 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Policy Evaluation with Video World Models
Nov 17, 2025Training generalist policies for robotic manipulation has shown great promise, as they enable language-conditioned, multi-task behaviors across diverse scenarios. However, evaluating these policies remains difficult because real-world testing is expensive, time-consuming, and labor-intensive. It also requires frequent environment resets and carries safety risks when deploying unproven policies on physical robots. Manually creating and populating simulation environments with assets for robotic manipulation has not addressed these issues, primarily due to the significant engineering effort required and the often substantial sim-to-real gap, both in terms of physics and rendering. In this paper, we explore the use of action-conditional video generation models as a scalable way to learn world models for policy evaluation. We demonstrate how to incorporate action conditioning into existing pre-trained video generation models. This allows leveraging internet-scale in-the-wild online videos during the pre-training stage, and alleviates the need for a large dataset of paired video-action data, which is expensive to collect for robotic manipulation. Our paper examines the effect of dataset diversity, pre-trained weight and common failure cases for the proposed evaluation pipeline. Our experiments demonstrate that, across various metrics, including policy ranking and the correlation between actual policy values and predicted policy values, these models offer a promising approach for evaluating policies without requiring real-world interactions.
Describe Anything: Detailed Localized Image and Video Captioning
Apr 22, 2025Generating detailed and accurate descriptions for specific regions in images and videos remains a fundamental challenge for vision-language models. We introduce the Describe Anything Model (DAM), a model designed for detailed localized captioning (DLC). DAM preserves both local details and global context through two key innovations: a focal prompt, which ensures high-resolution encoding of targeted regions, and a localized vision backbone, which integrates precise localization with its broader context. To tackle the scarcity of high-quality DLC data, we propose a Semi-supervised learning (SSL)-based Data Pipeline (DLC-SDP). DLC-SDP starts with existing segmentation datasets and expands to unlabeled web images using SSL. We introduce DLC-Bench, a benchmark designed to evaluate DLC without relying on reference captions. DAM sets new state-of-the-art on 7 benchmarks spanning keyword-level, phrase-level, and detailed multi-sentence localized image and video captioning.
Cosmos-Transfer1: Conditional World Generation with Adaptive Multimodal Control
Mar 18, 2025We introduce Cosmos-Transfer, a conditional world generation model that can generate world simulations based on multiple spatial control inputs of various modalities such as segmentation, depth, and edge. In the design, the spatial conditional scheme is adaptive and customizable. It allows weighting different conditional inputs differently at different spatial locations. This enables highly controllable world generation and finds use in various world-to-world transfer use cases, including Sim2Real. We conduct extensive evaluations to analyze the proposed model and demonstrate its applications for Physical AI, including robotics Sim2Real and autonomous vehicle data enrichment. We further demonstrate an inference scaling strategy to achieve real-time world generation with an NVIDIA GB200 NVL72 rack. To help accelerate research development in the field, we open-source our models and code at https://github.com/nvidia-cosmos/cosmos-transfer1.
Cosmos World Foundation Model Platform for Physical AI
Jan 07, 2025



Physical AI needs to be trained digitally first. It needs a digital twin of itself, the policy model, and a digital twin of the world, the world model. In this paper, we present the Cosmos World Foundation Model Platform to help developers build customized world models for their Physical AI setups. We position a world foundation model as a general-purpose world model that can be fine-tuned into customized world models for downstream applications. Our platform covers a video curation pipeline, pre-trained world foundation models, examples of post-training of pre-trained world foundation models, and video tokenizers. To help Physical AI builders solve the most critical problems of our society, we make our platform open-source and our models open-weight with permissive licenses available via https://github.com/NVIDIA/Cosmos.
Masked Diffusion Models are Secretly Time-Agnostic Masked Models and Exploit Inaccurate Categorical Sampling
Sep 04, 2024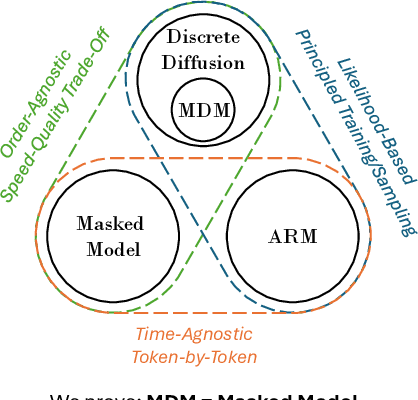

