 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData reuse enables cost-efficient randomized trials of medical AI models
Nov 13, 2025Randomized controlled trials (RCTs) are indispensable for establishing the clinical value of medical artificial-intelligence (AI) tools, yet their high cost and long timelines hinder timely validation as new models emerge rapidly. Here, we propose BRIDGE, a data-reuse RCT design for AI-based risk models. AI risk models support a broad range of interventions, including screening, treatment selection, and clinical alerts. BRIDGE trials recycle participant-level data from completed trials of AI models when legacy and updated models make concordant predictions, thereby reducing the enrollment requirement for subsequent trials. We provide a practical checklist for investigators to assess whether reusing data from previous trials allows for valid causal inference and preserves type I error. Using real-world datasets across breast cancer, cardiovascular disease, and sepsis, we demonstrate concordance between successive AI models, with up to 64.8% overlap in top 5% high-risk cohorts. We then simulate a series of breast cancer screening studies, where our design reduced required enrollment by 46.6%--saving over US$2.8 million--while maintaining 80% power. By transforming trials into adaptive, modular studies, our proposed design makes Level I evidence generation feasible for every model iteration, thereby accelerating cost-effective translation of AI into routine care.
Describe Anything: Detailed Localized Image and Video Captioning
Apr 22, 2025Generating detailed and accurate descriptions for specific regions in images and videos remains a fundamental challenge for vision-language models. We introduce the Describe Anything Model (DAM), a model designed for detailed localized captioning (DLC). DAM preserves both local details and global context through two key innovations: a focal prompt, which ensures high-resolution encoding of targeted regions, and a localized vision backbone, which integrates precise localization with its broader context. To tackle the scarcity of high-quality DLC data, we propose a Semi-supervised learning (SSL)-based Data Pipeline (DLC-SDP). DLC-SDP starts with existing segmentation datasets and expands to unlabeled web images using SSL. We introduce DLC-Bench, a benchmark designed to evaluate DLC without relying on reference captions. DAM sets new state-of-the-art on 7 benchmarks spanning keyword-level, phrase-level, and detailed multi-sentence localized image and video captioning.
Learning Adaptive Parallel Reasoning with Language Models
Apr 21, 2025Scaling inference-time computation has substantially improved the reasoning capabilities of language models. However, existing methods have significant limitations: serialized chain-of-thought approaches generate overly long outputs, leading to increased latency and exhausted context windows, while parallel methods such as self-consistency suffer from insufficient coordination, resulting in redundant computations and limited performance gains. To address these shortcomings, we propose Adaptive Parallel Reasoning (APR), a novel reasoning framework that enables language models to orchestrate both serialized and parallel computations end-to-end. APR generalizes existing reasoning methods by enabling adaptive multi-threaded inference using spawn() and join() operations. A key innovation is our end-to-end reinforcement learning strategy, optimizing both parent and child inference threads to enhance task success rate without requiring predefined reasoning structures. Experiments on the Countdown reasoning task demonstrate significant benefits of APR: (1) higher performance within the same context window (83.4% vs. 60.0% at 4k context); (2) superior scalability with increased computation (80.1% vs. 66.6% at 20k total tokens); (3) improved accuracy at equivalent latency (75.2% vs. 57.3% at approximately 5,000ms). APR represents a step towards enabling language models to autonomously optimize their reasoning processes through adaptive allocation of computation.
