 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfoTok: Adaptive Discrete Video Tokenizer via Information-Theoretic Compression
Dec 18, 2025Accurate and efficient discrete video tokenization is essential for long video sequences processing. Yet, the inherent complexity and variable information density of videos present a significant bottleneck for current tokenizers, which rigidly compress all content at a fixed rate, leading to redundancy or information loss. Drawing inspiration from Shannon's information theory, this paper introduces InfoTok, a principled framework for adaptive video tokenization. We rigorously prove that existing data-agnostic training methods are suboptimal in representation length, and present a novel evidence lower bound (ELBO)-based algorithm that approaches theoretical optimality. Leveraging this framework, we develop a transformer-based adaptive compressor that enables adaptive tokenization. Empirical results demonstrate state-of-the-art compression performance, saving 20% tokens without influence on performance, and achieving 2.3x compression rates while still outperforming prior heuristic adaptive approaches. By allocating tokens according to informational richness, InfoTok enables a more compressed yet accurate tokenization for video representation, offering valuable insights for future research.
DiffusionNFT: Online Diffusion Reinforcement with Forward Process
Sep 19, 2025Online reinforcement learning (RL) has been central to post-training language models, but its extension to diffusion models remains challenging due to intractable likelihoods. Recent works discretize the reverse sampling process to enable GRPO-style training, yet they inherit fundamental drawbacks, including solver restrictions, forward-reverse inconsistency, and complicated integration with classifier-free guidance (CFG). We introduce Diffusion Negative-aware FineTuning (DiffusionNFT), a new online RL paradigm that optimizes diffusion models directly on the forward process via flow matching. DiffusionNFT contrasts positive and negative generations to define an implicit policy improvement direction, naturally incorporating reinforcement signals into the supervised learning objective. This formulation enables training with arbitrary black-box solvers, eliminates the need for likelihood estimation, and requires only clean images rather than sampling trajectories for policy optimization. DiffusionNFT is up to $25\times$ more efficient than FlowGRPO in head-to-head comparisons, while being CFG-free. For instance, DiffusionNFT improves the GenEval score from 0.24 to 0.98 within 1k steps, while FlowGRPO achieves 0.95 with over 5k steps and additional CFG employment. By leveraging multiple reward models, DiffusionNFT significantly boosts the performance of SD3.5-Medium in every benchmark tested.
A Survey of Reinforcement Learning for Large Reasoning Models
Sep 10, 2025In this paper, we survey recent advances in Reinforcement Learning (RL) for reasoning with Large Language Models (LLMs). RL has achieved remarkable success in advancing the frontier of LLM capabilities, particularly in addressing complex logical tasks such as mathematics and coding. As a result, RL has emerged as a foundational methodology for transforming LLMs into LRMs. With the rapid progress of the field, further scaling of RL for LRMs now faces foundational challenges not only in computational resources but also in algorithm design, training data, and infrastructure. To this end, it is timely to revisit the development of this domain, reassess its trajectory, and explore strategies to enhance the scalability of RL toward Artificial SuperIntelligence (ASI). In particular, we examine research applying RL to LLMs and LRMs for reasoning abilities, especially since the release of DeepSeek-R1, including foundational components, core problems, training resources, and downstream applications, to identify future opportunities and directions for this rapidly evolving area. We hope this review will promote future research on RL for broader reasoning models. Github: https://github.com/TsinghuaC3I/Awesome-RL-for-LRMs
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
May 28, 2025



This paper aims to overcome a major obstacle in scaling RL for reasoning with LLMs, namely the collapse of policy entropy. Such phenomenon is consistently observed across vast RL runs without entropy intervention, where the policy entropy dropped sharply at the early training stage, this diminished exploratory ability is always accompanied with the saturation of policy performance. In practice, we establish a transformation equation R=-a*e^H+b between entropy H and downstream performance R. This empirical law strongly indicates that, the policy performance is traded from policy entropy, thus bottlenecked by its exhaustion, and the ceiling is fully predictable H=0, R=-a+b. Our finding necessitates entropy management for continuous exploration toward scaling compute for RL. To this end, we investigate entropy dynamics both theoretically and empirically. Our derivation highlights that, the change in policy entropy is driven by the covariance between action probability and the change in logits, which is proportional to its advantage when using Policy Gradient-like algorithms. Empirical study shows that, the values of covariance term and entropy differences matched exactly, supporting the theoretical conclusion. Moreover, the covariance term stays mostly positive throughout training, further explaining why policy entropy would decrease monotonically. Through understanding the mechanism behind entropy dynamics, we motivate to control entropy by restricting the update of high-covariance tokens. Specifically, we propose two simple yet effective techniques, namely Clip-Cov and KL-Cov, which clip and apply KL penalty to tokens with high covariances respectively. Experiments show that these methods encourage exploration, thus helping policy escape entropy collapse and achieve better downstream performance.
