 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuidedBridge: Training-freely Improving Bridge Models with Prior Guidance
Jun 02, 2026Guidance methods, such as classifier-free guidance (CFG) and auto-guidance (AG), have advanced noise-to-data generation in diffusion models. Recently, bridge models have introduced a data-to-data generative process that can exploit an instructive clean prior. In this work, inspired by previous methods creating quality difference between denoising results as guidance, we propose a training-free bridge guidance method, termed Prior Guidance (PG). Specifically, we introduce a weak prior, which is unseen during bridge pre-training, hindering prior exploitation and thereby degrading denoising result. Then, we contrast it with the seen prior to highlight and enhance prior exploitation via a scaling factor. Moreover, we analyze the underlying mechanism of prior exploitation in the bridge process and design frequency-modulated prior guidance (FMPG), which tailors the guidance scale to low- and high-frequency bands coherent with bridge generative dynamics. To address prior exploitation in image in-painting, we develop a cascaded framework, CFG-FMPG, which first generates a noisy hidden representation via CFG and then exploits it as a generative prior with FMPG, fulfilling their complementary strengths without compromising inference efficiency. Experiments demonstrate that our PG methods consistently improve pre-trained bridge models across diverse image translation tasks.
minWM: A Full-Stack Open-Source Framework for Real-Time Interactive Video World Models
May 28, 2026Recent video diffusion foundation models have achieved remarkable progress in high-quality video generation, yet turning them into real-time interactive video world models remains challenging. Interactive world models require controllable, causal, and low-latency rollout, which in practice demands a full pipeline spanning data construction, controllable fine-tuning, autoregressive training, few-step distillation, and streaming inference. In this work, we present minWM, a full-stack open-source framework for building real-time interactive video world models. minWM provides an end-to-end pipeline that converts existing bidirectional T2V/TI2V video foundation models into camera-controllable few-step autoregressive world models. Specifically, minWM first fine-tunes a bidirectional video diffusion model with camera control, and then applies the Causal Forcing / Causal Forcing++ pipeline, including AR diffusion training, causal ODE or causal consistency distillation, and asymmetric DMD, to distill it into a few-step autoregressive generator for low-latency rollout. The framework is modular and architecture-extensible: we instantiate it on representative open backbones, including Wan2.1-T2V-1.3B and HY1.5-TI2V-8B, covering both cross-attention-based condition injection and MMDiT-style architectures. minWM also supports adapting existing video world models, such as HY-WorldPlay, to new data distributions, training recipes, and latency targets. Beyond releasing runnable scripts, checkpoints, documentation, and inference code, we provide practical ablations on camera trajectory quality, controllability training steps, and minimal batch-size requirements. We hope minWM serves as a reproducible and extensible recipe for building and adapting real-time interactive video world models. Project Page: [https://github.com/shengshu-ai/minWM](https://github.com/shengshu-ai/minWM)
Causal Forcing++: Scalable Few-Step Autoregressive Diffusion Distillation for Real-Time Interactive Video Generation
May 14, 2026Real-time interactive video generation requires low-latency, streaming, and controllable rollout. Existing autoregressive (AR) diffusion distillation methods have achieved strong results in the chunk-wise 4-step regime by distilling bidirectional base models into few-step AR students, but they remain limited by coarse response granularity and non-negligible sampling latency. In this paper, we study a more aggressive setting: frame-wise autoregression with only 1--2 sampling steps. In this regime, we identify the initialization of a few-step AR student as the key bottleneck: existing strategies are either target-misaligned, incapable of few-step generation, or too costly to scale. We propose \textbf{Causal Forcing++}, a principled and scalable pipeline that uses \emph{causal consistency distillation} (causal CD) for few-step AR initialization. The core idea is that causal CD learns the same AR-conditional flow map as causal ODE distillation, but obtains supervision from a single online teacher ODE step between adjacent timesteps, avoiding the need to precompute and store full PF-ODE trajectories. This makes the initialization both more efficient and easier to optimize. The resulting pipeline, \ours, surpasses the SOTA 4-step chunk-wise Causal Forcing under the \textit{\textbf{frame-wise 2-step setting}} by 0.1 in VBench Total, 0.3 in VBench Quality, and 0.335 in VisionReward, while reducing first-frame latency by 50\% and Stage 2 training cost by $\sim$$4\times$. We further extend the pipeline to action-conditioned world model generation in the spirit of Genie3. Project Page: https://github.com/thu-ml/Causal-Forcing and https://github.com/shengshu-ai/minWM .
