 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRDT2: Exploring the Scaling Limit of UMI Data Towards Zero-Shot Cross-Embodiment Generalization
Feb 03, 2026Vision-Language-Action (VLA) models hold promise for generalist robotics but currently struggle with data scarcity, architectural inefficiencies, and the inability to generalize across different hardware platforms. We introduce RDT2, a robotic foundation model built upon a 7B parameter VLM designed to enable zero-shot deployment on novel embodiments for open-vocabulary tasks. To achieve this, we collected one of the largest open-source robotic datasets--over 10,000 hours of demonstrations in diverse families--using an enhanced, embodiment-agnostic Universal Manipulation Interface (UMI). Our approach employs a novel three-stage training recipe that aligns discrete linguistic knowledge with continuous control via Residual Vector Quantization (RVQ), flow-matching, and distillation for real-time inference. Consequently, RDT2 becomes one of the first models that simultaneously zero-shot generalizes to unseen objects, scenes, instructions, and even robotic platforms. Besides, it outperforms state-of-the-art baselines in dexterous, long-horizon, and dynamic downstream tasks like playing table tennis. See https://rdt-robotics.github.io/rdt2/ for more information.
Vidarc: Embodied Video Diffusion Model for Closed-loop Control
Dec 19, 2025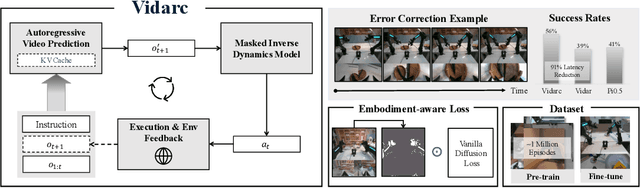
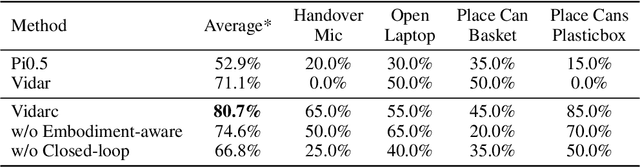
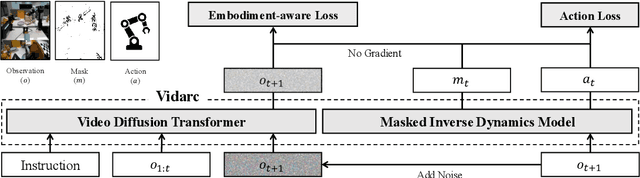
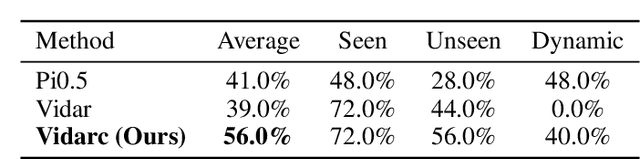
Robotic arm manipulation in data-scarce settings is a highly challenging task due to the complex embodiment dynamics and diverse contexts. Recent video-based approaches have shown great promise in capturing and transferring the temporal and physical interactions by pre-training on Internet-scale video data. However, such methods are often not optimized for the embodiment-specific closed-loop control, typically suffering from high latency and insufficient grounding. In this paper, we present Vidarc (Video Diffusion for Action Reasoning and Closed-loop Control), a novel autoregressive embodied video diffusion approach augmented by a masked inverse dynamics model. By grounding video predictions with action-relevant masks and incorporating real-time feedback through cached autoregressive generation, Vidarc achieves fast, accurate closed-loop control. Pre-trained on one million cross-embodiment episodes, Vidarc surpasses state-of-the-art baselines, achieving at least a 15% higher success rate in real-world deployment and a 91% reduction in latency. We also highlight its robust generalization and error correction capabilities across previously unseen robotic platforms.
Motus: A Unified Latent Action World Model
Dec 15, 2025While a general embodied agent must function as a unified system, current methods are built on isolated models for understanding, world modeling, and control. This fragmentation prevents unifying multimodal generative capabilities and hinders learning from large-scale, heterogeneous data. In this paper, we propose Motus, a unified latent action world model that leverages existing general pretrained models and rich, sharable motion information. Motus introduces a Mixture-of-Transformer (MoT) architecture to integrate three experts (i.e., understanding, video generation, and action) and adopts a UniDiffuser-style scheduler to enable flexible switching between different modeling modes (i.e., world models, vision-language-action models, inverse dynamics models, video generation models, and video-action joint prediction models). Motus further leverages the optical flow to learn latent actions and adopts a recipe with three-phase training pipeline and six-layer data pyramid, thereby extracting pixel-level "delta action" and enabling large-scale action pretraining. Experiments show that Motus achieves superior performance against state-of-the-art methods in both simulation (a +15% improvement over X-VLA and a +45% improvement over Pi0.5) and real-world scenarios(improved by +11~48%), demonstrating unified modeling of all functionalities and priors significantly benefits downstream robotic tasks.
ManiBox: Enhancing Spatial Grasping Generalization via Scalable Simulation Data Generation
Nov 04, 2024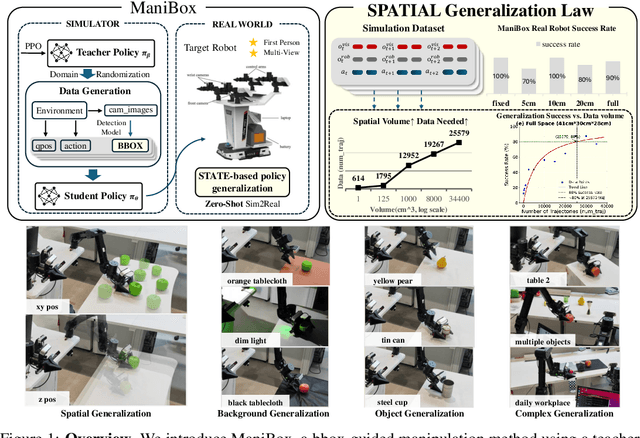

