 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Deep Research: Training Multi-Agent Systems with M-GRPO
Nov 18, 2025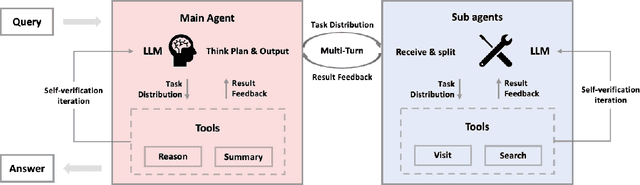
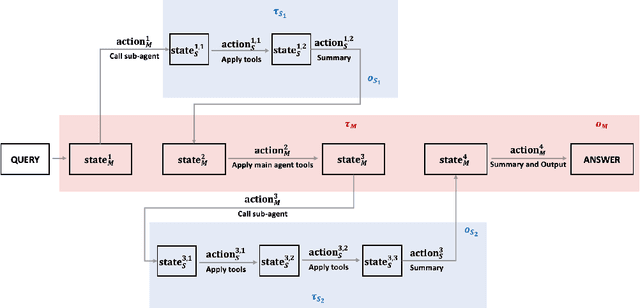
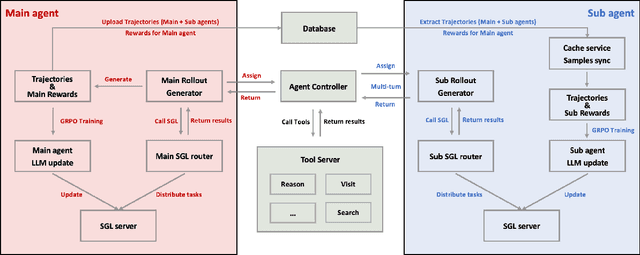
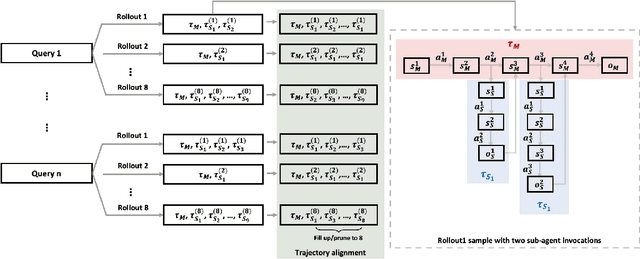
Multi-agent systems perform well on general reasoning tasks. However, the lack of training in specialized areas hinders their accuracy. Current training methods train a unified large language model (LLM) for all agents in the system. This may limit the performances due to different distributions underlying for different agents. Therefore, training multi-agent systems with distinct LLMs should be the next step to solve. However, this approach introduces optimization challenges. For example, agents operate at different frequencies, rollouts involve varying sub-agent invocations, and agents are often deployed across separate servers, disrupting end-to-end gradient flow. To address these issues, we propose M-GRPO, a hierarchical extension of Group Relative Policy Optimization designed for vertical Multi-agent systems with a main agent (planner) and multiple sub-agents (multi-turn tool executors). M-GRPO computes group-relative advantages for both main and sub-agents, maintaining hierarchical credit assignment. It also introduces a trajectory-alignment scheme that generates fixed-size batches despite variable sub-agent invocations. We deploy a decoupled training pipeline in which agents run on separate servers and exchange minimal statistics via a shared store. This enables scalable training without cross-server backpropagation. In experiments on real-world benchmarks (e.g., GAIA, XBench-DeepSearch, and WebWalkerQA), M-GRPO consistently outperforms both single-agent GRPO and multi-agent GRPO with frozen sub-agents, demonstrating improved stability and sample efficiency. These results show that aligning heterogeneous trajectories and decoupling optimization across specialized agents enhances tool-augmented reasoning tasks.
