, particularly those encoded by Self-Supervised Learning (SSL) models, remain largely unexplored, given the fact that SSL models for speech and music have rarely been applied in cross-domain research. In this work, we revisit the acoustic similarity between emotion speech and music, starting with an analysis of the layerwise behavior of SSL models for Speech Emotion Recognition (SER) and Music Emotion Recognition (MER). Furthermore, we perform cross-domain adaptation by comparing several approaches in a two-stage fine-tuning process, examining effective ways to utilize music for SER and speech for MER. Lastly, we explore the acoustic similarities between emotional speech and music using Frechet audio distance for individual emotions, uncovering the issue of emotion bias in both speech and music SSL models. Our findings reveal that while speech and music SSL models do capture shared acoustic features, their behaviors can vary depending on different emotions due to their training strategies and domain-specificities. Additionally, parameter-efficient fine-tuning can enhance SER and MER performance by leveraging knowledge from each other. This study provides new insights into the acoustic similarity between emotional speech and music, and highlights the potential for cross-domain generalization to improve SER and MER systems.
Open-Vocabulary Video Anomaly Detection
Nov 15, 2023Video anomaly detection (VAD) with weak supervision has achieved remarkable performance in utilizing video-level labels to discriminate whether a video frame is normal or abnormal. However, current approaches are inherently limited to a closed-set setting and may struggle in open-world applications where there can be anomaly categories in the test data unseen during training. A few recent studies attempt to tackle a more realistic setting, open-set VAD, which aims to detect unseen anomalies given seen anomalies and normal videos. However, such a setting focuses on predicting frame anomaly scores, having no ability to recognize the specific categories of anomalies, despite the fact that this ability is essential for building more informed video surveillance systems. This paper takes a step further and explores open-vocabulary video anomaly detection (OVVAD), in which we aim to leverage pre-trained large models to detect and categorize seen and unseen anomalies. To this end, we propose a model that decouples OVVAD into two mutually complementary tasks -- class-agnostic detection and class-specific classification -- and jointly optimizes both tasks. Particularly, we devise a semantic knowledge injection module to introduce semantic knowledge from large language models for the detection task, and design a novel anomaly synthesis module to generate pseudo unseen anomaly videos with the help of large vision generation models for the classification task. These semantic knowledge and synthesis anomalies substantially extend our model's capability in detecting and categorizing a variety of seen and unseen anomalies. Extensive experiments on three widely-used benchmarks demonstrate our model achieves state-of-the-art performance on OVVAD task.
Boundary-Guided Camouflaged Object Detection
Jul 02, 2022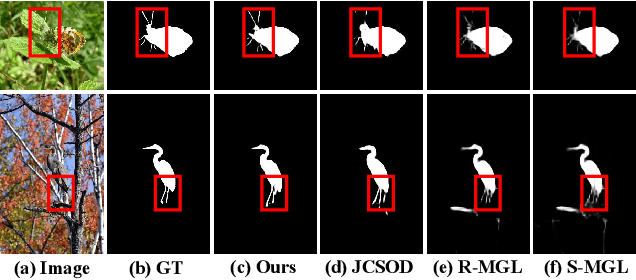
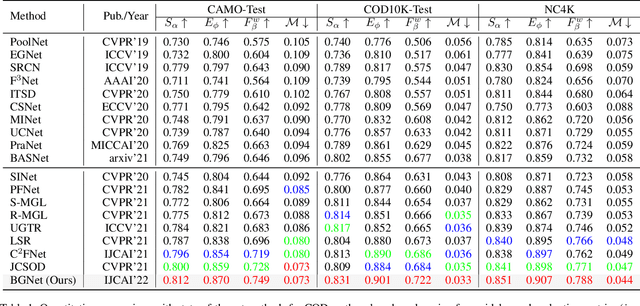
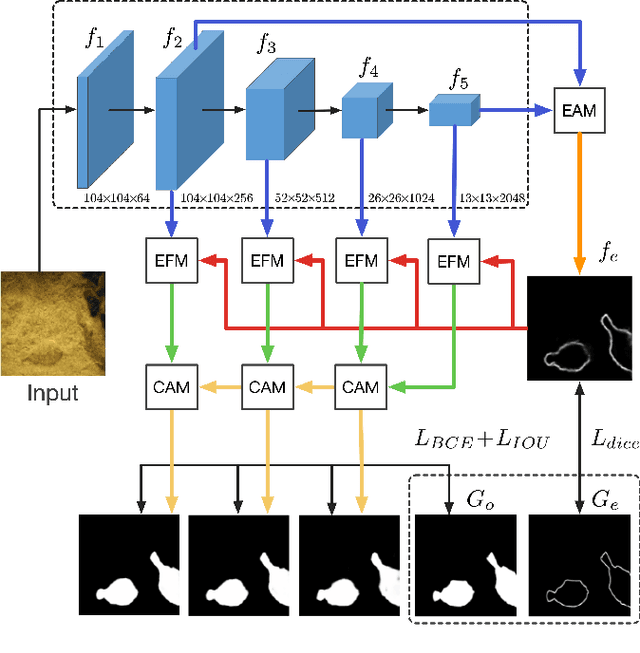

Camouflaged object detection (COD), segmenting objects that are elegantly blended into their surroundings, is a valuable yet challenging task. Existing deep-learning methods often fall into the difficulty of accurately identifying the camouflaged object with complete and fine object structure. To this end, in this paper, we propose a novel boundary-guided network (BGNet) for camouflaged object detection. Our method explores valuable and extra object-related edge semantics to guide representation learning of COD, which forces the model to generate features that highlight object structure, thereby promoting camouflaged object detection of accurate boundary localization. Extensive experiments on three challenging benchmark datasets demonstrate that our BGNet significantly outperforms the existing 18 state-of-the-art methods under four widely-used evaluation metrics. Our code is publicly available at: https://github.com/thograce/BGNet.
