 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLTCP: Congestion Control for DNN Training
Feb 14, 2024We present MLTCP, a technique to augment today's congestion control algorithms to accelerate DNN training jobs in shared GPU clusters. MLTCP enables the communication phases of jobs that compete for network bandwidth to interleave with each other, thereby utilizing the network efficiently. At the heart of MLTCP lies a very simple principle based on a key conceptual insight: DNN training flows should scale their congestion window size based on the number of bytes sent at each training iteration. We show that integrating this principle into today's congestion control protocols is straightforward: by adding 30-60 lines of code to Reno, CUBIC, or DCQCN, MLTCP stabilizes flows of different jobs into an interleaved state within a few training iterations, regardless of the number of competing flows or the start time of each flow. Our experiments with popular DNN training jobs demonstrate that enabling MLTCP accelerates the average and 99th percentile training iteration time by up to 2x and 4x, respectively.
CASSINI: Network-Aware Job Scheduling in Machine Learning Clusters
Aug 01, 2023

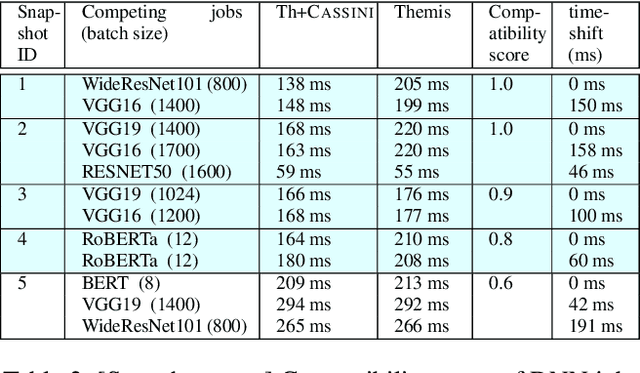

We present CASSINI, a network-aware job scheduler for machine learning (ML) clusters. CASSINI introduces a novel geometric abstraction to consider the communication pattern of different jobs while placing them on network links. To do so, CASSINI uses an affinity graph that finds a series of time-shift values to adjust the communication phases of a subset of jobs, such that the communication patterns of jobs sharing the same network link are interleaved with each other. Experiments with 13 common ML models on a 24-server testbed demonstrate that compared to the state-of-the-art ML schedulers, CASSINI improves the average and tail completion time of jobs by up to 1.6x and 2.5x, respectively. Moreover, we show that CASSINI reduces the number of ECN marked packets in the cluster by up to 33x.