D3: Training-Free AI-Generated Video Detection Using Second-Order Features
Aug 01, 2025The evolution of video generation techniques, such as Sora, has made it increasingly easy to produce high-fidelity AI-generated videos, raising public concern over the dissemination of synthetic content. However, existing detection methodologies remain limited by their insufficient exploration of temporal artifacts in synthetic videos. To bridge this gap, we establish a theoretical framework through second-order dynamical analysis under Newtonian mechanics, subsequently extending the Second-order Central Difference features tailored for temporal artifact detection. Building on this theoretical foundation, we reveal a fundamental divergence in second-order feature distributions between real and AI-generated videos. Concretely, we propose Detection by Difference of Differences (D3), a novel training-free detection method that leverages the above second-order temporal discrepancies. We validate the superiority of our D3 on 4 open-source datasets (Gen-Video, VideoPhy, EvalCrafter, VidProM), 40 subsets in total. For example, on GenVideo, D3 outperforms the previous best method by 10.39% (absolute) mean Average Precision. Additional experiments on time cost and post-processing operations demonstrate D3's exceptional computational efficiency and strong robust performance. Our code is available at https://github.com/Zig-HS/D3.
LangScene-X: Reconstruct Generalizable 3D Language-Embedded Scenes with TriMap Video Diffusion
Jul 03, 2025


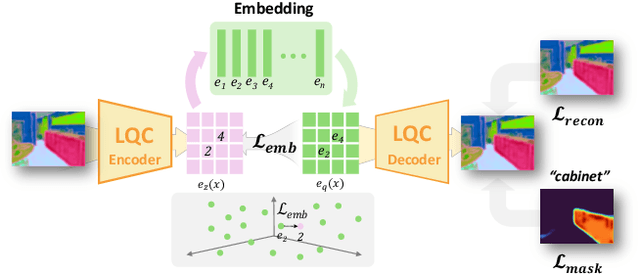
Recovering 3D structures with open-vocabulary scene understanding from 2D images is a fundamental but daunting task. Recent developments have achieved this by performing per-scene optimization with embedded language information. However, they heavily rely on the calibrated dense-view reconstruction paradigm, thereby suffering from severe rendering artifacts and implausible semantic synthesis when limited views are available. In this paper, we introduce a novel generative framework, coined LangScene-X, to unify and generate 3D consistent multi-modality information for reconstruction and understanding. Powered by the generative capability of creating more consistent novel observations, we can build generalizable 3D language-embedded scenes from only sparse views. Specifically, we first train a TriMap video diffusion model that can generate appearance (RGBs), geometry (normals), and semantics (segmentation maps) from sparse inputs through progressive knowledge integration. Furthermore, we propose a Language Quantized Compressor (LQC), trained on large-scale image datasets, to efficiently encode language embeddings, enabling cross-scene generalization without per-scene retraining. Finally, we reconstruct the language surface fields by aligning language information onto the surface of 3D scenes, enabling open-ended language queries. Extensive experiments on real-world data demonstrate the superiority of our LangScene-X over state-of-the-art methods in terms of quality and generalizability. Project Page: https://liuff19.github.io/LangScene-X.
GraphicsDreamer: Image to 3D Generation with Physical Consistency
Dec 18, 2024



Recently, the surge of efficient and automated 3D AI-generated content (AIGC) methods has increasingly illuminated the path of transforming human imagination into complex 3D structures. However, the automated generation of 3D content is still significantly lags in industrial application. This gap exists because 3D modeling demands high-quality assets with sharp geometry, exquisite topology, and physically based rendering (PBR), among other criteria. To narrow the disparity between generated results and artists' expectations, we introduce GraphicsDreamer, a method for creating highly usable 3D meshes from single images. To better capture the geometry and material details, we integrate the PBR lighting equation into our cross-domain diffusion model, concurrently predicting multi-view color, normal, depth images, and PBR materials. In the geometry fusion stage, we continue to enforce the PBR constraints, ensuring that the generated 3D objects possess reliable texture details, supporting realistic relighting. Furthermore, our method incorporates topology optimization and fast UV unwrapping capabilities, allowing the 3D products to be seamlessly imported into graphics engines. Extensive experiments demonstrate that our model can produce high quality 3D assets in a reasonable time cost compared to previous methods.