* Accepted by IJCAI2022
Context-aware Cross-level Fusion Network for Camouflaged Object Detection
May 26, 2021
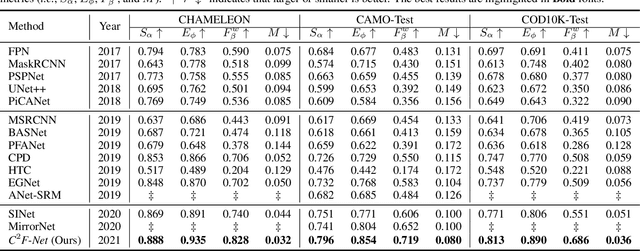
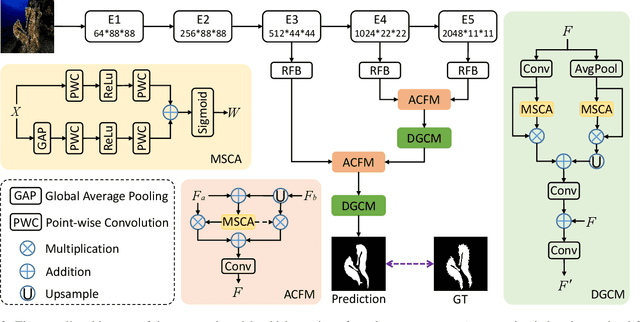

Camouflaged object detection (COD) is a challenging task due to the low boundary contrast between the object and its surroundings. In addition, the appearance of camouflaged objects varies significantly, e.g., object size and shape, aggravating the difficulties of accurate COD. In this paper, we propose a novel Context-aware Cross-level Fusion Network (C2F-Net) to address the challenging COD task. Specifically, we propose an Attention-induced Cross-level Fusion Module (ACFM) to integrate the multi-level features with informative attention coefficients. The fused features are then fed to the proposed Dual-branch Global Context Module (DGCM), which yields multi-scale feature representations for exploiting rich global context information. In C2F-Net, the two modules are conducted on high-level features using a cascaded manner. Extensive experiments on three widely used benchmark datasets demonstrate that our C2F-Net is an effective COD model and outperforms state-of-the-art models remarkably. Our code is publicly available at: https://github.com/thograce/C2FNet.
