 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning More with Less: A Dynamic Dual-Level Down-Sampling Framework for Efficient Policy Optimization
Sep 26, 2025Critic-free methods like GRPO reduce memory demands by estimating advantages from multiple rollouts but tend to converge slowly, as critical learning signals are diluted by an abundance of uninformative samples and tokens. To tackle this challenge, we propose the \textbf{Dynamic Dual-Level Down-Sampling (D$^3$S)} framework that prioritizes the most informative samples and tokens across groups to improve the efficient of policy optimization. D$^3$S operates along two levels: (1) the sample-level, which selects a subset of rollouts to maximize advantage variance ($\text{Var}(A)$). We theoretically proven that this selection is positively correlated with the upper bound of the policy gradient norms, yielding higher policy gradients. (2) the token-level, which prioritizes tokens with a high product of advantage magnitude and policy entropy ($|A_{i,t}|\times H_{i,t}$), focusing updates on tokens where the policy is both uncertain and impactful. Moreover, to prevent overfitting to high-signal data, D$^3$S employs a dynamic down-sampling schedule inspired by curriculum learning. This schedule starts with aggressive down-sampling to accelerate early learning and gradually relaxes to promote robust generalization. Extensive experiments on Qwen2.5 and Llama3.1 demonstrate that integrating D$^3$S into advanced RL algorithms achieves state-of-the-art performance and generalization while requiring \textit{fewer} samples and tokens across diverse reasoning benchmarks. Our code is added in the supplementary materials and will be made publicly available.
WeChat-YATT: A Simple, Scalable and Balanced RLHF Trainer
Aug 11, 2025Reinforcement Learning from Human Feedback (RLHF) has emerged as a prominent paradigm for training large language models and multimodal systems. Despite notable advances enabled by existing RLHF training frameworks, significant challenges remain in scaling to complex multimodal workflows and adapting to dynamic workloads. In particular, current systems often encounter limitations related to controller scalability when managing large models, as well as inefficiencies in orchestrating intricate RLHF pipelines, especially in scenarios that require dynamic sampling and resource allocation. In this paper, we introduce WeChat-YATT (Yet Another Transformer Trainer in WeChat), a simple, scalable, and balanced RLHF training framework specifically designed to address these challenges. WeChat-YATT features a parallel controller programming model that enables flexible and efficient orchestration of complex RLHF workflows, effectively mitigating the bottlenecks associated with centralized controller architectures and facilitating scalability in large-scale data scenarios. In addition, we propose a dynamic placement schema that adaptively partitions computational resources and schedules workloads, thereby significantly reducing hardware idle time and improving GPU utilization under variable training conditions. We evaluate WeChat-YATT across a range of experimental scenarios, demonstrating that it achieves substantial improvements in throughput compared to state-of-the-art RLHF training frameworks. Furthermore, WeChat-YATT has been successfully deployed to train models supporting WeChat product features for a large-scale user base, underscoring its effectiveness and robustness in real-world applications.
G-Core: A Simple, Scalable and Balanced RLHF Trainer
Jul 30, 2025Reinforcement Learning from Human Feedback (RLHF) has become an increasingly popular paradigm for training large language models (LLMs) and diffusion models. While existing RLHF training systems have enabled significant progress, they often face challenges in scaling to multi-modal and diffusion workflows and adapting to dynamic workloads. In particular, current approaches may encounter limitations in controller scalability, flexible resource placement, and efficient orchestration when handling complex RLHF pipelines, especially in scenarios involving dynamic sampling or generative reward modeling. In this paper, we present \textbf{G-Core}, a simple, scalable, and balanced RLHF training framework designed to address these challenges. G-Core introduces a parallel controller programming model, enabling flexible and efficient orchestration of complex RLHF workflows without the bottlenecks of a single centralized controller. Furthermore, we propose a dynamic placement schema that adaptively partitions resources and schedules workloads, significantly reducing hardware idle time and improving utilization, even under highly variable training conditions. G-Core has successfully trained models that support WeChat product features serving a large-scale user base, demonstrating its effectiveness and robustness in real-world scenarios. Our results show that G-Core advances the state of the art in RLHF training, providing a solid foundation for future research and deployment of large-scale, human-aligned models.