Ditto: Motion-Space Diffusion for Controllable Realtime Talking Head Synthesis
Nov 29, 2024Recent advances in diffusion models have revolutionized audio-driven talking head synthesis. Beyond precise lip synchronization, diffusion-based methods excel in generating subtle expressions and natural head movements that are well-aligned with the audio signal. However, these methods are confronted by slow inference speed, insufficient fine-grained control over facial motions, and occasional visual artifacts largely due to an implicit latent space derived from Variational Auto-Encoders (VAE), which prevent their adoption in realtime interaction applications. To address these issues, we introduce Ditto, a diffusion-based framework that enables controllable realtime talking head synthesis. Our key innovation lies in bridging motion generation and photorealistic neural rendering through an explicit identity-agnostic motion space, replacing conventional VAE representations. This design substantially reduces the complexity of diffusion learning while enabling precise control over the synthesized talking heads. We further propose an inference strategy that jointly optimizes three key components: audio feature extraction, motion generation, and video synthesis. This optimization enables streaming processing, realtime inference, and low first-frame delay, which are the functionalities crucial for interactive applications such as AI assistants. Extensive experimental results demonstrate that Ditto generates compelling talking head videos and substantially outperforms existing methods in both motion control and realtime performance.
Generating Human Motion in 3D Scenes from Text Descriptions
May 13, 2024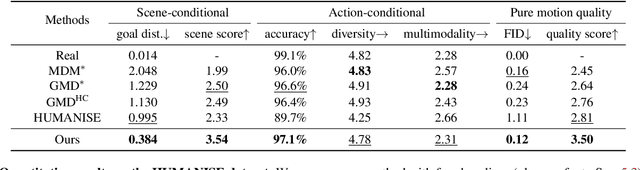
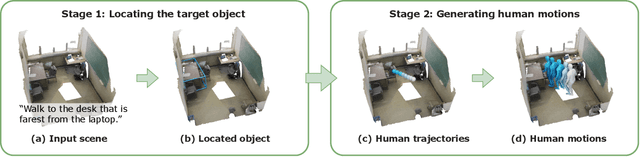
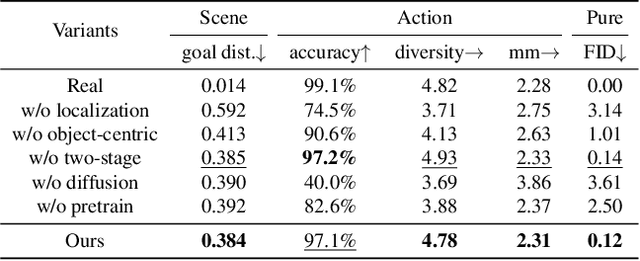
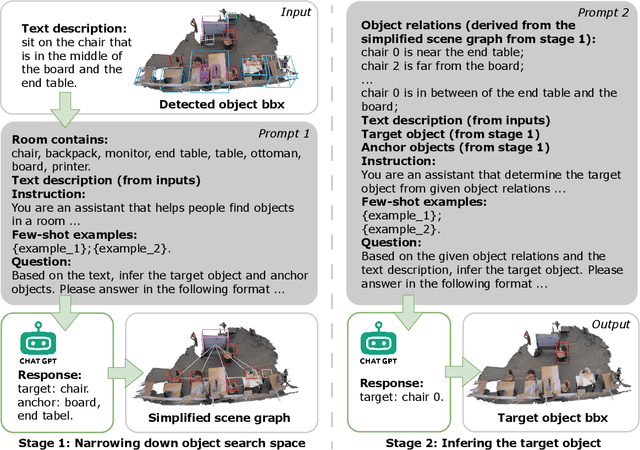
Generating human motions from textual descriptions has gained growing research interest due to its wide range of applications. However, only a few works consider human-scene interactions together with text conditions, which is crucial for visual and physical realism. This paper focuses on the task of generating human motions in 3D indoor scenes given text descriptions of the human-scene interactions. This task presents challenges due to the multi-modality nature of text, scene, and motion, as well as the need for spatial reasoning. To address these challenges, we propose a new approach that decomposes the complex problem into two more manageable sub-problems: (1) language grounding of the target object and (2) object-centric motion generation. For language grounding of the target object, we leverage the power of large language models. For motion generation, we design an object-centric scene representation for the generative model to focus on the target object, thereby reducing the scene complexity and facilitating the modeling of the relationship between human motions and the object. Experiments demonstrate the better motion quality of our approach compared to baselines and validate our design choices.
