 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Reducible Uncertainty Modeling for Reliable Large Language Model Agents
Feb 04, 2026Uncertainty quantification (UQ) for large language models (LLMs) is a key building block for safety guardrails of daily LLM applications. Yet, even as LLM agents are increasingly deployed in highly complex tasks, most UQ research still centers on single-turn question-answering. We argue that UQ research must shift to realistic settings with interactive agents, and that a new principled framework for agent UQ is needed. This paper presents the first general formulation of agent UQ that subsumes broad classes of existing UQ setups. Under this formulation, we show that prior works implicitly treat LLM UQ as an uncertainty accumulation process, a viewpoint that breaks down for interactive agents in an open world. In contrast, we propose a novel perspective, a conditional uncertainty reduction process, that explicitly models reducible uncertainty over an agent's trajectory by highlighting "interactivity" of actions. From this perspective, we outline a conceptual framework to provide actionable guidance for designing UQ in LLM agent setups. Finally, we conclude with practical implications of the agent UQ in frontier LLM development and domain-specific applications, as well as open remaining problems.
LLM-based Human-like Traffic Simulation for Self-driving Tests
Aug 23, 2025Ensuring realistic traffic dynamics is a prerequisite for simulation platforms to evaluate the reliability of self-driving systems before deployment in the real world. Because most road users are human drivers, reproducing their diverse behaviors within simulators is vital. Existing solutions, however, typically rely on either handcrafted heuristics or narrow data-driven models, which capture only fragments of real driving behaviors and offer limited driving style diversity and interpretability. To address this gap, we introduce HDSim, an HD traffic generation framework that combines cognitive theory with large language model (LLM) assistance to produce scalable and realistic traffic scenarios within simulation platforms. The framework advances the state of the art in two ways: (i) it introduces a hierarchical driver model that represents diverse driving style traits, and (ii) it develops a Perception-Mediated Behavior Influence strategy, where LLMs guide perception to indirectly shape driver actions. Experiments reveal that embedding HDSim into simulation improves detection of safety-critical failures in self-driving systems by up to 68% and yields realism-consistent accident interpretability.
Process Reinforcement through Implicit Rewards
Feb 03, 2025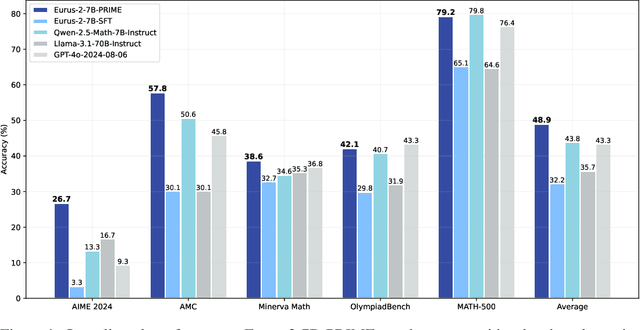

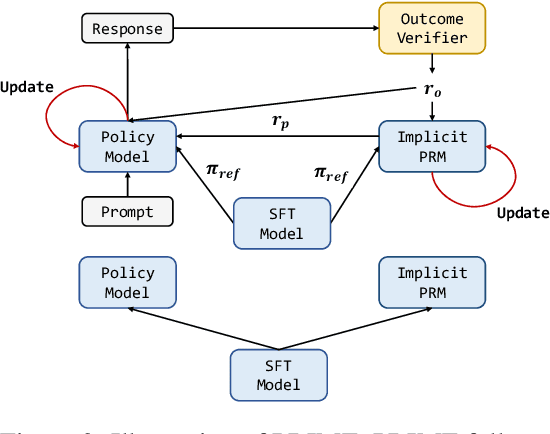
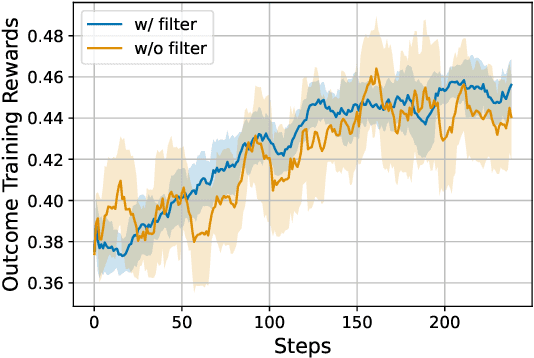
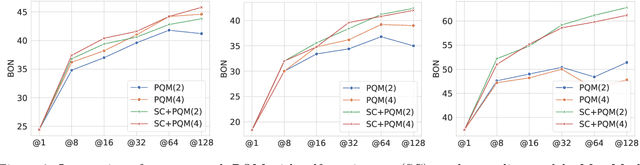
Dense process rewards have proven a more effective alternative to the sparse outcome-level rewards in the inference-time scaling of large language models (LLMs), particularly in tasks requiring complex multi-step reasoning. While dense rewards also offer an appealing choice for the reinforcement learning (RL) of LLMs since their fine-grained rewards have the potential to address some inherent issues of outcome rewards, such as training efficiency and credit assignment, this potential remains largely unrealized. This can be primarily attributed to the challenges of training process reward models (PRMs) online, where collecting high-quality process labels is prohibitively expensive, making them particularly vulnerable to reward hacking. To address these challenges, we propose PRIME (Process Reinforcement through IMplicit rEwards), which enables online PRM updates using only policy rollouts and outcome labels through implict process rewards. PRIME combines well with various advantage functions and forgoes the dedicated reward model training phrase that existing approaches require, substantially reducing the development overhead. We demonstrate PRIME's effectiveness on competitional math and coding. Starting from Qwen2.5-Math-7B-Base, PRIME achieves a 15.1% average improvement across several key reasoning benchmarks over the SFT model. Notably, our resulting model, Eurus-2-7B-PRIME, surpasses Qwen2.5-Math-7B-Instruct on seven reasoning benchmarks with 10% of its training data.
Free Process Rewards without Process Labels
Dec 02, 2024