TULIP: Towards Unified Language-Image Pretraining
Mar 19, 2025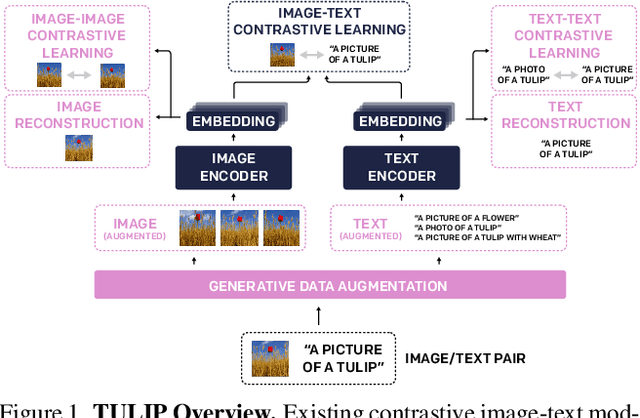
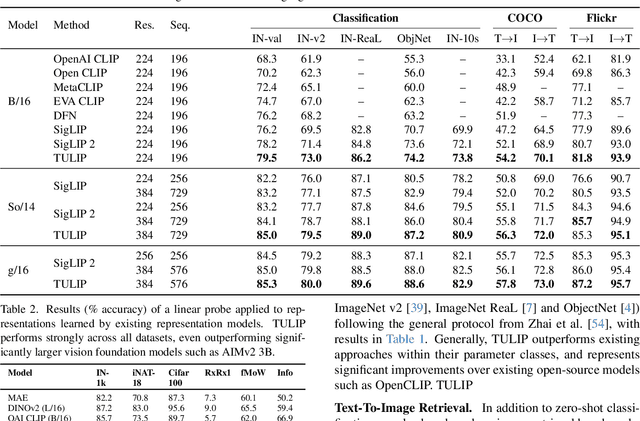
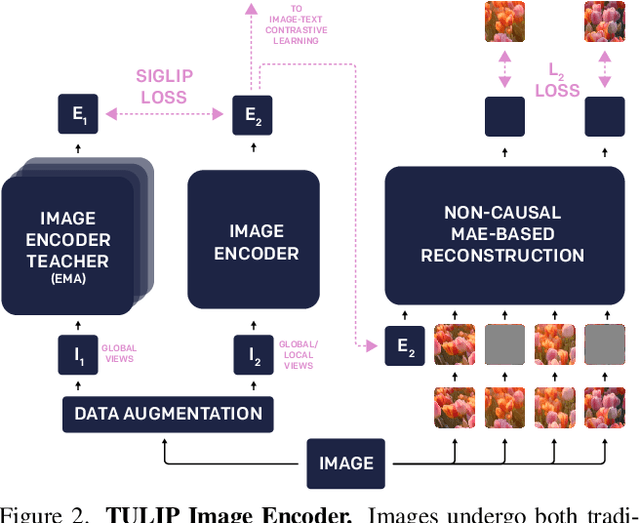
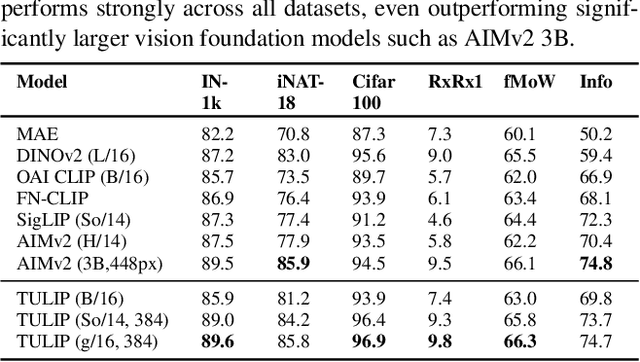
Despite the recent success of image-text contrastive models like CLIP and SigLIP, these models often struggle with vision-centric tasks that demand high-fidelity image understanding, such as counting, depth estimation, and fine-grained object recognition. These models, by performing language alignment, tend to prioritize high-level semantics over visual understanding, weakening their image understanding. On the other hand, vision-focused models are great at processing visual information but struggle to understand language, limiting their flexibility for language-driven tasks. In this work, we introduce TULIP, an open-source, drop-in replacement for existing CLIP-like models. Our method leverages generative data augmentation, enhanced image-image and text-text contrastive learning, and image/text reconstruction regularization to learn fine-grained visual features while preserving global semantic alignment. Our approach, scaling to over 1B parameters, outperforms existing state-of-the-art (SOTA) models across multiple benchmarks, establishing a new SOTA zero-shot performance on ImageNet-1K, delivering up to a $2\times$ enhancement over SigLIP on RxRx1 in linear probing for few-shot classification, and improving vision-language models, achieving over $3\times$ higher scores than SigLIP on MMVP. Our code/checkpoints are available at https://tulip-berkeley.github.io
Atlas: Multi-Scale Attention Improves Long Context Image Modeling
Mar 16, 2025Efficiently modeling massive images is a long-standing challenge in machine learning. To this end, we introduce Multi-Scale Attention (MSA). MSA relies on two key ideas, (i) multi-scale representations (ii) bi-directional cross-scale communication. MSA creates O(log N) scales to represent the image across progressively coarser features and leverages cross-attention to propagate information across scales. We then introduce Atlas, a novel neural network architecture based on MSA. We demonstrate that Atlas significantly improves the compute-performance tradeoff of long-context image modeling in a high-resolution variant of ImageNet 100. At 1024px resolution, Atlas-B achieves 91.04% accuracy, comparable to ConvNext-B (91.92%) while being 4.3x faster. Atlas is 2.95x faster and 7.38% better than FasterViT, 2.25x faster and 4.96% better than LongViT. In comparisons against MambaVision-S, we find Atlas-S achieves 5%, 16% and 32% higher accuracy at 1024px, 2048px and 4096px respectively, while obtaining similar runtimes. Code for reproducing our experiments and pretrained models is available at https://github.com/yalalab/atlas.
Rethinking Patch Dependence for Masked Autoencoders
Jan 25, 2024