Bridging Supervised Learning and Reinforcement Learning in Math Reasoning
May 23, 2025Reinforcement Learning (RL) has played a central role in the recent surge of LLMs' math abilities by enabling self-improvement through binary verifier signals. In contrast, Supervised Learning (SL) is rarely considered for such verification-driven training, largely due to its heavy reliance on reference answers and inability to reflect on mistakes. In this work, we challenge the prevailing notion that self-improvement is exclusive to RL and propose Negative-aware Fine-Tuning (NFT) -- a supervised approach that enables LLMs to reflect on their failures and improve autonomously with no external teachers. In online training, instead of throwing away self-generated negative answers, NFT constructs an implicit negative policy to model them. This implicit policy is parameterized with the same positive LLM we target to optimize on positive data, enabling direct policy optimization on all LLMs' generations. We conduct experiments on 7B and 32B models in math reasoning tasks. Results consistently show that through the additional leverage of negative feedback, NFT significantly improves over SL baselines like Rejection sampling Fine-Tuning, matching or even surpassing leading RL algorithms like GRPO and DAPO. Furthermore, we demonstrate that NFT and GRPO are actually equivalent in strict-on-policy training, even though they originate from entirely different theoretical foundations. Our experiments and theoretical findings bridge the gap between SL and RL methods in binary-feedback learning systems.
Cosmos-Reason1: From Physical Common Sense To Embodied Reasoning
Mar 18, 2025Physical AI systems need to perceive, understand, and perform complex actions in the physical world. In this paper, we present the Cosmos-Reason1 models that can understand the physical world and generate appropriate embodied decisions (e.g., next step action) in natural language through long chain-of-thought reasoning processes. We begin by defining key capabilities for Physical AI reasoning, with a focus on physical common sense and embodied reasoning. To represent physical common sense, we use a hierarchical ontology that captures fundamental knowledge about space, time, and physics. For embodied reasoning, we rely on a two-dimensional ontology that generalizes across different physical embodiments. Building on these capabilities, we develop two multimodal large language models, Cosmos-Reason1-8B and Cosmos-Reason1-56B. We curate data and train our models in four stages: vision pre-training, general supervised fine-tuning (SFT), Physical AI SFT, and Physical AI reinforcement learning (RL) as the post-training. To evaluate our models, we build comprehensive benchmarks for physical common sense and embodied reasoning according to our ontologies. Evaluation results show that Physical AI SFT and reinforcement learning bring significant improvements. To facilitate the development of Physical AI, we will make our code and pre-trained models available under the NVIDIA Open Model License at https://github.com/nvidia-cosmos/cosmos-reason1.
Direct Discriminative Optimization: Your Likelihood-Based Visual Generative Model is Secretly a GAN Discriminator
Mar 03, 2025While likelihood-based generative models, particularly diffusion and autoregressive models, have achieved remarkable fidelity in visual generation, the maximum likelihood estimation (MLE) objective inherently suffers from a mode-covering tendency that limits the generation quality under limited model capacity. In this work, we propose Direct Discriminative Optimization (DDO) as a unified framework that bridges likelihood-based generative training and the GAN objective to bypass this fundamental constraint. Our key insight is to parameterize a discriminator implicitly using the likelihood ratio between a learnable target model and a fixed reference model, drawing parallels with the philosophy of Direct Preference Optimization (DPO). Unlike GANs, this parameterization eliminates the need for joint training of generator and discriminator networks, allowing for direct, efficient, and effective finetuning of a well-trained model to its full potential beyond the limits of MLE. DDO can be performed iteratively in a self-play manner for progressive model refinement, with each round requiring less than 1% of pretraining epochs. Our experiments demonstrate the effectiveness of DDO by significantly advancing the previous SOTA diffusion model EDM, reducing FID scores from 1.79/1.58 to new records of 1.30/0.97 on CIFAR-10/ImageNet-64 datasets, and by consistently improving both guidance-free and CFG-enhanced FIDs of visual autoregressive models on ImageNet 256$\times$256.
Exploratory Diffusion Policy for Unsupervised Reinforcement Learning
Feb 11, 2025



Unsupervised reinforcement learning (RL) aims to pre-train agents by exploring states or skills in reward-free environments, facilitating the adaptation to downstream tasks. However, existing methods often overlook the fitting ability of pre-trained policies and struggle to handle the heterogeneous pre-training data, which are crucial for achieving efficient exploration and fast fine-tuning. To address this gap, we propose Exploratory Diffusion Policy (EDP), which leverages the strong expressive ability of diffusion models to fit the explored data, both boosting exploration and obtaining an efficient initialization for downstream tasks. Specifically, we estimate the distribution of collected data in the replay buffer with the diffusion policy and propose a score intrinsic reward, encouraging the agent to explore unseen states. For fine-tuning the pre-trained diffusion policy on downstream tasks, we provide both theoretical analyses and practical algorithms, including an alternating method of Q function optimization and diffusion policy distillation. Extensive experiments demonstrate the effectiveness of EDP in efficient exploration during pre-training and fast adaptation during fine-tuning.