Bridging 3D Gaussian and Mesh for Freeview Video Rendering
Mar 18, 2024This is only a preview version of GauMesh. Recently, primitive-based rendering has been proven to achieve convincing results in solving the problem of modeling and rendering the 3D dynamic scene from 2D images. Despite this, in the context of novel view synthesis, each type of primitive has its inherent defects in terms of representation ability. It is difficult to exploit the mesh to depict the fuzzy geometry. Meanwhile, the point-based splatting (e.g. the 3D Gaussian Splatting) method usually produces artifacts or blurry pixels in the area with smooth geometry and sharp textures. As a result, it is difficult, even not impossible, to represent the complex and dynamic scene with a single type of primitive. To this end, we propose a novel approach, GauMesh, to bridge the 3D Gaussian and Mesh for modeling and rendering the dynamic scenes. Given a sequence of tracked mesh as initialization, our goal is to simultaneously optimize the mesh geometry, color texture, opacity maps, a set of 3D Gaussians, and the deformation field. At a specific time, we perform $\alpha$-blending on the RGB and opacity values based on the merged and re-ordered z-buffers from mesh and 3D Gaussian rasterizations. This produces the final rendering, which is supervised by the ground-truth image. Experiments demonstrate that our approach adapts the appropriate type of primitives to represent the different parts of the dynamic scene and outperforms all the baseline methods in both quantitative and qualitative comparisons without losing render speed.
Hierarchical Generation of Human-Object Interactions with Diffusion Probabilistic Models
Oct 03, 2023



This paper presents a novel approach to generating the 3D motion of a human interacting with a target object, with a focus on solving the challenge of synthesizing long-range and diverse motions, which could not be fulfilled by existing auto-regressive models or path planning-based methods. We propose a hierarchical generation framework to solve this challenge. Specifically, our framework first generates a set of milestones and then synthesizes the motion along them. Therefore, the long-range motion generation could be reduced to synthesizing several short motion sequences guided by milestones. The experiments on the NSM, COUCH, and SAMP datasets show that our approach outperforms previous methods by a large margin in both quality and diversity. The source code is available on our project page https://zju3dv.github.io/hghoi.