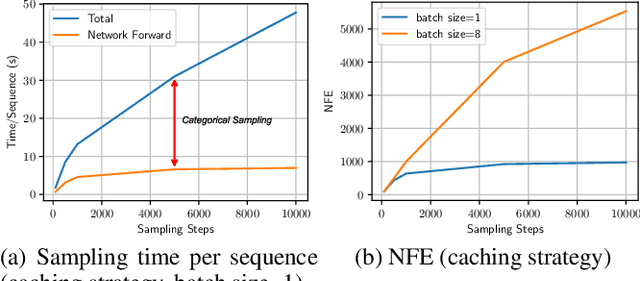

Masked diffusion models (MDMs) have emerged as a popular research topic for generative modeling of discrete data, thanks to their superior performance over other discrete diffusion models, and are rivaling the auto-regressive models (ARMs) for language modeling tasks. The recent effort in simplifying the masked diffusion framework further leads to alignment with continuous-space diffusion models and more principled training and sampling recipes. In this paper, however, we reveal that both training and sampling of MDMs are theoretically free from the time variable, arguably the key signature of diffusion models, and are instead equivalent to masked models. The connection on the sampling aspect is drawn by our proposed first-hitting sampler (FHS). Specifically, we show that the FHS is theoretically equivalent to MDMs' original generation process while significantly alleviating the time-consuming categorical sampling and achieving a 20$\times$ speedup. In addition, our investigation challenges previous claims that MDMs can surpass ARMs in generative perplexity. We identify, for the first time, an underlying numerical issue, even with the 32-bit floating-point precision, which results in inaccurate categorical sampling. We show that the numerical issue lowers the effective temperature both theoretically and empirically, leading to unfair assessments of MDMs' generation results in the previous literature.
Segment Anything
Apr 05, 2023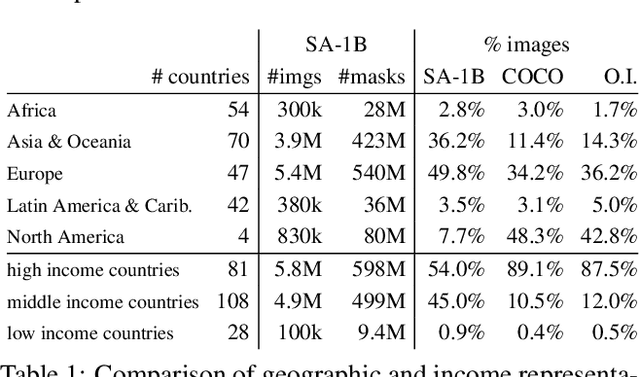

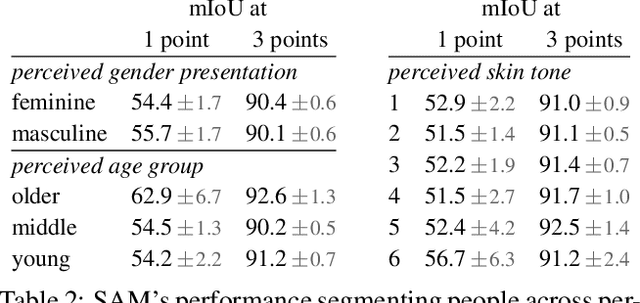

We introduce the Segment Anything (SA) project: a new task, model, and dataset for image segmentation. Using our efficient model in a data collection loop, we built the largest segmentation dataset to date (by far), with over 1 billion masks on 11M licensed and privacy respecting images. The model is designed and trained to be promptable, so it can transfer zero-shot to new image distributions and tasks. We evaluate its capabilities on numerous tasks and find that its zero-shot performance is impressive -- often competitive with or even superior to prior fully supervised results. We are releasing the Segment Anything Model (SAM) and corresponding dataset (SA-1B) of 1B masks and 11M images at https://segment-anything.com to foster research into foundation models for computer vision.
Exploring Plain Vision Transformer Backbones for Object Detection
Mar 30, 2022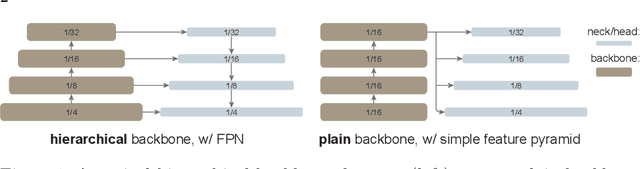