Training-Free Test-Time Contrastive Learning for Large Language Models
Apr 15, 2026Large language models (LLMs) demonstrate strong reasoning capabilities, but their performance often degrades under distribution shift. Existing test-time adaptation (TTA) methods rely on gradient-based updates that require white-box access and need substantial overhead, while training-free alternatives are either static or depend on external guidance. In this paper, we propose Training-Free Test-Time Contrastive Learning TF-TTCL, a training-free adaptation framework that enables a frozen LLM to improve online by distilling supervision from its own inference experiences. Specifically, TF-TTCL implements a dynamic "Explore-Reflect-Steer" loop through three core modules: 1) Semantic Query Augmentation first diversifies problem views via multi-agent role-playing to generate different reasoning trajectories; 2) Contrastive Experience Distillation then captures the semantic gap between superior and inferior trajectories, distilling them into explicit textual rules; and 3) Contextual Rule Retrieval finally activates these stored rules during inference to dynamically steer the frozen LLM toward robust reasoning patterns while avoiding observed errors. Extensive experiments on closed-ended reasoning tasks and open-ended evaluation tasks demonstrate that TF-TTCL consistently outperforms strong zero-shot baselines and representative TTA methods under online evaluation. Code is available at https://github.com/KevinSCUTer/TF-TTCL.
SLA2: Sparse-Linear Attention with Learnable Routing and QAT
Feb 13, 2026Sparse-Linear Attention (SLA) combines sparse and linear attention to accelerate diffusion models and has shown strong performance in video generation. However, (i) SLA relies on a heuristic split that assigns computations to the sparse or linear branch based on attention-weight magnitude, which can be suboptimal. Additionally, (ii) after formally analyzing the attention error in SLA, we identify a mismatch between SLA and a direct decomposition into sparse and linear attention. We propose SLA2, which introduces (I) a learnable router that dynamically selects whether each attention computation should use sparse or linear attention, (II) a more faithful and direct sparse-linear attention formulation that uses a learnable ratio to combine the sparse and linear attention branches, and (III) a sparse + low-bit attention design, where low-bit attention is introduced via quantization-aware fine-tuning to reduce quantization error. Experiments show that on video diffusion models, SLA2 can achieve 97% attention sparsity and deliver an 18.6x attention speedup while preserving generation quality.
Benchmarking Multimodal Large Language Models for Missing Modality Completion in Product Catalogues
Jan 28, 2026Missing-modality information on e-commerce platforms, such as absent product images or textual descriptions, often arises from annotation errors or incomplete metadata, impairing both product presentation and downstream applications such as recommendation systems. Motivated by the multimodal generative capabilities of recent Multimodal Large Language Models (MLLMs), this work investigates a fundamental yet underexplored question: can MLLMs generate missing modalities for products in e-commerce scenarios? We propose the Missing Modality Product Completion Benchmark (MMPCBench), which consists of two sub-benchmarks: a Content Quality Completion Benchmark and a Recommendation Benchmark. We further evaluate six state-of-the-art MLLMs from the Qwen2.5-VL and Gemma-3 model families across nine real-world e-commerce categories, focusing on image-to-text and text-to-image completion tasks. Experimental results show that while MLLMs can capture high-level semantics, they struggle with fine-grained word-level and pixel- or patch-level alignment. In addition, performance varies substantially across product categories and model scales, and we observe no trivial correlation between model size and performance, in contrast to trends commonly reported in mainstream benchmarks. We also explore Group Relative Policy Optimization (GRPO) to better align MLLMs with this task. GRPO improves image-to-text completion but does not yield gains for text-to-image completion. Overall, these findings expose the limitations of current MLLMs in real-world cross-modal generation and represent an early step toward more effective missing-modality product completion.
Focal-RegionFace: Generating Fine-Grained Multi-attribute Descriptions for Arbitrarily Selected Face Focal Regions
Jan 01, 2026In this paper, we introduce an underexplored problem in facial analysis: generating and recognizing multi-attribute natural language descriptions, containing facial action units (AUs), emotional states, and age estimation, for arbitrarily selected face regions (termed FaceFocalDesc). We argue that the system's ability to focus on individual facial areas leads to better understanding and control. To achieve this capability, we construct a new multi-attribute description dataset for arbitrarily selected face regions, providing rich region-level annotations and natural language descriptions. Further, we propose a fine-tuned vision-language model based on Qwen2.5-VL, called Focal-RegionFace for facial state analysis, which incrementally refines its focus on localized facial features through multiple progressively fine-tuning stages, resulting in interpretable age estimation, FAU and emotion detection. Experimental results show that Focal-RegionFace achieves the best performance on the new benchmark in terms of traditional and widely used metrics, as well as new proposed metrics. This fully verifies its effectiveness and versatility in fine-grained multi-attribute face region-focal analysis scenarios.