Different from its counterpart outcome reward models (ORMs), which evaluate the entire responses, a process reward model (PRM) scores a reasoning trajectory step by step, providing denser and more fine grained rewards. However, training a PRM requires labels annotated at every intermediate step, presenting significant challenges for both manual and automatic data collection. This paper aims to address this challenge. Both theoretically and empirically, we show that an \textit{implicit PRM} can be obtained at no additional cost, by simply training an ORM on the cheaper response-level labels. The only assumption is to parameterize the outcome reward as the log-likelihood ratios of the policy and reference models, which can be optimized regardless of the specific choice of loss objectives. In experiments, we instantiate our implicit PRMs with various objectives and evaluate their performance on MATH. We show that our implicit PRM outperforms a strong MCTS-based baseline \textit{\'a la} Math-Shepherd using less than $1/38$ of the training data. Its performance can be further improved with majority voting. We further find that scaling up instructions and responses benefits our implicit PRM, and the latter brings a larger gain. Particularly, we find that our implicit PRM, when instantiated with the cross-entropy (CE) loss, is more data-efficient and can keep improving generation models even when trained with only one response per instruction, the setup that suffers from extreme data scarcity and imbalance. Further, instructions should be relevant to downstream tasks while the diversity of responses does not bring gains. Surprisingly, training on extra Math-Shepherd step labels brings no further improvements to our implicit PRM trained on only outcome data. We hope that our work will encourage a rethinking of PRM training approaches and contribute to making training PRMs more accessible.
FATH: Authentication-based Test-time Defense against Indirect Prompt Injection Attacks
Oct 28, 2024



Large language models (LLMs) have been widely deployed as the backbone with additional tools and text information for real-world applications. However, integrating external information into LLM-integrated applications raises significant security concerns. Among these, prompt injection attacks are particularly threatening, where malicious instructions injected in the external text information can exploit LLMs to generate answers as the attackers desire. While both training-time and test-time defense methods have been developed to mitigate such attacks, the unaffordable training costs associated with training-time methods and the limited effectiveness of existing test-time methods make them impractical. This paper introduces a novel test-time defense strategy, named Formatting AuThentication with Hash-based tags (FATH). Unlike existing approaches that prevent LLMs from answering additional instructions in external text, our method implements an authentication system, requiring LLMs to answer all received instructions with a security policy and selectively filter out responses to user instructions as the final output. To achieve this, we utilize hash-based authentication tags to label each response, facilitating accurate identification of responses according to the user's instructions and improving the robustness against adaptive attacks. Comprehensive experiments demonstrate that our defense method can effectively defend against indirect prompt injection attacks, achieving state-of-the-art performance under Llama3 and GPT3.5 models across various attack methods. Our code is released at: https://github.com/Jayfeather1024/FATH
Process Reward Model with Q-Value Rankings
Oct 15, 2024