Cross Fusion RGB-T Tracking with Bi-directional Adapter
Aug 30, 2024



Many state-of-the-art RGB-T trackers have achieved remarkable results through modality fusion. However, these trackers often either overlook temporal information or fail to fully utilize it, resulting in an ineffective balance between multi-modal and temporal information. To address this issue, we propose a novel Cross Fusion RGB-T Tracking architecture (CFBT) that ensures the full participation of multiple modalities in tracking while dynamically fusing temporal information. The effectiveness of CFBT relies on three newly designed cross spatio-temporal information fusion modules: Cross Spatio-Temporal Augmentation Fusion (CSTAF), Cross Spatio-Temporal Complementarity Fusion (CSTCF), and Dual-Stream Spatio-Temporal Adapter (DSTA). CSTAF employs a cross-attention mechanism to enhance the feature representation of the template comprehensively. CSTCF utilizes complementary information between different branches to enhance target features and suppress background features. DSTA adopts the adapter concept to adaptively fuse complementary information from multiple branches within the transformer layer, using the RGB modality as a medium. These ingenious fusions of multiple perspectives introduce only less than 0.3\% of the total modal parameters, but they indeed enable an efficient balance between multi-modal and temporal information. Extensive experiments on three popular RGB-T tracking benchmarks demonstrate that our method achieves new state-of-the-art performance.
Temporal Adaptive RGBT Tracking with Modality Prompt
Jan 02, 2024

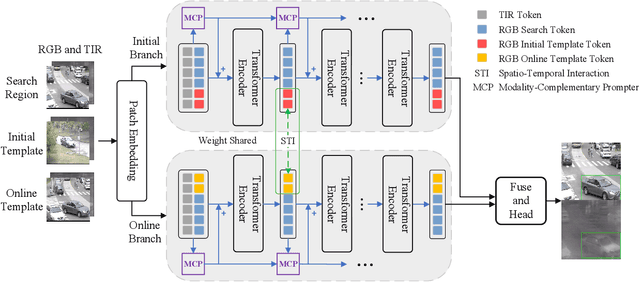

RGBT tracking has been widely used in various fields such as robotics, surveillance processing, and autonomous driving. Existing RGBT trackers fully explore the spatial information between the template and the search region and locate the target based on the appearance matching results. However, these RGBT trackers have very limited exploitation of temporal information, either ignoring temporal information or exploiting it through online sampling and training. The former struggles to cope with the object state changes, while the latter neglects the correlation between spatial and temporal information. To alleviate these limitations, we propose a novel Temporal Adaptive RGBT Tracking framework, named as TATrack. TATrack has a spatio-temporal two-stream structure and captures temporal information by an online updated template, where the two-stream structure refers to the multi-modal feature extraction and cross-modal interaction for the initial template and the online update template respectively. TATrack contributes to comprehensively exploit spatio-temporal information and multi-modal information for target localization. In addition, we design a spatio-temporal interaction (STI) mechanism that bridges two branches and enables cross-modal interaction to span longer time scales. Extensive experiments on three popular RGBT tracking benchmarks show that our method achieves state-of-the-art performance, while running at real-time speed.
Video Event Restoration Based on Keyframes for Video Anomaly Detection
Apr 11, 2023
Video anomaly detection (VAD) is a significant computer vision problem. Existing deep neural network (DNN) based VAD methods mostly follow the route of frame reconstruction or frame prediction. However, the lack of mining and learning of higher-level visual features and temporal context relationships in videos limits the further performance of these two approaches. Inspired by video codec theory, we introduce a brand-new VAD paradigm to break through these limitations: First, we propose a new task of video event restoration based on keyframes. Encouraging DNN to infer missing multiple frames based on video keyframes so as to restore a video event, which can more effectively motivate DNN to mine and learn potential higher-level visual features and comprehensive temporal context relationships in the video. To this end, we propose a novel U-shaped Swin Transformer Network with Dual Skip Connections (USTN-DSC) for video event restoration, where a cross-attention and a temporal upsampling residual skip connection are introduced to further assist in restoring complex static and dynamic motion object features in the video. In addition, we propose a simple and effective adjacent frame difference loss to constrain the motion consistency of the video sequence. Extensive experiments on benchmarks demonstrate that USTN-DSC outperforms most existing methods, validating the effectiveness of our method.