Process Reinforcement through Implicit Rewards
Feb 03, 2025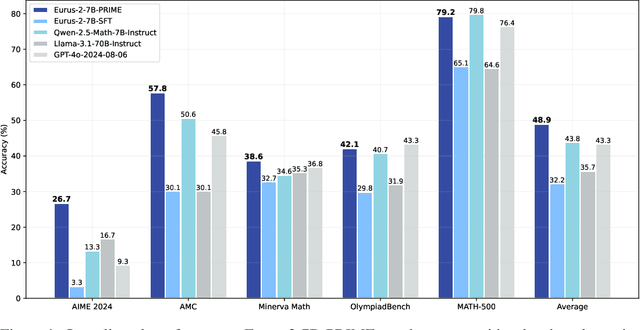

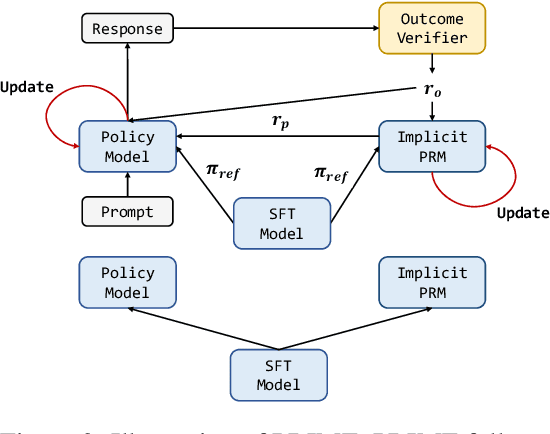
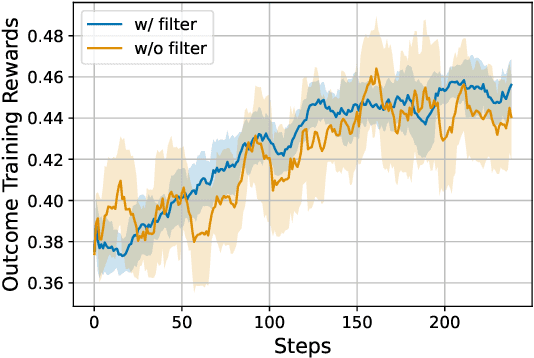
Dense process rewards have proven a more effective alternative to the sparse outcome-level rewards in the inference-time scaling of large language models (LLMs), particularly in tasks requiring complex multi-step reasoning. While dense rewards also offer an appealing choice for the reinforcement learning (RL) of LLMs since their fine-grained rewards have the potential to address some inherent issues of outcome rewards, such as training efficiency and credit assignment, this potential remains largely unrealized. This can be primarily attributed to the challenges of training process reward models (PRMs) online, where collecting high-quality process labels is prohibitively expensive, making them particularly vulnerable to reward hacking. To address these challenges, we propose PRIME (Process Reinforcement through IMplicit rEwards), which enables online PRM updates using only policy rollouts and outcome labels through implict process rewards. PRIME combines well with various advantage functions and forgoes the dedicated reward model training phrase that existing approaches require, substantially reducing the development overhead. We demonstrate PRIME's effectiveness on competitional math and coding. Starting from Qwen2.5-Math-7B-Base, PRIME achieves a 15.1% average improvement across several key reasoning benchmarks over the SFT model. Notably, our resulting model, Eurus-2-7B-PRIME, surpasses Qwen2.5-Math-7B-Instruct on seven reasoning benchmarks with 10% of its training data.
Visual Generation Without Guidance
Jan 26, 2025



Classifier-Free Guidance (CFG) has been a default technique in various visual generative models, yet it requires inference from both conditional and unconditional models during sampling. We propose to build visual models that are free from guided sampling. The resulting algorithm, Guidance-Free Training (GFT), matches the performance of CFG while reducing sampling to a single model, halving the computational cost. Unlike previous distillation-based approaches that rely on pretrained CFG networks, GFT enables training directly from scratch. GFT is simple to implement. It retains the same maximum likelihood objective as CFG and differs mainly in the parameterization of conditional models. Implementing GFT requires only minimal modifications to existing codebases, as most design choices and hyperparameters are directly inherited from CFG. Our extensive experiments across five distinct visual models demonstrate the effectiveness and versatility of GFT. Across domains of diffusion, autoregressive, and masked-prediction modeling, GFT consistently achieves comparable or even lower FID scores, with similar diversity-fidelity trade-offs compared with CFG baselines, all while being guidance-free. Code will be available at https://github.com/thu-ml/GFT.