Process Reward Modeling (PRM) is critical for complex reasoning and decision-making tasks where the accuracy of intermediate steps significantly influences the overall outcome. Existing PRM approaches, primarily framed as classification problems, employ cross-entropy loss to independently evaluate each step's correctness. This method can lead to suboptimal reward distribution and does not adequately address the interdependencies among steps. To address these limitations, we introduce the Process Q-value Model (PQM), a novel framework that redefines PRM in the context of a Markov Decision Process. PQM optimizes Q-value rankings based on a novel comparative loss function, enhancing the model's ability to capture the intricate dynamics among sequential decisions. This approach provides a more granular and theoretically grounded methodology for process rewards. Our extensive empirical evaluations across various sampling policies, language model backbones, and multi-step reasoning benchmarks show that PQM outperforms classification-based PRMs. The effectiveness of the comparative loss function is highlighted in our comprehensive ablation studies, confirming PQM's practical efficacy and theoretical advantage.
Position Debiasing Fine-Tuning for Causal Perception in Long-Term Dialogue
Jun 04, 2024



The core of the dialogue system is to generate relevant, informative, and human-like responses based on extensive dialogue history. Recently, dialogue generation domain has seen mainstream adoption of large language models (LLMs), due to its powerful capability in generating utterances. However, there is a natural deficiency for such models, that is, inherent position bias, which may lead them to pay more attention to the nearby utterances instead of causally relevant ones, resulting in generating irrelevant and generic responses in long-term dialogue. To alleviate such problem, in this paper, we propose a novel method, named Causal Perception long-term Dialogue framework (CPD), which employs perturbation-based causal variable discovery method to extract casually relevant utterances from the dialogue history and enhances model causal perception during fine-tuning. Specifically, a local-position awareness method is proposed in CPD for inter-sentence position correlation elimination, which helps models extract causally relevant utterances based on perturbations. Then, a casual-perception fine-tuning strategy is also proposed, to enhance the capability of discovering the causal invariant factors, by differently perturbing causally relevant and non-casually relevant ones for response generation. Experimental results on two datasets prove that our proposed method can effectively alleviate the position bias for multiple LLMs and achieve significant progress compared with existing baselines.
Reinforcement Learning with Token-level Feedback for Controllable Text Generation
Mar 18, 2024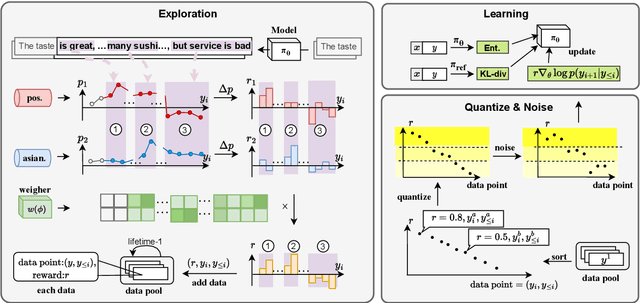
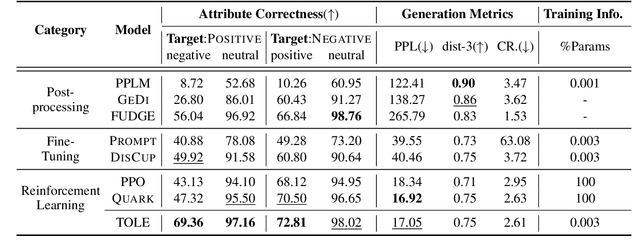
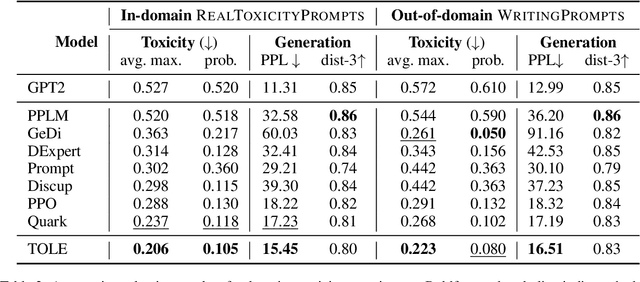
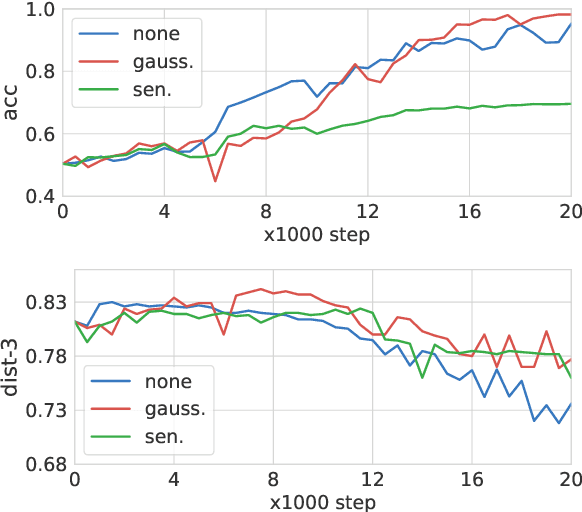
To meet the requirements of real-world applications, it is essential to control generations of large language models (LLMs). Prior research has tried to introduce reinforcement learning (RL) into controllable text generation while most existing methods suffer from overfitting issues (finetuning-based methods) or semantic collapse (post-processing methods). However, current RL methods are generally guided by coarse-grained (sentence/paragraph-level) feedback, which may lead to suboptimal performance owing to semantic twists or progressions within sentences. To tackle that, we propose a novel reinforcement learning algorithm named TOLE which formulates TOken-LEvel rewards for controllable text generation, and employs a "first-quantize-then-noise" paradigm to enhance the robustness of the RL algorithm.Furthermore, TOLE can be flexibly extended to multiple constraints with little computational expense. Experimental results show that our algorithm can achieve superior performance on both single-attribute and multi-attribute control tasks. We have released our codes at https://github.com/WindyLee0822/CTG
TREA: Tree-Structure Reasoning Schema for Conversational Recommendation
Jul 20, 2023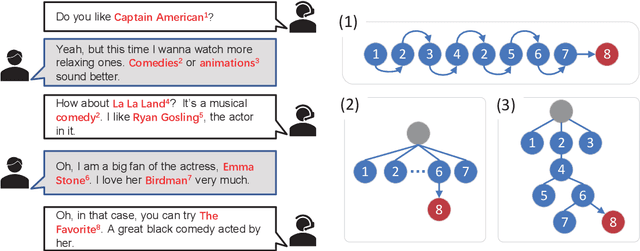