We explore the plain, non-hierarchical Vision Transformer (ViT) as a backbone network for object detection. This design enables the original ViT architecture to be fine-tuned for object detection without needing to redesign a hierarchical backbone for pre-training. With minimal adaptations for fine-tuning, our plain-backbone detector can achieve competitive results. Surprisingly, we observe: (i) it is sufficient to build a simple feature pyramid from a single-scale feature map (without the common FPN design) and (ii) it is sufficient to use window attention (without shifting) aided with very few cross-window propagation blocks. With plain ViT backbones pre-trained as Masked Autoencoders (MAE), our detector, named ViTDet, can compete with the previous leading methods that were all based on hierarchical backbones, reaching up to 61.3 box AP on the COCO dataset using only ImageNet-1K pre-training. We hope our study will draw attention to research on plain-backbone detectors. Code will be made available.
A ConvNet for the 2020s
Jan 10, 2022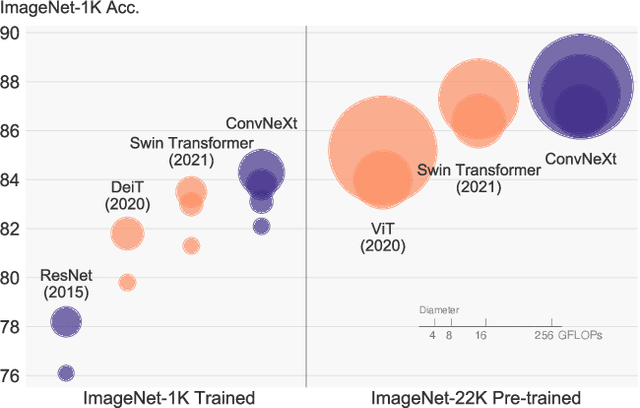
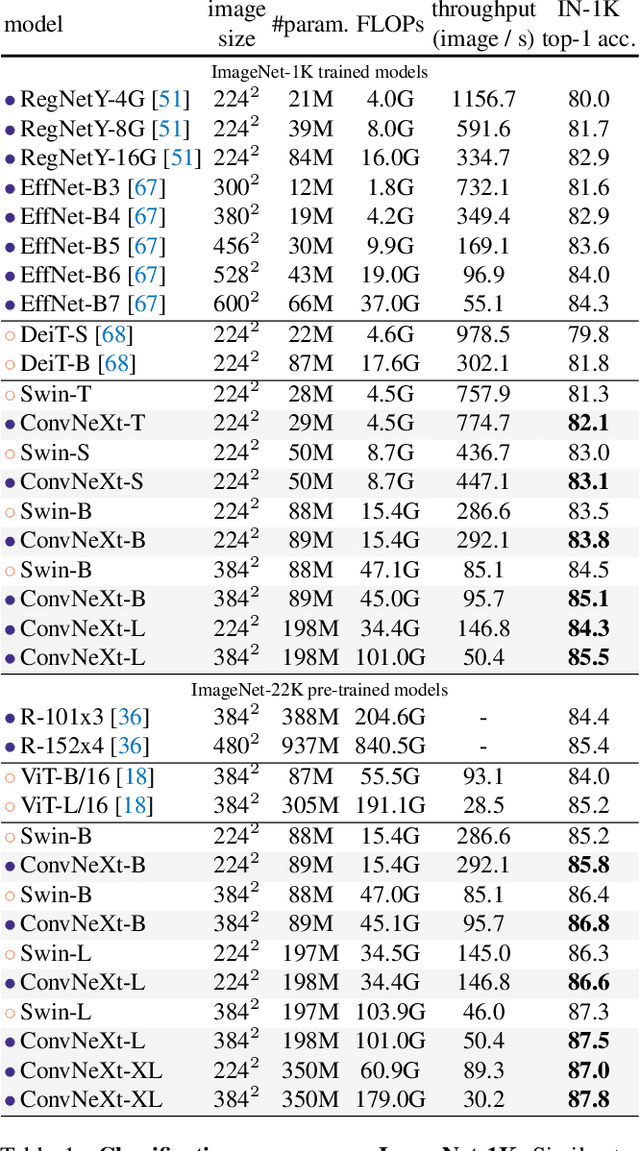
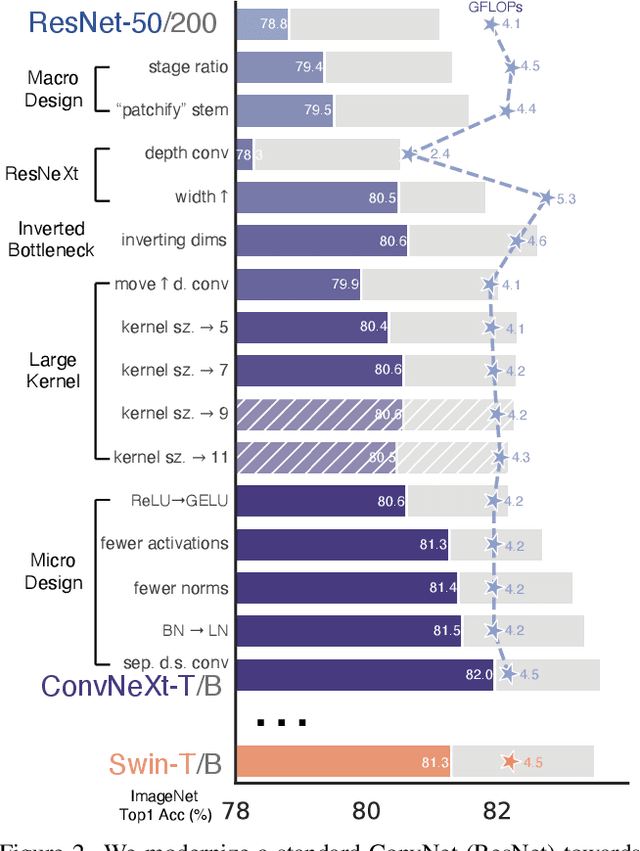
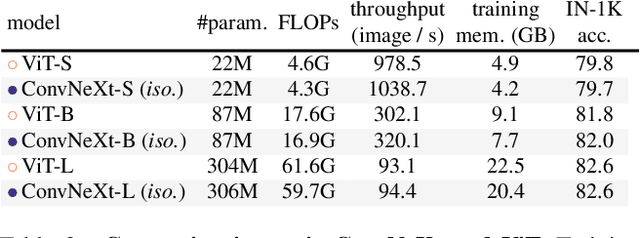
The "Roaring 20s" of visual recognition began with the introduction of Vision Transformers (ViTs), which quickly superseded ConvNets as the state-of-the-art image classification model. A vanilla ViT, on the other hand, faces difficulties when applied to general computer vision tasks such as object detection and semantic segmentation. It is the hierarchical Transformers (e.g., Swin Transformers) that reintroduced several ConvNet priors, making Transformers practically viable as a generic vision backbone and demonstrating remarkable performance on a wide variety of vision tasks. However, the effectiveness of such hybrid approaches is still largely credited to the intrinsic superiority of Transformers, rather than the inherent inductive biases of convolutions. In this work, we reexamine the design spaces and test the limits of what a pure ConvNet can achieve. We gradually "modernize" a standard ResNet toward the design of a vision Transformer, and discover several key components that contribute to the performance difference along the way. The outcome of this exploration is a family of pure ConvNet models dubbed ConvNeXt. Constructed entirely from standard ConvNet modules, ConvNeXts compete favorably with Transformers in terms of accuracy and scalability, achieving 87.8% ImageNet top-1 accuracy and outperforming Swin Transformers on COCO detection and ADE20K segmentation, while maintaining the simplicity and efficiency of standard ConvNets.
Entailment as Few-Shot Learner
Apr 29, 2021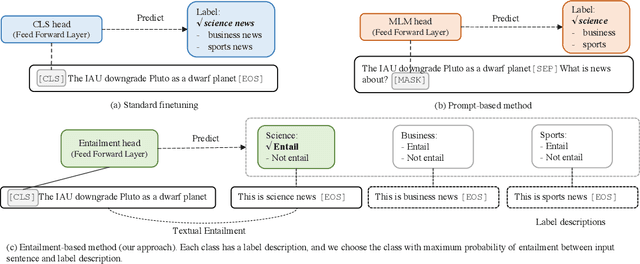