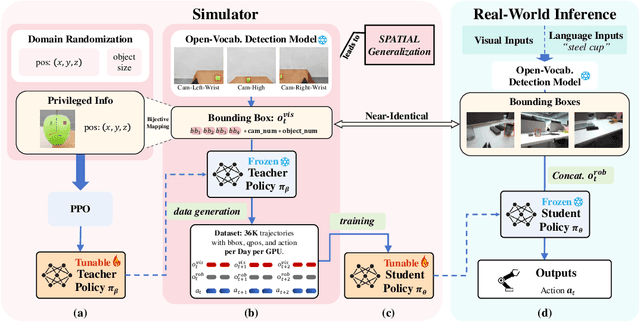

Learning a precise robotic grasping policy is crucial for embodied agents operating in complex real-world manipulation tasks. Despite significant advancements, most models still struggle with accurate spatial positioning of objects to be grasped. We first show that this spatial generalization challenge stems primarily from the extensive data requirements for adequate spatial understanding. However, collecting such data with real robots is prohibitively expensive, and relying on simulation data often leads to visual generalization gaps upon deployment. To overcome these challenges, we then focus on state-based policy generalization and present \textbf{ManiBox}, a novel bounding-box-guided manipulation method built on a simulation-based teacher-student framework. The teacher policy efficiently generates scalable simulation data using bounding boxes, which are proven to uniquely determine the objects' spatial positions. The student policy then utilizes these low-dimensional spatial states to enable zero-shot transfer to real robots. Through comprehensive evaluations in simulated and real-world environments, ManiBox demonstrates a marked improvement in spatial grasping generalization and adaptability to diverse objects and backgrounds. Further, our empirical study into scaling laws for policy performance indicates that spatial volume generalization scales positively with data volume. For a certain level of spatial volume, the success rate of grasping empirically follows Michaelis-Menten kinetics relative to data volume, showing a saturation effect as data increases. Our videos and code are available in https://thkkk.github.io/manibox.
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
Oct 10, 2024



Bimanual manipulation is essential in robotics, yet developing foundation models is extremely challenging due to the inherent complexity of coordinating two robot arms (leading to multi-modal action distributions) and the scarcity of training data. In this paper, we present the Robotics Diffusion Transformer (RDT), a pioneering diffusion foundation model for bimanual manipulation. RDT builds on diffusion models to effectively represent multi-modality, with innovative designs of a scalable Transformer to deal with the heterogeneity of multi-modal inputs and to capture the nonlinearity and high frequency of robotic data. To address data scarcity, we further introduce a Physically Interpretable Unified Action Space, which can unify the action representations of various robots while preserving the physical meanings of original actions, facilitating learning transferrable physical knowledge. With these designs, we managed to pre-train RDT on the largest collection of multi-robot datasets to date and scaled it up to 1.2B parameters, which is the largest diffusion-based foundation model for robotic manipulation. We finally fine-tuned RDT on a self-created multi-task bimanual dataset with over 6K+ episodes to refine its manipulation capabilities. Experiments on real robots demonstrate that RDT significantly outperforms existing methods. It exhibits zero-shot generalization to unseen objects and scenes, understands and follows language instructions, learns new skills with just 1~5 demonstrations, and effectively handles complex, dexterous tasks. We refer to https://rdt-robotics.github.io/rdt-robotics/ for the code and videos.
Fourier Controller Networks for Real-Time Decision-Making in Embodied Learning
May 30, 2024Reinforcement learning is able to obtain generalized low-level robot policies on diverse robotics datasets in embodied learning scenarios, and Transformer has been widely used to model time-varying features. However, it still suffers from the issues of low data efficiency and high inference latency. In this paper, we propose to investigate the task from a new perspective of the frequency domain. We first observe that the energy density in the frequency domain of a robot's trajectory is mainly concentrated in the low-frequency part. Then, we present the Fourier Controller Network (FCNet), a new network that utilizes the Short-Time Fourier Transform (STFT) to extract and encode time-varying features through frequency domain interpolation. We further achieve parallel training and efficient recurrent inference by using FFT and Sliding DFT methods in the model architecture for real-time decision-making. Comprehensive analyses in both simulated (e.g., D4RL) and real-world environments (e.g., robot locomotion) demonstrate FCNet's substantial efficiency and effectiveness over existing methods such as Transformer, e.g., FCNet outperforms Transformer on multi-environmental robotics datasets of all types of sizes (from 1.9M to 120M). The project page and code can be found https://thkkk.github.io/fcnet.