 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLSG: Industrial Image Anomaly Detection by Learning Better Feature Embeddings and One-Class Classification
Apr 30, 2023Industrial image anomaly detection under the setting of one-class classification has significant practical value. However, most existing models struggle to extract separable feature representations when performing feature embedding and struggle to build compact descriptions of normal features when performing one-class classification. One direct consequence of this is that most models perform poorly in detecting logical anomalies which violate contextual relationships. Focusing on more effective and comprehensive anomaly detection, we propose a network based on self-supervised learning and self-attentive graph convolution (SLSG) for anomaly detection. SLSG uses a generative pre-training network to assist the encoder in learning the embedding of normal patterns and the reasoning of position relationships. Subsequently, SLSG introduces the pseudo-prior knowledge of anomaly through simulated abnormal samples. By comparing the simulated anomalies, SLSG can better summarize the normal features and narrow down the hypersphere used for one-class classification. In addition, with the construction of a more general graph structure, SLSG comprehensively models the dense and sparse relationships among elements in the image, which further strengthens the detection of logical anomalies. Extensive experiments on benchmark datasets show that SLSG achieves superior anomaly detection performance, demonstrating the effectiveness of our method.
Video Event Restoration Based on Keyframes for Video Anomaly Detection
Apr 11, 2023Video anomaly detection (VAD) is a significant computer vision problem. Existing deep neural network (DNN) based VAD methods mostly follow the route of frame reconstruction or frame prediction. However, the lack of mining and learning of higher-level visual features and temporal context relationships in videos limits the further performance of these two approaches. Inspired by video codec theory, we introduce a brand-new VAD paradigm to break through these limitations: First, we propose a new task of video event restoration based on keyframes. Encouraging DNN to infer missing multiple frames based on video keyframes so as to restore a video event, which can more effectively motivate DNN to mine and learn potential higher-level visual features and comprehensive temporal context relationships in the video. To this end, we propose a novel U-shaped Swin Transformer Network with Dual Skip Connections (USTN-DSC) for video event restoration, where a cross-attention and a temporal upsampling residual skip connection are introduced to further assist in restoring complex static and dynamic motion object features in the video. In addition, we propose a simple and effective adjacent frame difference loss to constrain the motion consistency of the video sequence. Extensive experiments on benchmarks demonstrate that USTN-DSC outperforms most existing methods, validating the effectiveness of our method.
Multi View Spatial-Temporal Model for Travel Time Estimation
Sep 30, 2021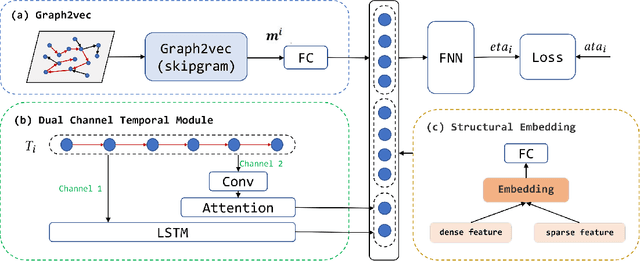
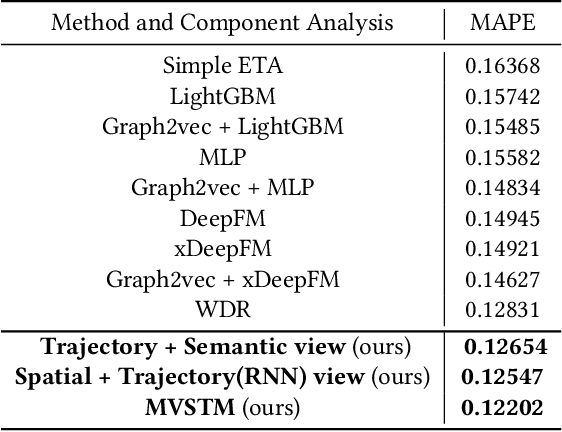

Taxi arrival time prediction is essential for building intelligent transportation systems. Traditional prediction methods mainly rely on extracting features from traffic maps, which cannot model complex situations and nonlinear spatial and temporal relationships. Therefore, we propose Multi-View Spatial-Temporal Model (MVSTM) to capture the mutual dependence of spatial-temporal relations and trajectory features. Specifically, we use graph2vec to model the spatial view, dual-channel temporal module to model the trajectory view, and structural embedding to model traffic semantics. Experiments on large-scale taxi trajectory data have shown that our approach is more effective than the existing novel methods. The source code can be found at https://github.com/775269512/SIGSPATIAL-2021-GISCUP-4th-Solution.
Not only Look, but also Listen: Learning Multimodal Violence Detection under Weak Supervision
Jul 13, 2020
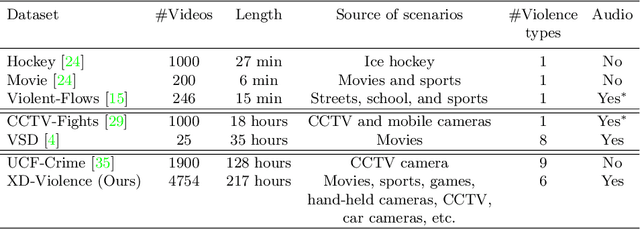
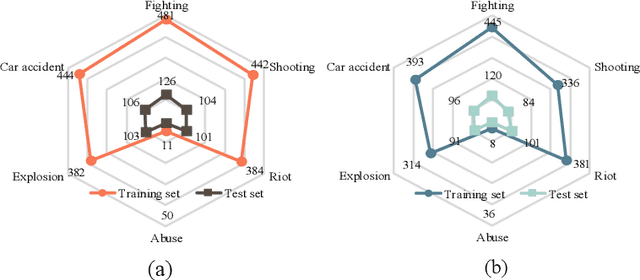
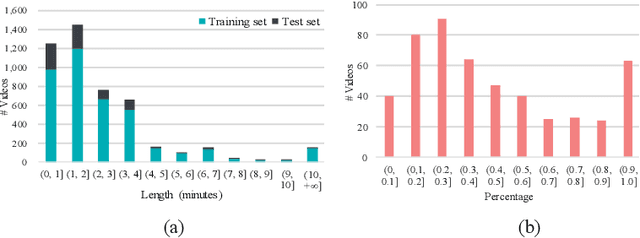
Violence detection has been studied in computer vision for years. However, previous work are either superficial, e.g., classification of short-clips, and the single scenario, or undersupplied, e.g., the single modality, and hand-crafted features based multimodality. To address this problem, in this work we first release a large-scale and multi-scene dataset named XD-Violence with a total duration of 217 hours, containing 4754 untrimmed videos with audio signals and weak labels. Then we propose a neural network containing three parallel branches to capture different relations among video snippets and integrate features, where holistic branch captures long-range dependencies using similarity prior, localized branch captures local positional relation using proximity prior, and score branch dynamically captures the closeness of predicted score. Besides, our method also includes an approximator to meet the needs of online detection. Our method outperforms other state-of-the-art methods on our released dataset and other existing benchmark. Moreover, extensive experimental results also show the positive effect of multimodal (audio-visual) input and modeling relationships. The code and dataset will be released in https://roc-ng.github.io/XD-Violence/.