 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLTCP: Congestion Control for DNN Training
Feb 14, 2024We present MLTCP, a technique to augment today's congestion control algorithms to accelerate DNN training jobs in shared GPU clusters. MLTCP enables the communication phases of jobs that compete for network bandwidth to interleave with each other, thereby utilizing the network efficiently. At the heart of MLTCP lies a very simple principle based on a key conceptual insight: DNN training flows should scale their congestion window size based on the number of bytes sent at each training iteration. We show that integrating this principle into today's congestion control protocols is straightforward: by adding 30-60 lines of code to Reno, CUBIC, or DCQCN, MLTCP stabilizes flows of different jobs into an interleaved state within a few training iterations, regardless of the number of competing flows or the start time of each flow. Our experiments with popular DNN training jobs demonstrate that enabling MLTCP accelerates the average and 99th percentile training iteration time by up to 2x and 4x, respectively.
CASSINI: Network-Aware Job Scheduling in Machine Learning Clusters
Aug 01, 2023

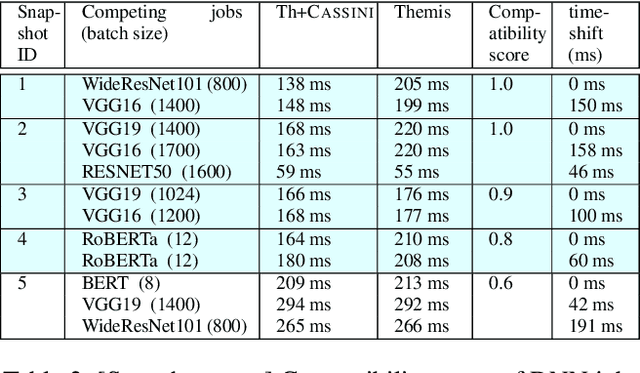

We present CASSINI, a network-aware job scheduler for machine learning (ML) clusters. CASSINI introduces a novel geometric abstraction to consider the communication pattern of different jobs while placing them on network links. To do so, CASSINI uses an affinity graph that finds a series of time-shift values to adjust the communication phases of a subset of jobs, such that the communication patterns of jobs sharing the same network link are interleaved with each other. Experiments with 13 common ML models on a 24-server testbed demonstrate that compared to the state-of-the-art ML schedulers, CASSINI improves the average and tail completion time of jobs by up to 1.6x and 2.5x, respectively. Moreover, we show that CASSINI reduces the number of ECN marked packets in the cluster by up to 33x.
Optimized Network Architectures for Large Language Model Training with Billions of Parameters
Jul 22, 2023



This paper challenges the well-established paradigm for building any-to-any networks for training Large Language Models (LLMs). We show that LLMs exhibit a unique communication pattern where only small groups of GPUs require high-bandwidth any-to-any communication within them, to achieve near-optimal training performance. Across these groups of GPUs, the communication is insignificant, sparse, and homogeneous. We propose a new network architecture that closely resembles the communication requirement of LLMs. Our architecture partitions the cluster into sets of GPUs interconnected with non-blocking any-to-any high-bandwidth interconnects that we call HB domains. Across the HB domains, the network only connects GPUs with communication demands. We call this network a "rail-only" connection, and show that our proposed architecture reduces the network cost by up to 75% compared to the state-of-the-art any-to-any Clos networks without compromising the performance of LLM training.
PEOPL: Characterizing Privately Encoded Open Datasets with Public Labels
Mar 31, 2023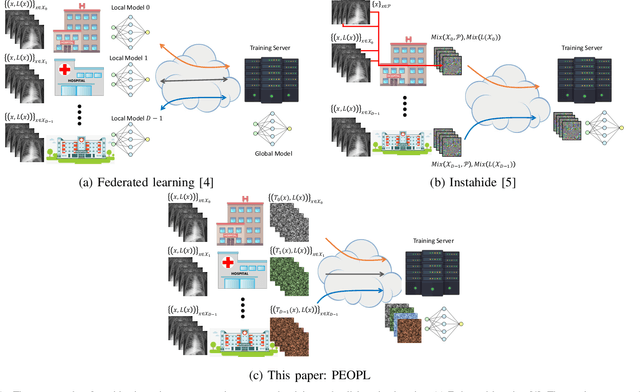