In this work, we re-examine inter-patch dependencies in the decoding mechanism of masked autoencoders (MAE). We decompose this decoding mechanism for masked patch reconstruction in MAE into self-attention and cross-attention. Our investigations suggest that self-attention between mask patches is not essential for learning good representations. To this end, we propose a novel pretraining framework: Cross-Attention Masked Autoencoders (CrossMAE). CrossMAE's decoder leverages only cross-attention between masked and visible tokens, with no degradation in downstream performance. This design also enables decoding only a small subset of mask tokens, boosting efficiency. Furthermore, each decoder block can now leverage different encoder features, resulting in improved representation learning. CrossMAE matches MAE in performance with 2.5 to 3.7$\times$ less decoding compute. It also surpasses MAE on ImageNet classification and COCO instance segmentation under the same compute. Code and models: https://crossmae.github.io
LLM-grounded Video Diffusion Models
Oct 02, 2023Text-conditioned diffusion models have emerged as a promising tool for neural video generation. However, current models still struggle with intricate spatiotemporal prompts and often generate restricted or incorrect motion (e.g., even lacking the ability to be prompted for objects moving from left to right). To address these limitations, we introduce LLM-grounded Video Diffusion (LVD). Instead of directly generating videos from the text inputs, LVD first leverages a large language model (LLM) to generate dynamic scene layouts based on the text inputs and subsequently uses the generated layouts to guide a diffusion model for video generation. We show that LLMs are able to understand complex spatiotemporal dynamics from text alone and generate layouts that align closely with both the prompts and the object motion patterns typically observed in the real world. We then propose to guide video diffusion models with these layouts by adjusting the attention maps. Our approach is training-free and can be integrated into any video diffusion model that admits classifier guidance. Our results demonstrate that LVD significantly outperforms its base video diffusion model and several strong baseline methods in faithfully generating videos with the desired attributes and motion patterns.
Conformal Language Modeling
Jun 16, 2023We propose a novel approach to conformal prediction for generative language models (LMs). Standard conformal prediction produces prediction sets -- in place of single predictions -- that have rigorous, statistical performance guarantees. LM responses are typically sampled from the model's predicted distribution over the large, combinatorial output space of natural language. Translating this process to conformal prediction, we calibrate a stopping rule for sampling different outputs from the LM that get added to a growing set of candidates until we are confident that the output set is sufficient. Since some samples may be low-quality, we also simultaneously calibrate and apply a rejection rule for removing candidates from the output set to reduce noise. Similar to conformal prediction, we prove that the sampled set returned by our procedure contains at least one acceptable answer with high probability, while still being empirically precise (i.e., small) on average. Furthermore, within this set of candidate responses, we show that we can also accurately identify subsets of individual components -- such as phrases or sentences -- that are each independently correct (e.g., that are not "hallucinations"), again with statistical guarantees. We demonstrate the promise of our approach on multiple tasks in open-domain question answering, text summarization, and radiology report generation using different LM variants.