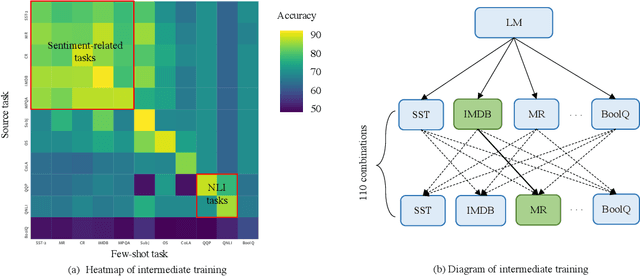
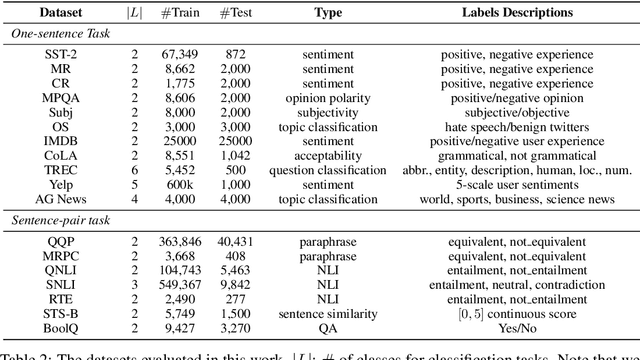
Large pre-trained language models (LMs) have demonstrated remarkable ability as few-shot learners. However, their success hinges largely on scaling model parameters to a degree that makes it challenging to train and serve. In this paper, we propose a new approach, named as EFL, that can turn small LMs into better few-shot learners. The key idea of this approach is to reformulate potential NLP task into an entailment one, and then fine-tune the model with as little as 8 examples. We further demonstrate our proposed method can be: (i) naturally combined with an unsupervised contrastive learning-based data augmentation method; (ii) easily extended to multilingual few-shot learning. A systematic evaluation on 18 standard NLP tasks demonstrates that this approach improves the various existing SOTA few-shot learning methods by 12\%, and yields competitive few-shot performance with 500 times larger models, such as GPT-3.