Learning Synergistic Attention for Light Field Salient Object Detection
May 16, 2021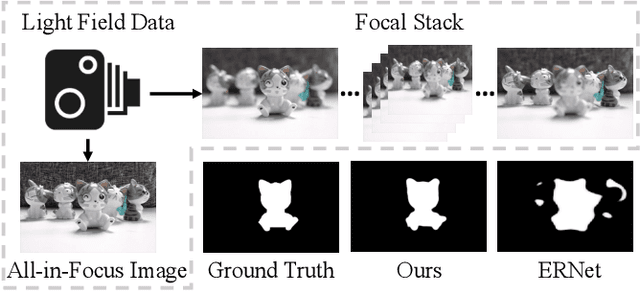
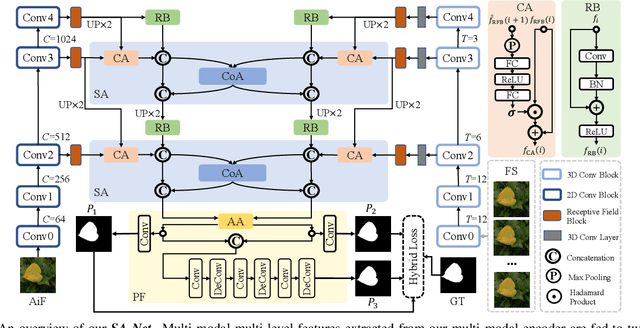
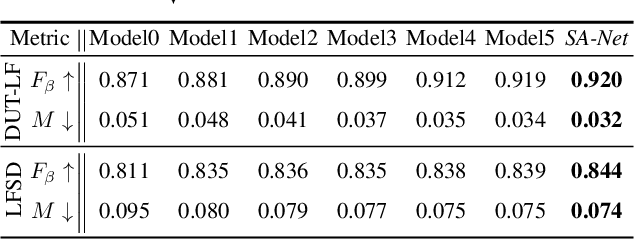
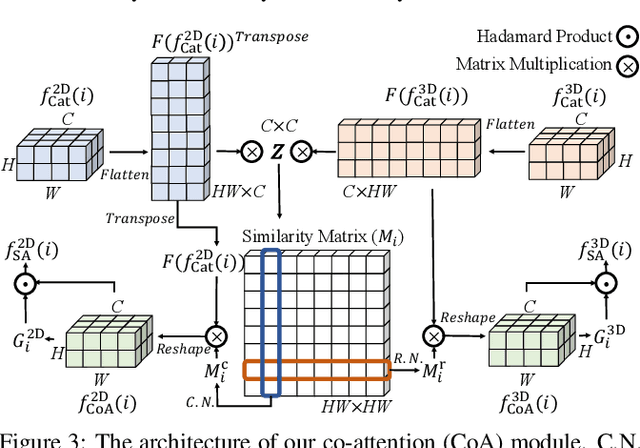
We propose a novel Synergistic Attention Network (SA-Net) to address the light field salient object detection by establishing a synergistic effect between multi-modal features with advanced attention mechanisms. Our SA-Net exploits the rich information of focal stacks via 3D convolutional neural networks, decodes the high-level features of multi-modal light field data with two cascaded synergistic attention modules, and predicts the saliency map using an effective feature fusion module in a progressive manner. Extensive experiments on three widely-used benchmark datasets show that our SA-Net outperforms 28 state-of-the-art models, sufficiently demonstrating its effectiveness and superiority. Our code will be made publicly available.
Not only Look, but also Listen: Learning Multimodal Violence Detection under Weak Supervision
Jul 13, 2020
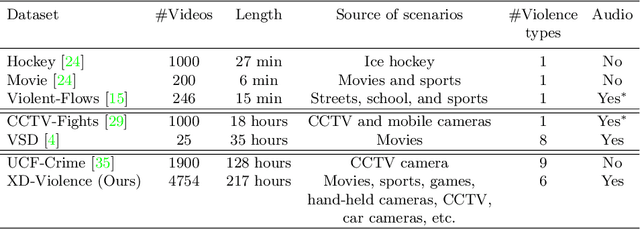
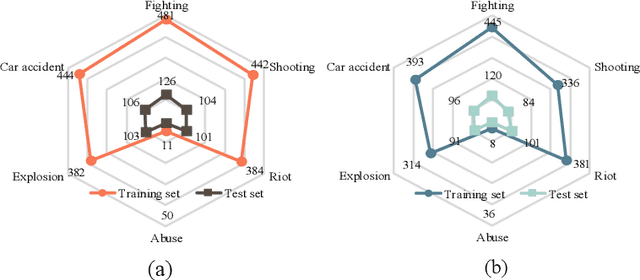
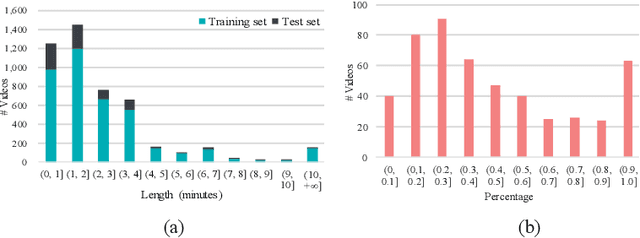
Violence detection has been studied in computer vision for years. However, previous work are either superficial, e.g., classification of short-clips, and the single scenario, or undersupplied, e.g., the single modality, and hand-crafted features based multimodality. To address this problem, in this work we first release a large-scale and multi-scene dataset named XD-Violence with a total duration of 217 hours, containing 4754 untrimmed videos with audio signals and weak labels. Then we propose a neural network containing three parallel branches to capture different relations among video snippets and integrate features, where holistic branch captures long-range dependencies using similarity prior, localized branch captures local positional relation using proximity prior, and score branch dynamically captures the closeness of predicted score. Besides, our method also includes an approximator to meet the needs of online detection. Our method outperforms other state-of-the-art methods on our released dataset and other existing benchmark. Moreover, extensive experimental results also show the positive effect of multimodal (audio-visual) input and modeling relationships. The code and dataset will be released in https://roc-ng.github.io/XD-Violence/.