Multi-view Hypergraph Contrastive Policy Learning for Conversational Recommendation
Jul 26, 2023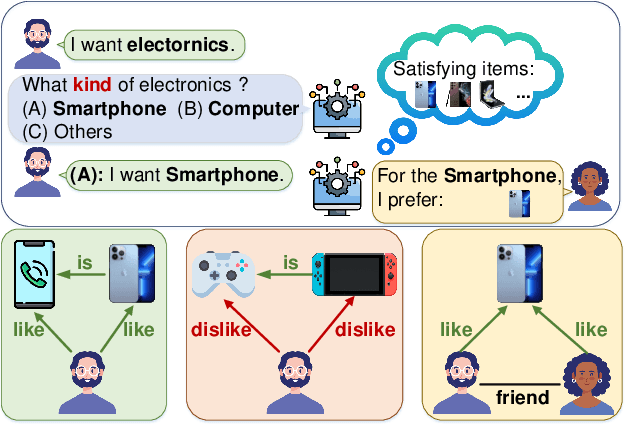

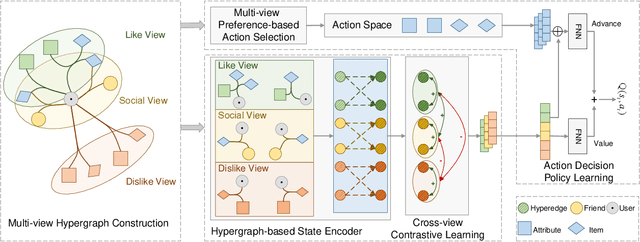

Conversational recommendation systems (CRS) aim to interactively acquire user preferences and accordingly recommend items to users. Accurately learning the dynamic user preferences is of crucial importance for CRS. Previous works learn the user preferences with pairwise relations from the interactive conversation and item knowledge, while largely ignoring the fact that factors for a relationship in CRS are multiplex. Specifically, the user likes/dislikes the items that satisfy some attributes (Like/Dislike view). Moreover social influence is another important factor that affects user preference towards the item (Social view), while is largely ignored by previous works in CRS. The user preferences from these three views are inherently different but also correlated as a whole. The user preferences from the same views should be more similar than that from different views. The user preferences from Like View should be similar to Social View while different from Dislike View. To this end, we propose a novel model, namely Multi-view Hypergraph Contrastive Policy Learning (MHCPL). Specifically, MHCPL timely chooses useful social information according to the interactive history and builds a dynamic hypergraph with three types of multiplex relations from different views. The multiplex relations in each view are successively connected according to their generation order.
Towards Hierarchical Policy Learning for Conversational Recommendation with Hypergraph-based Reinforcement Learning
May 04, 2023
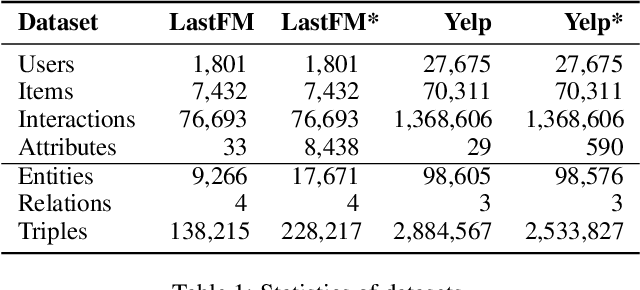

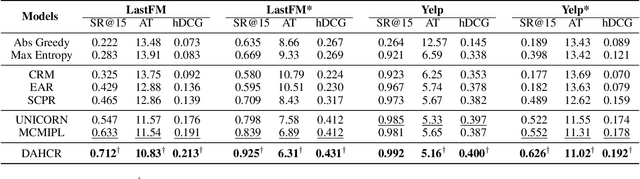
Conversational recommendation systems (CRS) aim to timely and proactively acquire user dynamic preferred attributes through conversations for item recommendation. In each turn of CRS, there naturally have two decision-making processes with different roles that influence each other: 1) director, which is to select the follow-up option (i.e., ask or recommend) that is more effective for reducing the action space and acquiring user preferences; and 2) actor, which is to accordingly choose primitive actions (i.e., asked attribute or recommended item) that satisfy user preferences and give feedback to estimate the effectiveness of the director's option. However, existing methods heavily rely on a unified decision-making module or heuristic rules, while neglecting to distinguish the roles of different decision procedures, as well as the mutual influences between them. To address this, we propose a novel Director-Actor Hierarchical Conversational Recommender (DAHCR), where the director selects the most effective option, followed by the actor accordingly choosing primitive actions that satisfy user preferences. Specifically, we develop a dynamic hypergraph to model user preferences and introduce an intrinsic motivation to train from weak supervision over the director. Finally, to alleviate the bad effect of model bias on the mutual influence between the director and actor, we model the director's option by sampling from a categorical distribution. Extensive experiments demonstrate that DAHCR outperforms state-of-the-art methods.