Dynamic Local Aggregation Network with Adaptive Clusterer for Anomaly Detection
Jul 22, 2022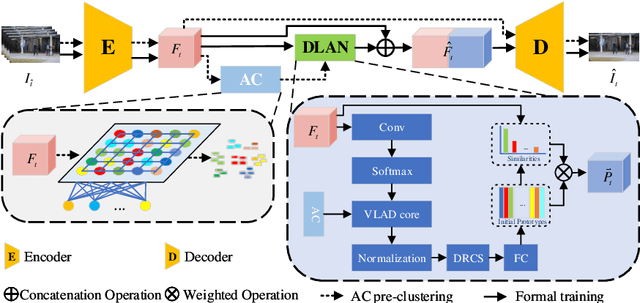
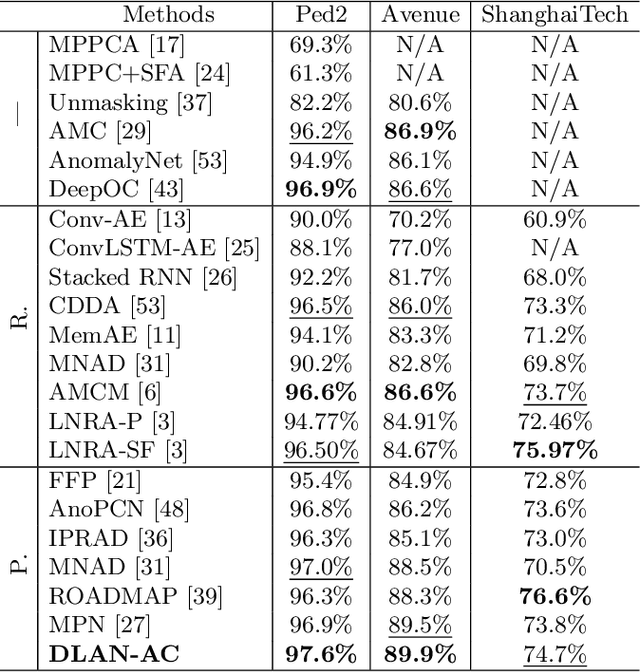


Existing methods for anomaly detection based on memory-augmented autoencoder (AE) have the following drawbacks: (1) Establishing a memory bank requires additional memory space. (2) The fixed number of prototypes from subjective assumptions ignores the data feature differences and diversity. To overcome these drawbacks, we introduce DLAN-AC, a Dynamic Local Aggregation Network with Adaptive Clusterer, for anomaly detection. First, The proposed DLAN can automatically learn and aggregate high-level features from the AE to obtain more representative prototypes, while freeing up extra memory space. Second, The proposed AC can adaptively cluster video data to derive initial prototypes with prior information. In addition, we also propose a dynamic redundant clustering strategy (DRCS) to enable DLAN for automatically eliminating feature clusters that do not contribute to the construction of prototypes. Extensive experiments on benchmarks demonstrate that DLAN-AC outperforms most existing methods, validating the effectiveness of our method. Our code is publicly available at https://github.com/Beyond-Zw/DLAN-AC.
AutoAdversary: A Pixel Pruning Method for Sparse Adversarial Attack
Mar 18, 2022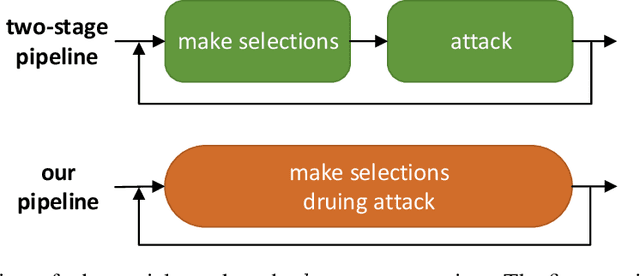
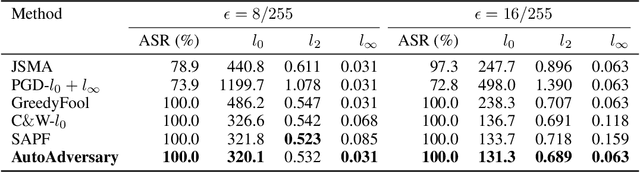

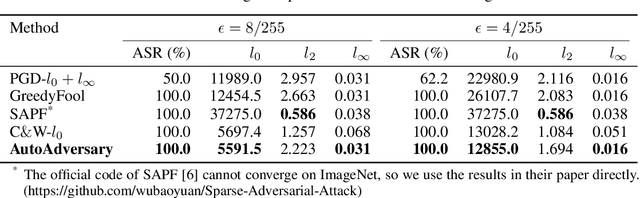
Deep neural networks (DNNs) have been proven to be vulnerable to adversarial examples. A special branch of adversarial examples, namely sparse adversarial examples, can fool the target DNNs by perturbing only a few pixels. However, many existing sparse adversarial attacks use heuristic methods to select the pixels to be perturbed, and regard the pixel selection and the adversarial attack as two separate steps. From the perspective of neural network pruning, we propose a novel end-to-end sparse adversarial attack method, namely AutoAdversary, which can find the most important pixels automatically by integrating the pixel selection into the adversarial attack. Specifically, our method utilizes a trainable neural network to generate a binary mask for the pixel selection. After jointly optimizing the adversarial perturbation and the neural network, only the pixels corresponding to the value 1 in the mask are perturbed. Experiments demonstrate the superiority of our proposed method over several state-of-the-art methods. Furthermore, since AutoAdversary does not require a heuristic pixel selection process, it does not slow down excessively as other methods when the image size increases.