Conversational recommender systems (CRS) aim to timely trace the dynamic interests of users through dialogues and generate relevant responses for item recommendations. Recently, various external knowledge bases (especially knowledge graphs) are incorporated into CRS to enhance the understanding of conversation contexts. However, recent reasoning-based models heavily rely on simplified structures such as linear structures or fixed-hierarchical structures for causality reasoning, hence they cannot fully figure out sophisticated relationships among utterances with external knowledge. To address this, we propose a novel Tree structure Reasoning schEmA named TREA. TREA constructs a multi-hierarchical scalable tree as the reasoning structure to clarify the causal relationships between mentioned entities, and fully utilizes historical conversations to generate more reasonable and suitable responses for recommended results. Extensive experiments on two public CRS datasets have demonstrated the effectiveness of our approach.
Towards Hierarchical Policy Learning for Conversational Recommendation with Hypergraph-based Reinforcement Learning
May 04, 2023
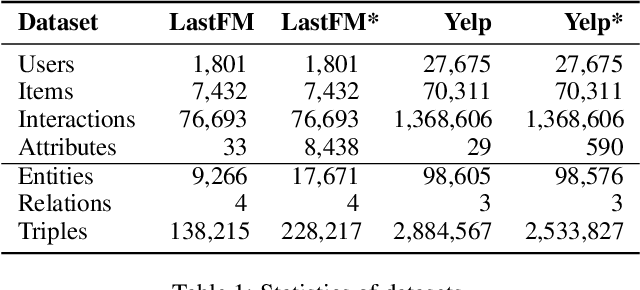

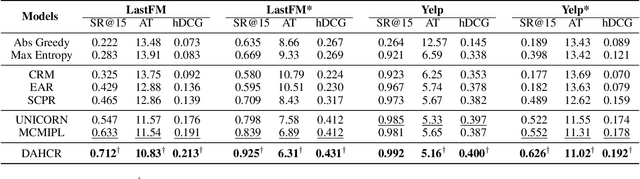
Conversational recommendation systems (CRS) aim to timely and proactively acquire user dynamic preferred attributes through conversations for item recommendation. In each turn of CRS, there naturally have two decision-making processes with different roles that influence each other: 1) director, which is to select the follow-up option (i.e., ask or recommend) that is more effective for reducing the action space and acquiring user preferences; and 2) actor, which is to accordingly choose primitive actions (i.e., asked attribute or recommended item) that satisfy user preferences and give feedback to estimate the effectiveness of the director's option. However, existing methods heavily rely on a unified decision-making module or heuristic rules, while neglecting to distinguish the roles of different decision procedures, as well as the mutual influences between them. To address this, we propose a novel Director-Actor Hierarchical Conversational Recommender (DAHCR), where the director selects the most effective option, followed by the actor accordingly choosing primitive actions that satisfy user preferences. Specifically, we develop a dynamic hypergraph to model user preferences and introduce an intrinsic motivation to train from weak supervision over the director. Finally, to alleviate the bad effect of model bias on the mutual influence between the director and actor, we model the director's option by sampling from a categorical distribution. Extensive experiments demonstrate that DAHCR outperforms state-of-the-art methods.