Vidarc: Embodied Video Diffusion Model for Closed-loop Control
Dec 19, 2025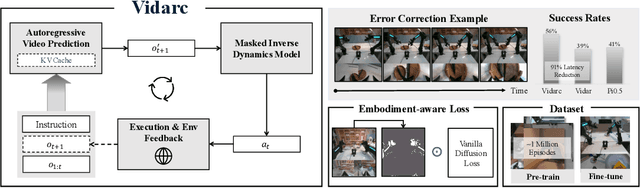
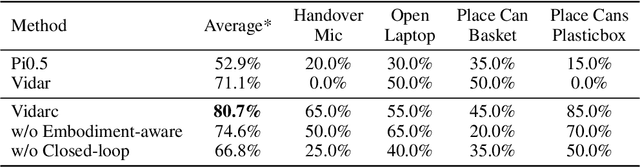
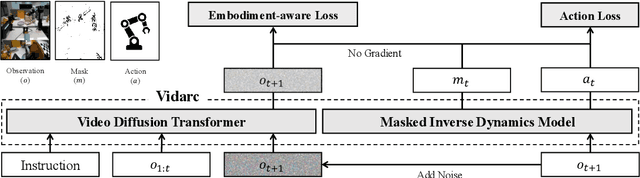
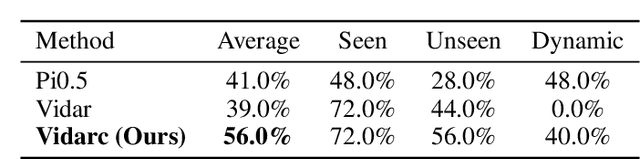
Robotic arm manipulation in data-scarce settings is a highly challenging task due to the complex embodiment dynamics and diverse contexts. Recent video-based approaches have shown great promise in capturing and transferring the temporal and physical interactions by pre-training on Internet-scale video data. However, such methods are often not optimized for the embodiment-specific closed-loop control, typically suffering from high latency and insufficient grounding. In this paper, we present Vidarc (Video Diffusion for Action Reasoning and Closed-loop Control), a novel autoregressive embodied video diffusion approach augmented by a masked inverse dynamics model. By grounding video predictions with action-relevant masks and incorporating real-time feedback through cached autoregressive generation, Vidarc achieves fast, accurate closed-loop control. Pre-trained on one million cross-embodiment episodes, Vidarc surpasses state-of-the-art baselines, achieving at least a 15% higher success rate in real-world deployment and a 91% reduction in latency. We also highlight its robust generalization and error correction capabilities across previously unseen robotic platforms.
TurboDiffusion: Accelerating Video Diffusion Models by 100-200 Times
Dec 18, 2025We introduce TurboDiffusion, a video generation acceleration framework that can speed up end-to-end diffusion generation by 100-200x while maintaining video quality. TurboDiffusion mainly relies on several components for acceleration: (1) Attention acceleration: TurboDiffusion uses low-bit SageAttention and trainable Sparse-Linear Attention (SLA) to speed up attention computation. (2) Step distillation: TurboDiffusion adopts rCM for efficient step distillation. (3) W8A8 quantization: TurboDiffusion quantizes model parameters and activations to 8 bits to accelerate linear layers and compress the model. In addition, TurboDiffusion incorporates several other engineering optimizations. We conduct experiments on the Wan2.2-I2V-14B-720P, Wan2.1-T2V-1.3B-480P, Wan2.1-T2V-14B-720P, and Wan2.1-T2V-14B-480P models. Experimental results show that TurboDiffusion achieves 100-200x speedup for video generation even on a single RTX 5090 GPU, while maintaining comparable video quality. The GitHub repository, which includes model checkpoints and easy-to-use code, is available at https://github.com/thu-ml/TurboDiffusion.
DiffusionNFT: Online Diffusion Reinforcement with Forward Process
Sep 19, 2025Online reinforcement learning (RL) has been central to post-training language models, but its extension to diffusion models remains challenging due to intractable likelihoods. Recent works discretize the reverse sampling process to enable GRPO-style training, yet they inherit fundamental drawbacks, including solver restrictions, forward-reverse inconsistency, and complicated integration with classifier-free guidance (CFG). We introduce Diffusion Negative-aware FineTuning (DiffusionNFT), a new online RL paradigm that optimizes diffusion models directly on the forward process via flow matching. DiffusionNFT contrasts positive and negative generations to define an implicit policy improvement direction, naturally incorporating reinforcement signals into the supervised learning objective. This formulation enables training with arbitrary black-box solvers, eliminates the need for likelihood estimation, and requires only clean images rather than sampling trajectories for policy optimization. DiffusionNFT is up to $25\times$ more efficient than FlowGRPO in head-to-head comparisons, while being CFG-free. For instance, DiffusionNFT improves the GenEval score from 0.24 to 0.98 within 1k steps, while FlowGRPO achieves 0.95 with over 5k steps and additional CFG employment. By leveraging multiple reward models, DiffusionNFT significantly boosts the performance of SD3.5-Medium in every benchmark tested.