Robust and High Performance Face Detector
Jan 06, 2019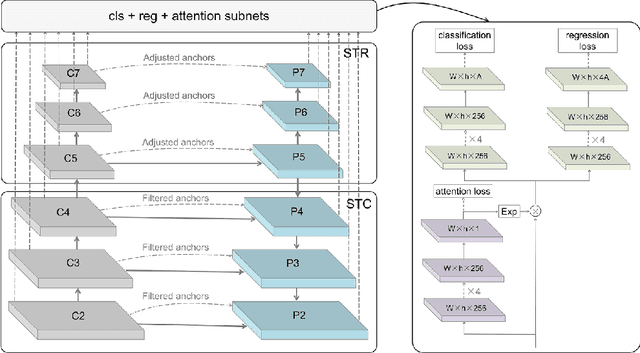
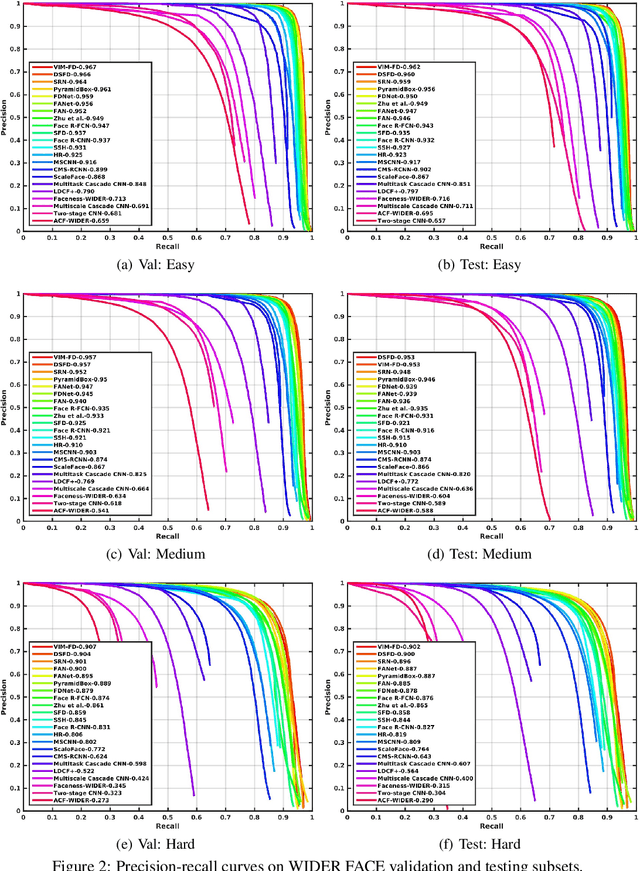


In recent years, face detection has experienced significant performance improvement with the boost of deep convolutional neural networks. In this report, we reimplement the state-of-the-art detector SRN and apply some tricks proposed in the recent literatures to obtain an extremely strong face detector, named VIM-FD. In specific, we exploit more powerful backbone network like DenseNet-121, revisit the data augmentation based on data-anchor-sampling proposed in PyramidBox, and use the max-in-out label and anchor matching strategy in SFD. In addition, we also introduce the attention mechanism to provide additional supervision. Over the most popular and challenging face detection benchmark, i.e., WIDER FACE, the proposed VIM-FD achieves state-of-the-art performance.