LLM-grounded Diffusion: Enhancing Prompt Understanding of Text-to-Image Diffusion Models with Large Language Models
May 23, 2023



Recent advancements in text-to-image generation with diffusion models have yielded remarkable results synthesizing highly realistic and diverse images. However, these models still encounter difficulties when generating images from prompts that demand spatial or common sense reasoning. We propose to equip diffusion models with enhanced reasoning capabilities by using off-the-shelf pretrained large language models (LLMs) in a novel two-stage generation process. First, we adapt an LLM to be a text-guided layout generator through in-context learning. When provided with an image prompt, an LLM outputs a scene layout in the form of bounding boxes along with corresponding individual descriptions. Second, we steer a diffusion model with a novel controller to generate images conditioned on the layout. Both stages utilize frozen pretrained models without any LLM or diffusion model parameter optimization. We validate the superiority of our design by demonstrating its ability to outperform the base diffusion model in accurately generating images according to prompts that necessitate both language and spatial reasoning. Additionally, our method naturally allows dialog-based scene specification and is able to handle prompts in a language that is not well-supported by the underlying diffusion model.
PEOPL: Characterizing Privately Encoded Open Datasets with Public Labels
Mar 31, 2023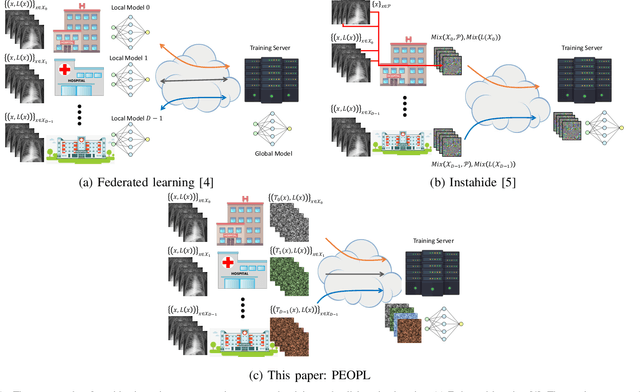

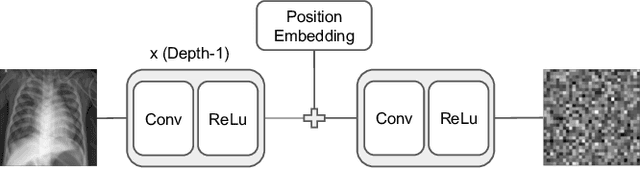

Allowing organizations to share their data for training of machine learning (ML) models without unintended information leakage is an open problem in practice. A promising technique for this still-open problem is to train models on the encoded data. Our approach, called Privately Encoded Open Datasets with Public Labels (PEOPL), uses a certain class of randomly constructed transforms to encode sensitive data. Organizations publish their randomly encoded data and associated raw labels for ML training, where training is done without knowledge of the encoding realization. We investigate several important aspects of this problem: We introduce information-theoretic scores for privacy and utility, which quantify the average performance of an unfaithful user (e.g., adversary) and a faithful user (e.g., model developer) that have access to the published encoded data. We then theoretically characterize primitives in building families of encoding schemes that motivate the use of random deep neural networks. Empirically, we compare the performance of our randomized encoding scheme and a linear scheme to a suite of computational attacks, and we also show that our scheme achieves competitive prediction accuracy to raw-sample baselines. Moreover, we demonstrate that multiple institutions, using independent random encoders, can collaborate to train improved ML models.