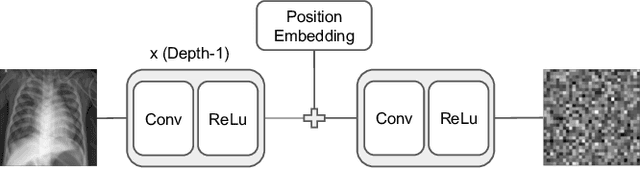

Allowing organizations to share their data for training of machine learning (ML) models without unintended information leakage is an open problem in practice. A promising technique for this still-open problem is to train models on the encoded data. Our approach, called Privately Encoded Open Datasets with Public Labels (PEOPL), uses a certain class of randomly constructed transforms to encode sensitive data. Organizations publish their randomly encoded data and associated raw labels for ML training, where training is done without knowledge of the encoding realization. We investigate several important aspects of this problem: We introduce information-theoretic scores for privacy and utility, which quantify the average performance of an unfaithful user (e.g., adversary) and a faithful user (e.g., model developer) that have access to the published encoded data. We then theoretically characterize primitives in building families of encoding schemes that motivate the use of random deep neural networks. Empirically, we compare the performance of our randomized encoding scheme and a linear scheme to a suite of computational attacks, and we also show that our scheme achieves competitive prediction accuracy to raw-sample baselines. Moreover, we demonstrate that multiple institutions, using independent random encoders, can collaborate to train improved ML models.
NeuraCrypt: Hiding Private Health Data via Random Neural Networks for Public Training
Jun 04, 2021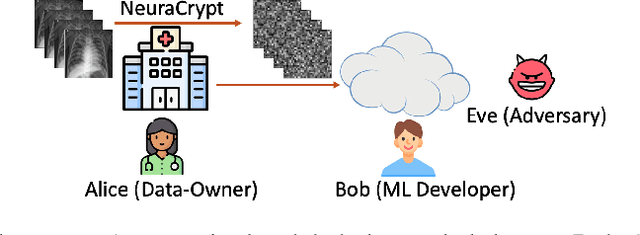
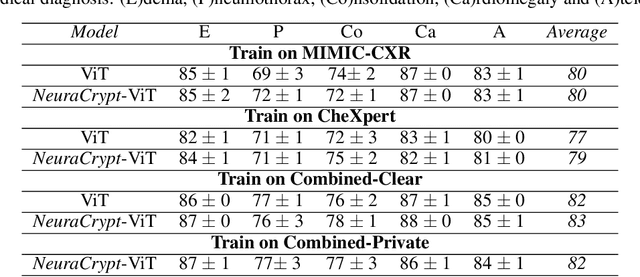
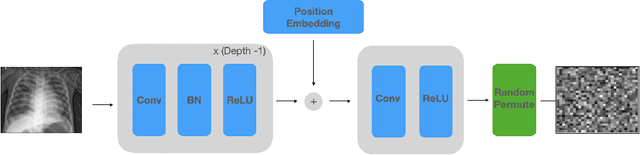

Balancing the needs of data privacy and predictive utility is a central challenge for machine learning in healthcare. In particular, privacy concerns have led to a dearth of public datasets, complicated the construction of multi-hospital cohorts and limited the utilization of external machine learning resources. To remedy this, new methods are required to enable data owners, such as hospitals, to share their datasets publicly, while preserving both patient privacy and modeling utility. We propose NeuraCrypt, a private encoding scheme based on random deep neural networks. NeuraCrypt encodes raw patient data using a randomly constructed neural network known only to the data-owner, and publishes both the encoded data and associated labels publicly. From a theoretical perspective, we demonstrate that sampling from a sufficiently rich family of encoding functions offers a well-defined and meaningful notion of privacy against a computationally unbounded adversary with full knowledge of the underlying data-distribution. We propose to approximate this family of encoding functions through random deep neural networks. Empirically, we demonstrate the robustness of our encoding to a suite of adversarial attacks and show that NeuraCrypt achieves competitive accuracy to non-private baselines on a variety of x-ray tasks. Moreover, we demonstrate that multiple hospitals, using independent private encoders, can collaborate to train improved x-ray models. Finally, we release a challenge dataset to encourage the development of new attacks on NeuraCrypt.